Por que a camada de significado — não o modelo, não a ferramenta — vai decidir quais organizações conseguem escalar IA agêntica com confiança
triggo.ai · Data & AI Product Management
Parte I
I
O Problema que os Modelos Não Resolvem
Por que a maturidade em IA agêntica revela um teto invisível — e por que esse teto não é resolvido com modelos maiores nem com mais ferramentas.
Por que você precisa ler este e-book
Enterprise Context é o Elo que Faltava — e Sempre Faltou
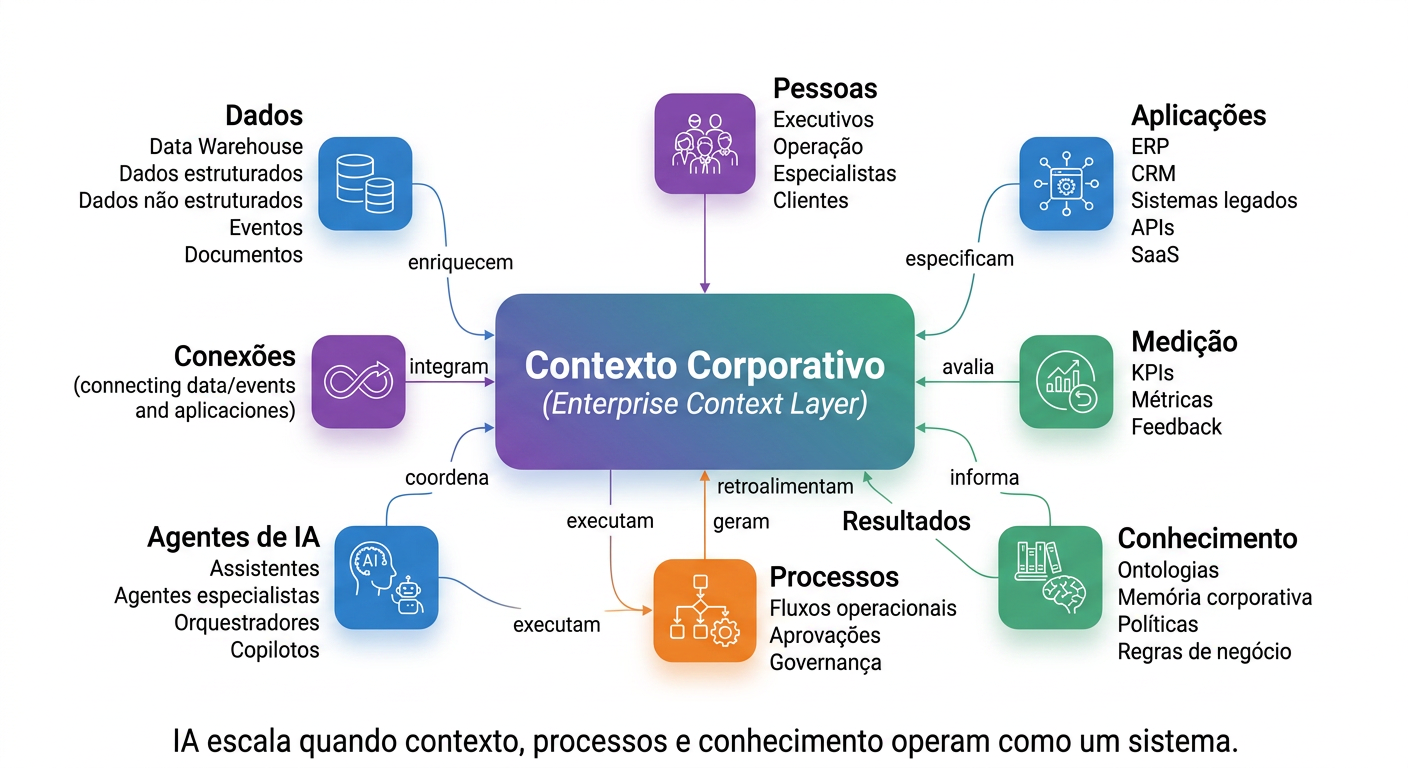
Antes de qualquer argumento, qualquer dado, qualquer caso de uso: olhe para o diagrama abaixo. Ele sintetiza, em um único mapa, o problema que este relatório vai destrinchar. No centro — Enterprise Context. Ao redor, tudo que uma empresa é: suas memórias institucionais, suas metas e OKRs, seus produtos e clientes, seus processos e ferramentas, seus agentes de IA já em operação, suas decisões passadas, seus dados, suas aplicações, suas pessoas. Tudo conectado. Tudo interdependente.
Agora a pergunta que importa: quantos dos seus agentes de IA, hoje, têm acesso a tudo isso de forma integrada, confiável e consultável? Se a resposta não for "todos eles, com consistência e governança", você está lendo o relatório certo.
Por que você precisa ler este e-book agora
Se você nunca implantou um agente em produção, este relatório vai te poupar de repetir os erros que já custaram caro a quem foi antes — e vai te ajudar a construir, desde o início, a fundação que mais tarde fará diferença.
Se você já tem agentes em produção e não está vendo consistência nos resultados — respostas que variam entre agentes, números que não batem, usuários que param de confiar na IA — este relatório nomeia o problema que você está vivendo e descreve o caminho de volta.
Se você está no board ou na liderança executiva acompanhando os investimentos em IA sem conseguir explicar por que o ROI não aparece apesar do esforço, este relatório conecta a causa estrutural ao sintoma financeiro — e mostra que a solução não está no próximo modelo de linguagem, mas numa camada de fundação que sua empresa provavelmente ainda não construiu.
A próxima onda de IA já chegou. A diferença entre quem vai surfá-la e quem vai ser arrastado não está no tamanho do investimento em ferramentas — está na profundidade do investimento em significado. Esse é o tema deste relatório.
A história que nos trouxe até aqui
Abertura
A Máscara que Sempre Existiu — e Que Acabou de Cair
Há mais de duas décadas o discurso corporativo repete a mesma promessa: dados são o ativo mais valioso da empresa, decisões precisam ser guiadas por evidência, e cada nova onda de tecnologia analítica vai finalmente entregar essa promessa. Já vimos essa água passar várias vezes. O Business Intelligence prometeu dashboards que substituiriam o achismo por fato. O Analytics e o Advanced Analytics prometeram ir além do "o que aconteceu" para o "por que aconteceu" e "o que vai acontecer". O Machine Learning prometeu decisões automatizadas em escala. Agora a IA Generativa e os agentes autônomos prometem eliminar de vez a fricção entre pergunta e resposta, entre intenção e ação.
Em cada uma dessas ondas, o discurso técnico foi essencialmente o mesmo: precisamos de mais significado, mais qualidade e mais confiança nos dados para que a promessa se cumpra. E em cada uma dessas ondas, por baixo do otimismo das conferências e dos cases de sucesso cuidadosamente selecionados, uma realidade incômoda persistiu silenciosamente: a maior parte do investimento nunca chegou a gerar valor proporcional.
60–70%
dos dashboards corporativos de BI acabam abandonados sem uso recorrente (Gartner)
~75%
dos funcionários com acesso a ferramentas de BI simplesmente não as utiliza no dia a dia
87–90%
dos modelos de Machine Learning construídos nunca chegam a entrar em produção
Esses números não são novos, e essa é exatamente a questão. Eles circulam há anos em pesquisas de mercado, em relatórios de analistas, em conversas de corredor entre profissionais de dados — e, ainda assim, raramente provocaram uma reação proporcional ao seu tamanho. Por quê?
Porque, até agora, a ineficiência analítica não custava caro o suficiente para ser confrontada
A resposta é mais estrutural do que técnica. Durante a era do BI, do Analytics e mesmo da primeira onda de Machine Learning, a maioria das empresas, na prática, não era data-driven — independentemente do que diziam seus relatórios anuais e suas declarações de missão. As decisões mais importantes continuavam sendo tomadas majoritariamente por experiência, relacionamento e intuição executiva, com os dados entrando como suporte ilustrativo, não como insumo decisório central.
E quando os dados não são, de fato, o centro da decisão, a ineficiência analítica se torna um problema tolerável. Um dashboard que ninguém usa é um desperdício orçamentário incômodo, mas não compromete a operação. Um modelo de Machine Learning que nunca sai do laboratório de dados é uma frustração da equipe técnica, mas raramente é hot topic na mesa do conselho. Ninguém precisava justificar, com rigor, o retorno de cada investimento em dados e análise — porque a função desses investimentos era, em grande medida, simbólica: sinalizar modernidade, não necessariamente sustentar decisão crítica.
"A máscara nunca escondeu a ineficiência por completo — apenas garantiu que ninguém precisasse olhar para ela de perto. Bastava que a empresa parecesse data-driven o suficiente para a próxima reunião de board."
— triggo.ai · Data & AI Product Management
O que quebrou esse filtro de tolerância
Três movimentos simultâneos, que se reforçam mutuamente, romperam essa zona de conforto de uma vez por todas.
🌐
Democratização massiva
O acesso a IA generativa deixou de ser privilégio de equipes técnicas especializadas. Qualquer colaborador, em qualquer função, pode hoje gerar uma análise, escrever uma consulta em linguagem natural ou acionar um agente — o que multiplicou exponencialmente o número de pessoas expostas diretamente à qualidade (ou à falta dela) dos dados subjacentes.
📋
A agenda executiva mudou de posição
IA deixou de ser pauta de TI e se tornou pauta permanente de conselho e diretoria. Investimento em IA agora é escrutinado com o mesmo rigor financeiro de qualquer outra linha de capital — e isso significa que cada real investido em dados e modelos precisa, finalmente, mostrar retorno explícito.
⚡
A janela de disrupção nunca esteve tão aberta
O potencial de inovação e ruptura competitiva habilitado por IA atingiu um patamar sem precedentes recentes — o que significa que o custo de oportunidade de operar com dados ruins não é mais "ficar igual à concorrência", é "ficar irreversivelmente para trás" dela.
O resultado é que a mesma estrutura analítica que sempre existiu — com seus dashboards esquecidos e seus modelos que nunca saíram do laboratório — está agora sendo somada a uma avalanche de iniciativas de IA que se espalham por toda a empresa, sob atenção executiva máxima e com expectativa de retorno imediato. Essa combinação exige um nível de maturidade que a maioria das organizações simplesmente nunca precisou demonstrar antes. E é exatamente isso que está expondo, com uma nitidez nova e desconfortável, uma ineficiência que sempre esteve lá — só que, até agora, ninguém era obrigado a olhar de frente para ela.
O ponto central deste relatório
Não dá mais para esconder a ineficiência atrás de um dashboard bonito ou de uma demonstração de produto bem ensaiada. O mercado já está cobrando valor real pelo hype investido — e essa cobrança vai se intensificar, não recuar. É exatamente nesse contexto que a camada de ontologia e contexto deixa de ser um tópico técnico de nicho e passa a ser a fundação estrutural que decide quais organizações conseguem, finalmente, transformar décadas de promessas analíticas em resultado consistente — e quais vão repetir, com agentes de IA, o mesmo padrão de abandono que já se repetiu com dashboards e modelos de Machine Learning.
O retrato atual
Capítulo 1.1
A Divisão que os Números Escondem
Em 2026, o ecossistema de IA corporativa já não discute se vai adotar agentes — discute por que a adoção não está virando resultado. Levantamentos recentes mostram que cerca de 80% das aplicações corporativas lançadas ou atualizadas no primeiro trimestre do ano já embarcam ao menos um agente de IA, um salto expressivo frente aos cerca de 33% registrados apenas dois anos antes. A curva de adoção é, segundo analistas, mais íngreme que qualquer outra onda de tecnologia corporativa desde a migração para nuvem no início dos anos 2010.
O problema aparece quando se olha não para adoção, mas para resultado sustentado. Pesquisa recente sobre maturidade de IA agêntica mostra que, apesar dos chamados "super-usuários" relatarem ganhos de produtividade da ordem de cinco vezes em tarefas individuais, apenas cerca de 29% das organizações reportam ROI significativo com IA generativa — e esse número cai para 23% quando o recorte é especificamente sobre agentes autônomos. A diferença entre o ganho individual, real e mensurável, e o resultado organizacional, ainda elusivo na maioria dos casos, é exatamente o sintoma que este relatório investiga: não falta capacidade técnica — falta a camada estrutural que transforma capacidade individual em resultado coordenado.
"O problema não está na inteligência do modelo nem na vontade de adotar. Está na ausência de uma camada que diga a cada agente, de forma consistente, o que as coisas significam dentro daquela organização específica."
— triggo.ai, síntese de pesquisa setorial sobre maturidade de IA agêntica (2026)
Esse padrão de "adoção alta, produção concentrada" se confirma em levantamentos cruzados de consultorias e institutos de análise: cerca de 79% das empresas já adotaram agentes de IA em alguma forma — mas apenas uma fração pequena os opera de fato em produção, com adoção plena concentrada em poucos setores (bancos e seguradoras lideram; saúde e setor público ficam consideravelmente atrás). Entre as organizações que avançam, dados de 2026 mostram um diferencial decisivo: empresas que nomeiam formalmente um responsável (um "owner") por cada agente em produção têm taxa de conversão de piloto para produção quase três vezes maior do que as que não o fazem — e a ausência desse ownership formal está sobre-representada exatamente no grupo de organizações que reporta ROI negativo após doze meses de operação.
80%
das aplicações corporativas já embarcam ao menos um agente de IA (Gartner, Q1 2026)
23%
das organizações reportam ROI significativo especificamente com agentes autônomos
2,7×
maior taxa de conversão de piloto para produção quando há um owner formal nomeado por agente
Há ainda uma dimensão de risco que raramente aparece nas manchetes sobre produtividade: levantamentos com executivos seniores mostram que a maioria já acredita que sua própria empresa sofreu algum vazamento ou incidente de segurança ligado a ferramentas de IA não homologadas, e mais de um terço das organizações não tem qualquer plano formal de supervisão para os agentes que já estão em operação — a ponto de uma parcela significativa admitir que não conseguiria "desligar" um agente com comportamento anômalo de forma imediata, caso fosse necessário. Esse não é um detalhe técnico secundário: é o mesmo sintoma de fundo descrito no cenário do próximo capítulo, em escala ainda maior — sistemas que operam de forma tecnicamente competente, mas sem uma camada compartilhada que garanta que todos eles "entendem" a organização da mesma forma.
Um cenário do dia a dia
Capítulo 1.2
A Reunião de Segunda-Feira que Toda Empresa com IA em Escala Já Viveu
Para entender por que esse problema é estrutural — e não uma questão de "a tecnologia ainda vai amadurecer" — vale um cenário que já é familiar a qualquer organização que avançou de um agente piloto para vários agentes em produção simultânea. Não é hipotético: é uma composição de situações reais e recorrentes, do tipo que aparece em quase toda conversa de maturidade de IA que a triggo.ai conduz com clientes de médio e grande porte.
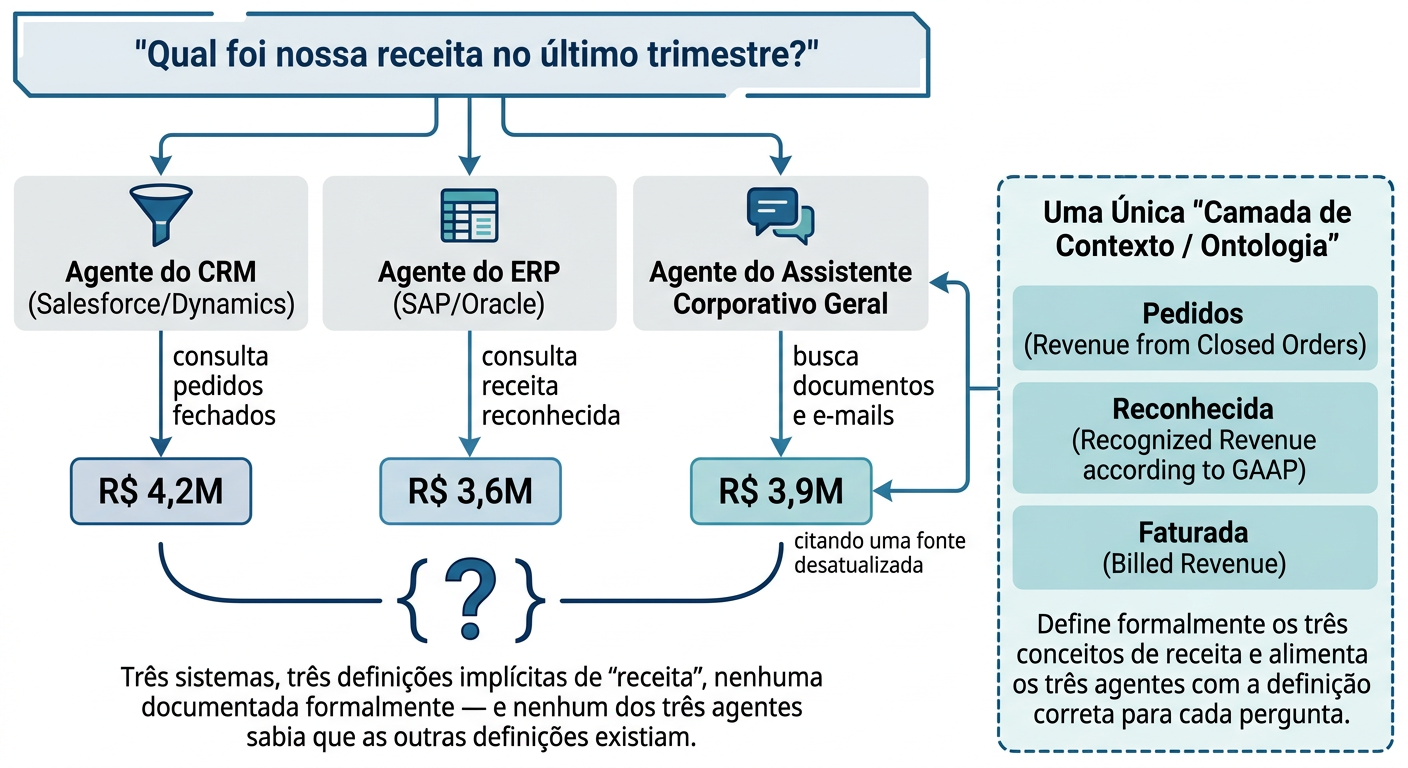
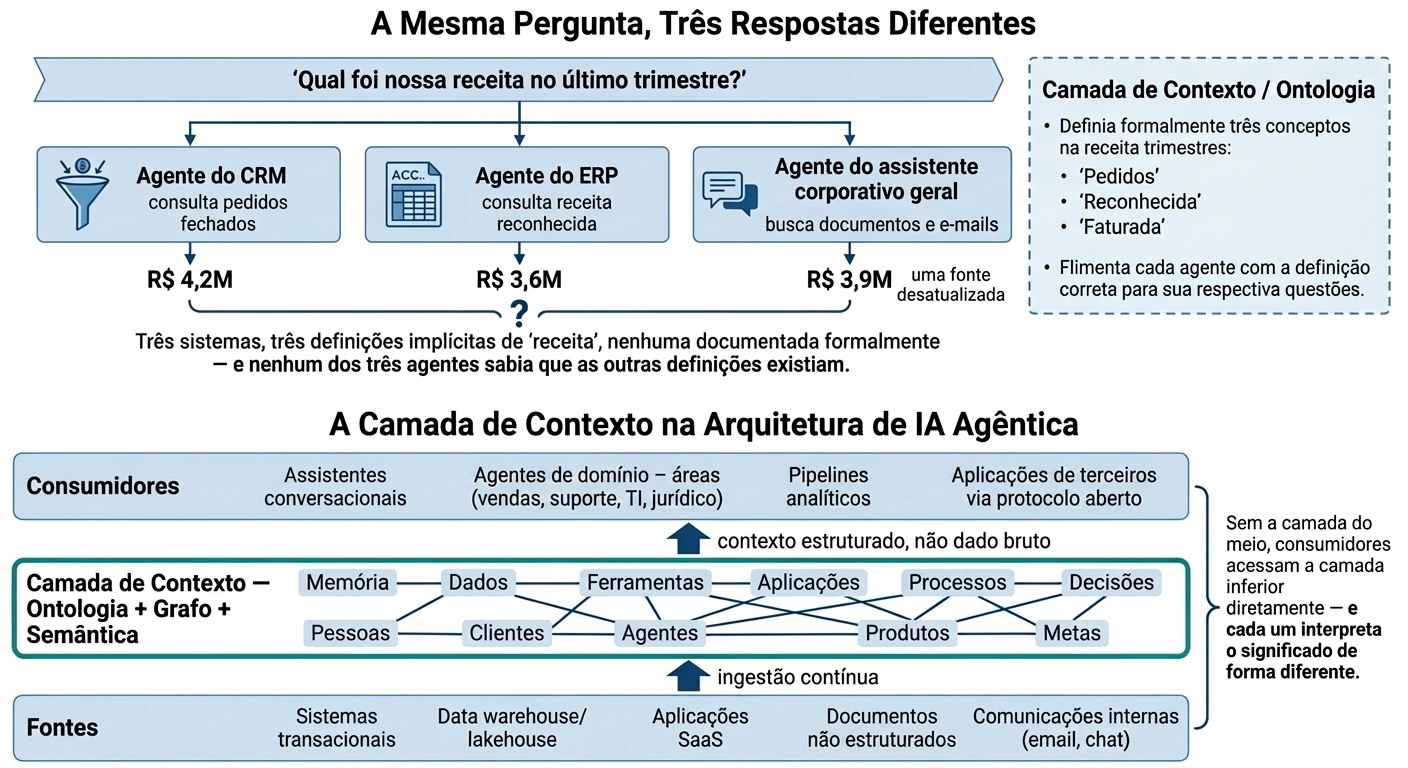
Imagine uma reunião de revisão de resultados em uma empresa de médio porte. O diretor comercial pergunta ao assistente de IA do seu CRM: "qual foi nossa receita no último trimestre?". O número que aparece é animador. Minutos depois, na mesma sala, o diretor financeiro abre o assistente de IA conectado ao ERP e faz exatamente a mesma pergunta. O número é diferente — e não por pouco.
Ninguém errou a conta. Os dois agentes calcularam corretamente, cada um dentro da sua própria fonte. O problema é que "receita", para o sistema comercial, significa pedidos fechados no período. Para o sistema financeiro, significa receita reconhecida segundo as regras contábeis — que pode excluir contratos ainda não faturados ou incluir parcelas de contratos de períodos anteriores. Nenhum dos dois agentes sabia que essa diferença existia. Nenhum dos dois tinha como saber: a definição de "receita" nunca foi formalizada em lugar nenhum que um sistema pudesse consultar — ela vivia, até então, apenas na cabeça de duas pessoas experientes que, intuitivamente, sabiam qual número usar em cada contexto.
Esse tipo de divergência é exatamente o sintoma que a pesquisa de mercado vem documentando sob o nome de "inconsistência entre agentes" — e que, em estágios iniciais de adoção de IA, simplesmente não aparece, porque a empresa ainda tem apenas um agente em uso, sem nada para contradizer. O problema só se manifesta quando múltiplos agentes, conectados a múltiplas fontes, começam a responder à mesma pergunta de negócio em paralelo. É um problema de escala e composição — e é exatamente por isso que ele pega de surpresa tantas lideranças de TI que fizeram tudo "certo" na primeira fase de adoção.
O comportamento mais perigoso não é o erro óbvio — é a resposta plausível
O que torna esse cenário particularmente arriscado não é quando um agente erra de forma óbvia — isso é fácil de detectar e corrigir. O problema real é quando dois agentes erram de forma plausível e silenciosa: ambos os números parecem razoáveis, ambos vêm de um sistema corporativo legítimo, e nenhum dos dois carrega um aviso de que existe uma versão alternativa, igualmente válida, da mesma métrica. A decisão errada não acontece porque a IA "alucinou" no sentido clássico do termo — acontece porque cada agente respondeu corretamente a uma pergunta ligeiramente diferente da que foi feita, sem que ninguém percebesse a diferença.
Fase de maturidade
O que a empresa vê
Por que o problema ainda não apareceu (ou já apareceu)
Um agente, um caso de uso
Tudo funciona bem na demonstração e no piloto
Não há outro agente para contradizer a resposta — a inconsistência não tem como se manifestar ainda
Vários agentes, mesmo domínio
Pequenas divergências começam a aparecer, atribuídas a "bug" ou "dado desatualizado"
Cada agente foi conectado à sua fonte mais próxima, sem que ninguém formalizasse as definições compartilhadas entre elas
Vários agentes, vários domínios, decisões reais
Divergências geram retrabalho, perda de confiança e decisões questionadas publicamente
O custo de não ter contexto compartilhado deixou de ser um incômodo técnico e passou a ser um risco de negócio visível para a liderança
A boa notícia é que a solução para esse cenário não exige reescrever os sistemas existentes nem trocar de modelo de IA. Exige formalizar, uma única vez, o que cada conceito de negócio crítico realmente significa — e tornar essa definição consultável por qualquer agente, em qualquer sistema, de forma consistente. É exatamente esse o papel da camada de ontologia e contexto: ela não cria dado novo, e não torna nenhum agente individualmente "mais inteligente". O que ela faz é tornar explícito, formal e compartilhável um significado que, até então, só existia na cabeça de quem conhecia os dois sistemas e sabia transitar manualmente entre eles.
O paralelo direto
Um agente de IA sem camada de contexto está na posição do diretor financeiro recém-contratado: tecnicamente competente, com acesso aos sistemas certos, mas sem o conhecimento tácito que só vem de anos de experiência na casa para saber qual número usar em cada situação. Ele pode até acertar por coincidência. O que ele não consegue é fazer isso de forma consistente, auditável e replicável em escala — e é exatamente esse o sintoma que aparece, hoje, como "respostas contraditórias entre agentes" nas organizações que avançaram rápido demais na adoção de IA sem investir na camada de significado compartilhado.
Como o contexto chega ao agente
Capítulo 1.3
Índices, Grafos e Token Yield: Por Que a Forma de Entregar Contexto Define Custo e Qualidade
Até aqui estabelecemos o quê falta — o contexto empresarial estruturado. A próxima pergunta, igualmente crítica, é: como esse contexto chega ao agente no momento em que ele precisa? A resposta não é óbvia, e a diferença entre as duas abordagens dominantes tem implicações diretas em custo operacional, qualidade de resposta, latência e — o ponto que mais importa para perguntas complexas — capacidade de navegar múltiplos contextos correlacionados ao mesmo tempo.
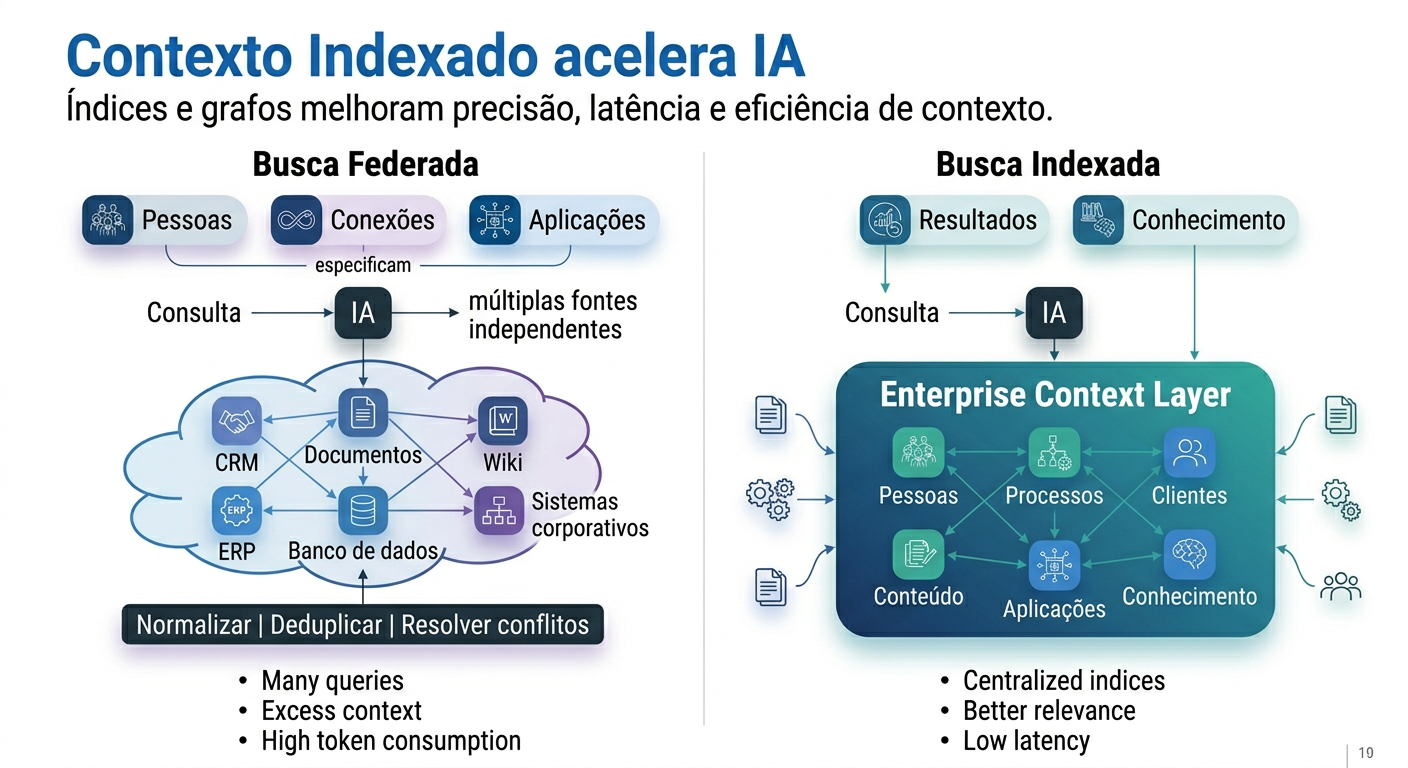
Busca Federada: o modelo intuitivo que cobra caro
A abordagem mais comum, e a mais intuitiva de se implementar, é a busca federada: a cada pergunta feita ao agente, o sistema dispara chamadas simultâneas a múltiplas fontes — CRM, ERP, sistema de tickets, documentos, bases de conhecimento, repositório de código — coletando os resultados, tentando normalizá-los, deduplicá-los e, finalmente, raciocinar sobre eles para produzir uma resposta.
O problema é que cada uma dessas fontes tem seu próprio schema, sua própria semântica local, seu próprio ritmo de atualização e seus próprios formatos de resposta. O agente que recebe esse material precisa, em tempo real, reconciliar conflitos entre fontes — e quando duas fontes discordam (exatamente o cenário do Capítulo 1.2), o agente não tem como resolver sem uma referência externa de significado. O resultado são loops de raciocínio que se multiplicam a cada falha de chamada ou conflito de dado, latência imprevisível que depende da disponibilidade simultânea de todas as APIs consultadas, e uso de tokens que varia de forma incontrolável conforme o número de fontes envolvidas na pergunta.
Busca sobre contexto indexado: o modelo que inverte a ordem do esforço
A alternativa é inverter o quando do esforço: em vez de computar contexto em tempo real a cada pergunta, a organização pré-computa, normaliza e indexa esse contexto antes das perguntas chegarem — construindo um grafo de alta confiança de todas as entidades empresariais, seus relacionamentos e seus processos. Quando o agente recebe uma pergunta, ele não precisa descobrir o que existe na empresa: ele consulta um índice que já sabe, com garantias de qualidade verificadas, quem é quem, o que é o quê, e como as coisas se relacionam.
Dimensão
Busca Federada
Contexto Indexado
Chamadas por pergunta
Muitas — uma por fonte consultada
Mínimas — índice já pré-computado
Volume de contexto entregue
Tendência a buscar mais do que o necessário (overfetch)
Preciso — apenas o relevante para aquela pergunta
Uso de tokens
Imprevisível — varia com número de fontes
Previsível — viabiliza orçamentação real
Latência
Alta e variável — depende de múltiplas APIs externas
Baixa e estável
Loops de raciocínio
Multiplicam a cada conflito entre fontes
Estáveis — dados já normalizados e reconciliados
Sinais entre sistemas
Difícil — cada fonte tem schema próprio
Nativos — ranking unificado e cross-app
Manutenção
Alta — cada conector é um ponto de falha
Centralizada — um índice serve múltiplos agentes
O ponto que raramente aparece: perguntas complexas com múltiplos contextos correlacionados
A diferença entre as duas abordagens se torna mais dramaticamente visível quando a pergunta não é simples. Uma questão como "quais clientes com contrato ativo e histórico de chamados abertos acima de 30 dias estão no segmento que o time de vendas classificou como risco de churn neste trimestre?" cruza pelo menos quatro domínios distintos — contratos, suporte, segmentação comercial e dados de pipeline — cada um vivendo em um sistema diferente, com definições potencialmente divergentes de "cliente ativo", "chamado aberto" e "risco de churn".
Com busca federada, essa pergunta dispara múltiplos loops de chamada, cada um podendo retornar respostas conflitantes que exigem reconciliação — e o token budget da pergunta pode ser consumido só no esforço de descoberta e normalização, antes que qualquer raciocínio real sobre a pergunta em si possa acontecer. Com contexto indexado e uma ontologia que formalizou o que cada um desses termos significa e como esses domínios se relacionam, a mesma pergunta é resolvida contra um grafo que já sabe a resposta para cada sub-pergunta — entregando mais qualidade com fração do custo computacional.
Token yield — a métrica que conecta qualidade e custo
Token yield é a quantidade de valor informacional gerado por token consumido. Implementações com contexto indexado e roteamento inteligente de modelos relatam, consistentemente, redução da ordem de 25% no consumo de tokens e 50% na latência comparadas a abordagens federadas de modelo único — um ganho que se traduz diretamente em fatura de infraestrutura menor e experiência mais responsiva, mas que exige, como pré-condição, uma camada de contexto pré-computado sobre a qual o roteamento pode operar com confiança.
Perspectiva triggo.ai — O que isso significa na prática
Em avaliações de arquitetura com clientes, a triggo.ai observa que a escolha entre busca federada e contexto indexado raramente é tratada como decisão estratégica — geralmente acontece por default, pela rota de menor resistência imediata (conectar as ferramentas que já existem via protocolo aberto e deixar o agente descobrir o contexto em tempo real). O custo disso só aparece depois: nas faturas de inferência que explodem quando a carga de produção real é atingida, na inconsistência entre agentes que erode a confiança dos usuários, e na incapacidade de responder perguntas complexas sem timeouts ou respostas incompletas.
A recomendação: trate a escolha arquitetural de como o contexto será entregue ao agente com o mesmo rigor que você trataria a escolha de banco de dados para um sistema transacional crítico. A decisão tem consequências de longo prazo — e trocar de abordagem depois que a arquitetura está estabelecida tem custo muito maior do que escolher corretamente desde o início.
O dilema da liderança
Capítulo 1.4
A Pressão de Ir Rápido e o Risco de Ir Devagar
Líderes de tecnologia hoje vivem uma tensão paradoxal e simultânea. De um lado, pressões externas empurram para a velocidade: cobrança do conselho, urgência competitiva, expectativa de resultados rápidos em IA por parte da liderança executiva. Quando uma organização cede a essa pressão sem o preparo adequado, os efeitos colaterais aparecem rapidamente — exposição de dados sensíveis por sistemas sem governança, alto gasto com retorno financeiro baixo, fragmentação de ferramentas que nunca se integram de fato, e risco reputacional quando implementações precipitadas falham publicamente.
De outro lado, pressões internas empurram na direção oposta, travando a adoção: cultura organizacional avessa a risco, ausência de um dono claro para a estratégia de IA, dados e aplicações fragmentados em dezenas de sistemas desconectados, medo de ficar para trás da concorrência, a tensão entre usar a IA nativa das ferramentas já contratadas ou investir em soluções especializadas, e o fenômeno crescente do uso não autorizado de ferramentas de IA por colaboradores — criando riscos de conformidade que a área de TI sequer enxerga.
⚠️
Ir rápido demais
Exposição de dados, alto gasto com baixo retorno, fragmentação de ferramentas, risco à marca por implementações precipitadas sem governança adequada.
🐌
Ir devagar demais
Aversão a risco paralisante, ausência de ownership da estratégia de IA, dados em silos, perda de competitividade frente a concorrentes mais ágeis.
🔀
Built-in vs. especializado
A tensão entre usar a IA nativa das ferramentas já adotadas ou investir em soluções especializadas de contexto raramente tem uma resposta óbvia — e a indecisão tem custo.
👤
IA não autorizada
Colaboradores adotam ferramentas de IA fora da governança formal da empresa, criando exposição de dados e riscos de conformidade invisíveis à liderança de TI.
A pergunta estratégica que emerge desse dilema não é "IA sim ou não" — é como conduzir a transformação por IA com confiança. E a resposta que vem se consolidando entre as organizações de maior maturidade não está em escolher entre velocidade e segurança, mas em identificar qual investimento de fundação torna possível avançar rápido sem incorrer nos riscos do avanço precipitado. Essa fundação, como os próximos capítulos detalham, é a camada de contexto e significado — e não, como a maioria assume primeiro, a escolha do modelo ou da ferramenta.
Parte II
II
Ontologia, Semântica e Contexto: Anatomia da Camada
O que efetivamente compõe uma camada de contexto empresarial, como ela se diferencia de um catálogo ou de um data warehouse, e onde ela se posiciona na arquitetura de IA agêntica.
Capítulo 2.1
O Que Realmente Compõe uma Camada de Contexto
Quando se fala em "contexto empresarial" para IA, a tentação é pensar em mais um repositório de dados. Mas o conceito é mais amplo e mais estrutural do que isso: é um grafo dinâmico de entidades que conecta tudo que é relevante sobre a organização — não apenas dados, mas memória institucional, pessoas, processos, ferramentas, decisões passadas e objetivos estratégicos.
Camada de entidade
O que contém
Por que importa para um agente
Memória
Histórico de decisões, projetos anteriores, tentativas e erros documentados
Evita que agentes repitam erros já cometidos pela organização
Pessoas
Perfis, competências, responsabilidades, matrizes de responsabilidade
Permite atribuição correta de tarefas e escalonamento adequado
Dados
Fontes estruturadas e não estruturadas
Fundamenta respostas em fatos reais, não em inferência genérica
Ferramentas
Stack técnico, integrações, APIs disponíveis
Permite escolher a ferramenta certa para cada ação solicitada
Aplicações
Sistemas de negócio e plataformas em uso
Dá ao agente noção de onde a informação realmente vive
Agentes
Outros agentes de IA já em operação na empresa
Evita duplicação de esforço e permite coordenação entre sistemas
Processos
Fluxos de trabalho e runbooks documentados
Garante automação alinhada com a forma real de operar da empresa
Clientes
Informações e histórico de relacionamento
Permite que a IA entenda o negócio em sua dimensão real, não abstrata
Produtos
Catálogo, especificações, roadmap
Habilita respostas precisas sobre a oferta da empresa
Metas / OKRs
Objetivos estratégicos e indicadores-chave
Alinha a ação do agente com as prioridades reais do negócio
Decisões
Registros de decisões arquiteturais e de negócio
Fornece contexto histórico para que novas decisões sejam coerentes
O ponto central — e o que diferencia essa abordagem de um simples catálogo de metadados — é que esse grafo não é estático. Ele é atualizado continuamente à medida que os sistemas conectados evoluem, o que garante que os agentes operem sempre sobre o estado mais atual da organização, e não sobre uma fotografia que envelhece a cada dia.
É essa propriedade — atualização contínua e relacionamento explícito entre entidades — que distingue uma camada de contexto de um simples dicionário de dados ou glossário estático. Um glossário documenta definições; uma camada de contexto as mantém vivas, conectadas e consultáveis em tempo real por qualquer sistema autorizado.
Ontologia vs. semântica vs. busca
Capítulo 2.2
Ontologia, Semantic Layer e Knowledge Graph: Por Que a Confusão de Termos Importa
Um dos maiores obstáculos práticos para que organizações priorizem essa camada é a confusão terminológica que cerca o tema. "Ontologia", "semantic layer", "knowledge graph", "catálogo de dados" são frequentemente usados como sinônimos — e não são. Cada um resolve um problema diferente, e a maioria das implementações corporativas de IA falha justamente por tentar resolver o problema de um deles usando a ferramenta de outro.
Camada
O que é
O que resolve
O que NÃO resolve sozinha
Ontologia
Especificação formal de conceitos, relações e restrições do domínio de negócio
Dá ao agente a capacidade de raciocinar — entender o que as coisas são e como se relacionam
Não calcula métricas nem garante governança sozinha
Semantic Layer
Camada de abstração sobre o data warehouse para métricas e regras de negócio
Garante que "receita" signifique a mesma coisa em todo relatório e consulta
Não permite que o agente percorra relações entre domínios distintos (ex: cliente → contrato → chamado de suporte)
Knowledge Graph
Instância de dados conectados, alinhada a uma ontologia, com identificadores únicos
Permite navegação e inferência sobre relações reais entre entidades
Sem ontologia subjacente, vira apenas uma rede de dados sem significado formal
Catálogo de dados
Inventário de metadados técnicos: tabelas, colunas, linhagem
Ajuda humanos a descobrir onde um dado está
Não confere significado de negócio nem capacidade de raciocínio a um agente
MCP (protocolo de contexto)
Protocolo aberto de transporte de contexto entre sistemas e agentes
Conecta um agente a uma fonte de contexto de forma padronizada
É o "cano", não a "água" — não produz significado, apenas o transporta
"Um semantic layer serve para consulta. Uma ontologia serve para contexto e raciocínio. Confundir as duas é uma das causas mais recorrentes de projetos de IA agêntica que funcionam na demonstração e falham em produção."
— triggo.ai, síntese de pesquisa setorial sobre arquitetura de contexto (2026)
Analistas do Gartner reforçaram esse ponto publicamente em 2026: a previsão é que 60% dos projetos de analytics agêntico que dependem exclusivamente de protocolos de transporte de contexto, sem uma camada semântica consistente por trás, vão falhar até 2028. O protocolo move contexto — ele não o produz. É uma distinção sutil, mas decisiva: investir apenas em conectividade (o "cano") sem investir na camada de significado (a "água" que passa por ele) é como conectar o agente do CRM e o agente do ERP do cenário anterior à mesma rede e presumir que, por estarem tecnicamente conectados, eles vão automaticamente concordar sobre o que significa "receita".
Indexação prévia vs. busca federada: a decisão arquitetural mais subestimada
Existe uma segunda decisão técnica, menos discutida publicamente, mas com impacto direto em custo e confiabilidade: como o agente acessa o contexto no momento da consulta. Duas abordagens dominam o mercado, com implicações muito diferentes.
Dimensão
Busca Federada
Busca Indexada (contexto pré-computado)
Como funciona
A cada pergunta, o agente consulta múltiplas fontes em tempo real e tenta normalizar e reconciliar os resultados
O contexto já foi processado, normalizado e relacionado antes da pergunta chegar
Chamadas de ferramenta
Múltiplas chamadas simultâneas, uma por fonte consultada
Mínimas — a maior parte do trabalho já foi pré-computada
Uso de contexto
Tendência a buscar mais do que o necessário, desperdiçando capacidade de processamento
Preciso — apenas o que é relevante para a pergunta específica
Latência
Alta e variável — depende da disponibilidade de múltiplas integrações externas
Baixa e previsível
Custo computacional
Imprevisível — varia conforme o número de fontes consultadas a cada vez
Previsível — viabiliza orçamento e controle de custo de IA
Manutenção
Alta — cada integração é um ponto de falha potencial
Centralizada — um índice bem mantido serve múltiplos agentes
A diferença prática é significativa: índices e grafos pré-computados oferecem aos agentes mapas de alta confiança das entidades, relações e processos da organização — o que resolve o problema fundamental de um agente que precisa "descobrir o que existe" a cada nova pergunta. O resultado é triplo: eliminação de boa parte da latência, melhoria de relevância por sinais cruzados entre sistemas, e previsibilidade de custo que viabiliza orçamentação séria de iniciativas de IA — em vez da surpresa recorrente de faturas de processamento muito acima do esperado.
Roteamento e aprendizado
Capítulo 2.3
Roteamento Inteligente e Aprendizado Contínuo: A Camada Fica Mais Inteligente Sozinha
Uma camada de contexto madura não apenas armazena significado — ela também decide, de forma inteligente, como usá-lo. Dois mecanismos complementares ilustram esse princípio em implementações avançadas observadas no mercado.
Roteamento inteligente de modelos
Em vez de toda consulta passar pelo mesmo modelo de linguagem com a mesma estratégia de busca, sistemas maduros tomam três decisões em paralelo para cada requisição: qual modalidade usar (texto, voz, visão), qual profundidade de raciocínio é necessária (uma pergunta simples não precisa do mesmo esforço computacional que uma investigação complexa), e qual modelo, entre dezenas disponíveis, está estatisticamente mais bem avaliado para aquele tipo específico de tarefa — com base em milhares de avaliações trimestrais cobrindo correção factual, completude da resposta, utilidade prática e eficiência de uso de capacidade computacional.
Implementações documentadas dessa abordagem relatam reduções da ordem de 50% em latência e 25% em consumo de tokens comparado a um roteamento fixo de modelo único — um ganho que se traduz diretamente em custo operacional menor e experiência mais responsiva para o usuário final.
Aprendizado contínuo sem retreinamento manual
O segundo mecanismo é o que distingue uma camada de contexto estática de uma genuinamente viva: a capacidade de ficar mais precisa com o uso, sem que ninguém precise reconfigurar nada manualmente. Isso acontece por dois caminhos complementares.
🔍
Mineração de processo (antes da execução)
Antes de agir, o sistema mapeia padrões implícitos de processo observados no uso real: sequências como "investigar → redigir especificação → escalar" ou "planejar sprint → atribuir → revisar → integrar código" são identificadas automaticamente a partir do comportamento real das equipes — não de um manual de processos desatualizado.
📈
Aprendizado por trajetória (depois da execução)
Após cada execução, o sistema registra a sequência de ações tomada e aprende qual estratégia produziu o melhor resultado, gerando e comparando variantes hipotéticas até convergir para a abordagem mais eficiente — um ciclo de otimização contínua sem intervenção humana direta.
O combustível desse aprendizado são sinais de uso profundos, já presentes nos sistemas corporativos mas raramente explorados: visualizações, edições, comentários, compartilhamentos, integrações de código, mensagens, trajetórias de execução e feedback humano explícito. Quanto mais a camada de contexto é usada, mais contexto ela acumula, melhor compreende os processos reais da organização e mais precisas se tornam suas respostas — um ciclo virtuoso que, segundo a literatura mais recente sobre arquiteturas neurosimbólicas para sistemas agênticos corporativos, gera ganhos de recuperação factual da ordem de 55% acima de abordagens convencionais de busca aumentada por recuperação quando a estrutura ontológica subjacente é bem desenhada.
Um cuidado técnico que a pesquisa recente revela
Nem toda injeção de contexto é estritamente benéfica. Pesquisa publicada em 2025 e 2026 sobre o que se convencionou chamar de "interferência contextual" mostra que o desempenho de modelos de linguagem pode degradar entre 14% e 85% à medida que o volume de contexto cresce, mesmo quando a recuperação de informação é perfeita — um custo imposto pelo próprio volume de contexto, independente da qualidade do conteúdo. A implicação prática é que mais contexto nem sempre é melhor: a engenharia da camada de significado precisa ser seletiva e hierárquica, não apenas abrangente. Esse é, justamente, um dos motivos pelos quais essa disciplina exige profundidade técnica real — e não apenas a instalação de mais uma ferramenta.
Parte III
III
Viabilidade Técnica e Financeira
Quanto custa não ter essa camada, quanto custa construí-la, e como ela se integra de forma realista à arquitetura de dados que a empresa já possui.
Capítulo 3.1
O Custo de Não Ter Contexto é Maior do que Parece
A objeção mais comum à priorização de uma camada de ontologia e contexto é financeira: "isso é caro e o retorno é incerto". Mas essa objeção geralmente ignora o custo, já em curso, de operar sem essa camada — um custo que aparece disperso em várias linhas orçamentárias e raramente é somado em um único número.
💸
Investimento sem retorno
O investimento corporativo em IA generativa e agentes não desapareceu nos cerca de três quartos das organizações que ainda não reportam ROI significativo — foi gasto em modelos, licenças e integrações que operaram sobre uma fundação de contexto insuficiente para sustentar resultado em escala.
🔁
Retrabalho por inconsistência
Quando dois agentes respondem perguntas equivalentes de forma diferente — porque cada um resolveu o significado de um termo de negócio contra uma fonte distinta — o custo de reconciliação manual, auditoria e correção recai sobre as equipes humanas que a IA deveria aliviar.
⏳
Pilotos que nunca escalam
Projeções do Gartner indicam abandono de mais de 40% dos projetos de IA agêntica até 2027. Cada piloto abandonado representa meses de investimento em engenharia, dados e gestão de mudança que não se converteram em capacidade permanente.
🕳️
Sprawl de ferramentas
Sem uma camada central de contexto, cada nova ferramenta de IA reconstrói sua própria interpretação fragmentada da organização — multiplicando custo de integração e tornando a manutenção cada vez mais cara a cada ferramenta nova adicionada.
O ponto central não é que ferramentas e modelos sejam investimentos ruins — é que, sem a camada de significado, eles operam com um teto de valor muito mais baixo do que o anunciado nas demonstrações de produto. Estudos que comparam organizações líderes em maturidade de IA com a média de mercado mostram diferenças consistentes: usuários de plataformas que investiram pesadamente em contexto empresarial unificado relatam ser até 50% mais propensos a reportar que a IA melhorou resultados de negócio, e significativamente mais confiantes na estratégia de IA da própria organização — uma diferença que não vem do modelo usado, mas da fundação sobre a qual ele opera.
Como medir o investimento
Capítulo 3.2
Como Avaliar a Viabilidade Financeira de uma Camada de Contexto
Diferente de um projeto de IA pontual, o investimento em ontologia e contexto tem uma característica financeira específica: o retorno não é linear ao longo do tempo — ele se acelera. Os primeiros meses concentram custo de mapeamento e modelagem; os meses seguintes começam a distribuir esse investimento por um número crescente de casos de uso que reaproveitam a mesma fundação.
Dimensão
O que avaliar
Como medir
Custo de construção
Esforço de modelagem ontológica, mapeamento de domínios prioritários, integração de fontes
Horas de engenharia + arquitetura de dados por domínio modelado
Custo de manutenção
Atualização contínua do grafo, governança de mudanças semânticas
% de esforço de engenharia dedicado a manutenção vs. construção nova
Reutilização entre casos de uso
Quantos agentes/produtos diferentes consomem a mesma camada de contexto
Número de consumidores ativos por domínio de contexto publicado
Redução de latência e custo de inferência
Ganho de eficiência de roteamento inteligente e indexação prévia
Tokens consumidos e tempo de resposta, antes e depois
Taxa de produção vs. piloto
Quantos projetos de IA chegam de fato à produção sustentada
% de pilotos que escalam, comparado à média setorial de referência
Confiança e adoção
O quanto as equipes de negócio confiam e usam os agentes de fato
Frequência de uso espontâneo; taxa de correção/override manual
A literatura mais recente sobre o chamado "gap de valor da IA" — o hiato entre capacidade de modelo e impacto real de negócio — converge em um diagnóstico comum: fechar essa lacuna exige contexto executável e relacional, ancorado em semântica de negócio real, e não simplesmente despejar mais dados em formato de texto dentro do prompt de um modelo de linguagem. A diferença entre as duas abordagens não é sutil em termos de custo — contexto mal estruturado consome capacidade computacional de forma redundante a cada consulta; contexto bem estruturado é computado uma vez e reaproveitado indefinidamente.
Perspectiva triggo.ai — Como Avaliamos Viabilidade com Clientes
Em projetos de avaliação de maturidade com clientes, a triggo.ai recomenda começar pelo domínio de negócio onde a inconsistência semântica já gera dor visível e mensurável — tipicamente onde duas áreas usam a mesma palavra para coisas diferentes (receita reconhecida vs. receita contratada; cliente ativo vs. cliente cadastrado). Modelar esse domínio primeiro produz retorno demonstrável em semanas, não em trimestres, e cria o caso de negócio interno para expandir a camada de contexto a outros domínios.
O erro mais caro que observamos não é começar pequeno — é tentar modelar toda a organização de uma vez antes de provar valor em um domínio específico. Isso atrasa o primeiro resultado mensurável e mina a confiança organizacional no investimento.
Integração com a stack existente
Capítulo 3.3
Como a Camada de Contexto se Integra à Arquitetura de Dados Já Existente
Um receio comum e legítimo é que investir em ontologia e contexto signifique substituir a infraestrutura de dados já implantada — data warehouse, lakehouse, ferramentas de BI, plataformas de IA corporativa. Não é esse o caso em implementações bem-sucedidas. A camada de contexto opera como uma camada adicional, não como substituição — ela se conecta à infraestrutura existente e a enriquece, em vez de demandar uma reconstrução do zero.
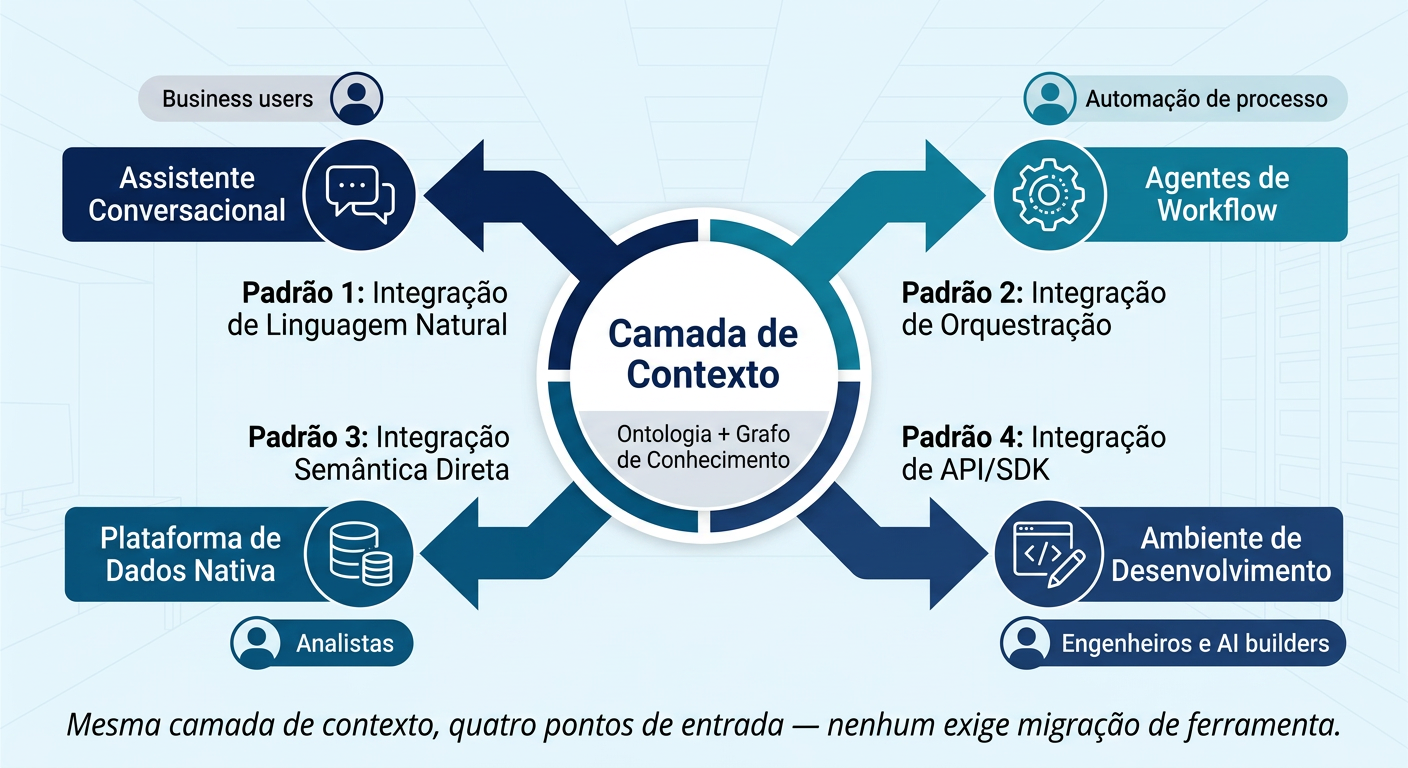
Padrões observados em integrações maduras entre camadas de contexto e plataformas de dados corporativas (categoria que inclui fornecedores como Snowflake, Databricks e equivalentes) tipicamente seguem quatro arquétipos, cada um servindo um perfil diferente de usuário dentro da mesma organização:
Padrão de integração
Melhor para
O que entrega
Contexto dentro do assistente conversacional
Usuários de negócio
Consulta a dados governados da plataforma analítica diretamente na interface conversacional, já enriquecida com contexto organizacional mais amplo
Contexto dentro de agentes de workflow
Equipes automatizando processos repetitivos
Combinação de dados governados da plataforma com contexto e ação, conduzindo o "próximo melhor passo" dentro de um fluxo de trabalho agêntico
Contexto via protocolo aberto na plataforma nativa
Analistas que já vivem dentro da plataforma de dados
Conhecimento organizacional entregue na experiência que o usuário já conhece e confia, sem exigir troca de ferramenta
Contexto no ambiente de desenvolvimento
Engenheiros de dados e desenvolvedores de IA
Contexto de negócio rico entregue diretamente no fluxo de desenvolvimento, aproveitando camadas semânticas já existentes
O princípio comum a todos os quatro padrões é que cada equipe começa de onde já trabalha — não é exigida uma migração de ferramenta para que o contexto chegue até ela. Essa é, na prática, a diferença entre um projeto de contexto que se sustenta no tempo e um que se torna mais uma iniciativa abandonada: a adoção não depende de mudar o comportamento das pessoas, mas de enriquecer silenciosamente as ferramentas que elas já usam todos os dias.
A ambição estratégica: tornar-se a camada de referência
Empresas líderes nesse espaço articulam uma ambição que vale entender, mesmo que de forma crítica: tornar-se o que se convencionou chamar de "sistema de contexto" da organização — a camada fundamental que alimenta toda e qualquer iniciativa de IA, tanto sobre dados estruturados quanto sobre dados não estruturados. O posicionamento é estrategicamente análogo ao que uma plataforma de CRM se tornou como sistema de registro de relacionamento com cliente, ou uma plataforma de RH como sistema de registro de força de trabalho: uma camada tão central que se torna, na prática, infraestrutura crítica e não mais uma ferramenta entre outras.
Para a liderança de tecnologia, essa ambição setorial é menos importante do que o princípio subjacente: contexto empresarial bem estruturado deve ser tratado como ativo estratégico de infraestrutura — algo que se constrói uma vez e se reaproveita indefinidamente — e não como insumo ad hoc, reconstruído do zero a cada nova ferramenta de IA que a empresa decide testar.
Parte IV
IV
A Fronteira Ainda Fora do Radar
Por que a maioria das organizações ainda não vê isso como prioridade — e por que as que já operam IA em escala real já enxergam essa camada como o próximo desafio inevitável.
Capítulo 4.1
Por Que Isso Ainda Não Está no Radar da Maioria
Existe uma razão estrutural, não apenas de prioridade, pela qual ontologia e contexto ainda não aparecem como pauta central na maioria dos comitês executivos de tecnologia: a maturidade média em IA agêntica ainda é incipiente. Organizações que estão nas primeiras fases de adoção — testando copilotos, automatizando tarefas pontuais, validando casos de uso isolados — simplesmente ainda não bateram no teto que essa camada resolve.
É um padrão que se repete em toda curva de adoção de tecnologia: o problema seguinte só se torna visível depois que o problema anterior foi parcialmente resolvido. Uma empresa que ainda está validando se um assistente de IA economiza tempo em tarefas individuais não enfrenta, ainda, o problema de dois agentes dando respostas contraditórias sobre a mesma métrica de negócio — porque ela ainda não tem dois agentes em produção simultânea consultando domínios sobrepostos. O problema de ontologia é, por definição, um problema de escala e de composição — ele aparece quando múltiplos agentes, múltiplos domínios e múltiplas decisões automatizadas começam a interagir entre si.
O sintoma que antecede o diagnóstico
Antes de reconhecer explicitamente "precisamos de uma camada de ontologia", organizações em transição de maturidade costumam relatar sintomas difusos: "nossos agentes dão respostas diferentes para a mesma pergunta dependendo de quem pergunta", "não conseguimos confiar nos números que a IA traz sem verificar manualmente", "cada novo piloto de IA recomeça do zero o mapeamento dos nossos dados". Esses sintomas são, quase sempre, o problema de contexto se manifestando antes de ser nomeado como tal.
Esse padrão é coerente com o que a pesquisa do MIT documentou: a divisão entre as organizações que escalam IA com sucesso e as que ficam presas em pilotos não está distribuída aleatoriamente — está concentrada em poucas indústrias e, dentro delas, nas organizações que já romperam a barreira da experimentação isolada para a operação coordenada de múltiplos sistemas de IA. É precisamente nesse ponto de inflexão — não antes — que a ausência de uma camada de significado compartilhado deixa de ser um detalhe técnico e passa a ser o fator limitante mais citado pelas equipes de maior maturidade.
O que a maturidade revela
Capítulo 4.2
O Que as Organizações de Maior Maturidade Já Reconhecem
Entre as organizações que romperam essa barreira — que têm múltiplos agentes em produção, consultando domínios distintos, tomando ou recomendando decisões reais — emerge um reconhecimento consistente e cada vez mais documentado pela pesquisa acadêmica e de mercado: o desafio seguinte não depende de ferramenta nem de modelo de linguagem. Ele depende de uma camada de significado que nenhuma ferramenta isolada, por mais sofisticada que seja, consegue fornecer sozinha.
Esse reconhecimento aparece em múltiplas frentes de pesquisa independentes, o que reforça que não se trata de discurso comercial de um único fornecedor, mas de um padrão emergente real:
🎓
Pesquisa acadêmica (MIT)
O laboratório de mídia do MIT, através do Project NANDA, identificou que o fator decisivo entre pilotos de IA que escalam e os que estagnam é a capacidade de aprendizado contextual e integração real com o fluxo de trabalho — não a sofisticação do modelo usado.
📊
Pesquisa de mercado (Harvard Business Review Analytic Services)
O estudo conduzido com uma fornecedora de infraestrutura de dados em março de 2026 cravou que apenas 7% das empresas têm dados completamente prontos para IA — um número que se mantém teimosamente baixo mesmo entre organizações com investimento pesado em IA generativa.
🔬
Pesquisa técnica (arquiteturas neurosimbólicas)
Estudos publicados em 2026 sobre arquiteturas que combinam raciocínio neural com restrições ontológicas formais demonstram ganhos consistentes de precisão factual em agentes corporativos — evidência técnica direta de que estrutura formal de significado produz resultado mensurável, não apenas teórico.
🏢
Analistas de indústria (Gartner)
Previsões públicas recentes apontam que mais de 40% dos projetos de IA agêntica serão abandonados até 2027, e que a maioria dos projetos de analytics agêntico que dependem só de protocolos de transporte de contexto, sem semântica subjacente, vai falhar até 2028.
O padrão comum entre essas quatro fontes — independentes entre si, com metodologias distintas — é notável: todas chegam à mesma conclusão por caminhos diferentes. O gargalo da próxima fase de maturidade em IA não está em treinar modelos melhores. Está em construir a camada de significado que permite que modelos já excelentes operem com confiabilidade dentro do contexto específico de cada organização.
"As empresas que ainda não sentiram essa dor não estão erradas em não priorizá-la — elas simplesmente ainda não chegaram ao ponto da curva de maturidade onde ela se torna o gargalo dominante. As que já chegaram lá não têm mais dúvida sobre isso."
— triggo.ai, observação de campo em projetos de maturidade em IA
Indo além das ferramentas
Capítulo 4.3
Por Que Isso Vai Muito Além de Ferramentas ou de Escolha de LLM
Há uma armadilha de raciocínio comum nessa fase de transição: assumir que o problema se resolve trocando de fornecedor de modelo de linguagem, ou adicionando mais uma ferramenta de orquestração de agentes ao portfólio já fragmentado. Os quatro pilares de pesquisa citados no capítulo anterior convergem precisamente no ponto oposto: nenhuma combinação de modelo e ferramenta resolve um problema que é, por natureza, de modelagem de domínio e governança semântica.
Isso porque ontologia, no sentido técnico do termo, não é uma capacidade de produto que se compra pronta — é um trabalho de modelagem que exige entendimento profundo de como a organização específica define seus próprios conceitos centrais. "Cliente ativo" significa algo diferente para o time comercial, para o time de cobrança e para o time de produto — e nenhum modelo de linguagem, por mais avançado, consegue adivinhar qual dessas três definições é a correta sem que alguém a tenha formalizado.
O que NÃO resolve o problema
Por quê
Trocar de modelo de linguagem
O modelo pode ser perfeito e ainda assim não saber que "receita" tem três definições diferentes em três áreas da mesma empresa
Adicionar mais um protocolo de conectividade
Protocolos de transporte movem contexto — não o criam nem o governam
Comprar mais uma plataforma de orquestração de agentes
Orquestração sem semântica compartilhada coordena ações, não significados
Aumentar o volume de dados disponível para o agente
Pesquisa recente mostra que mais contexto, sem estrutura, pode degradar a qualidade da resposta
O que efetivamente resolve é um investimento de outra natureza: modelagem formal de domínio, governança de significado compartilhado entre áreas que historicamente nunca precisaram concordar sobre definições, e uma arquitetura técnica — ontologia, grafo de conhecimento, semantic layer, indexação prévia — desenhada para sustentar esse significado de forma viva e auditável. É um trabalho que combina arquitetura de dados, governança organizacional e modelagem de domínio de negócio — e que, justamente por isso, não cabe inteiramente dentro de nenhuma categoria de ferramenta isolada.
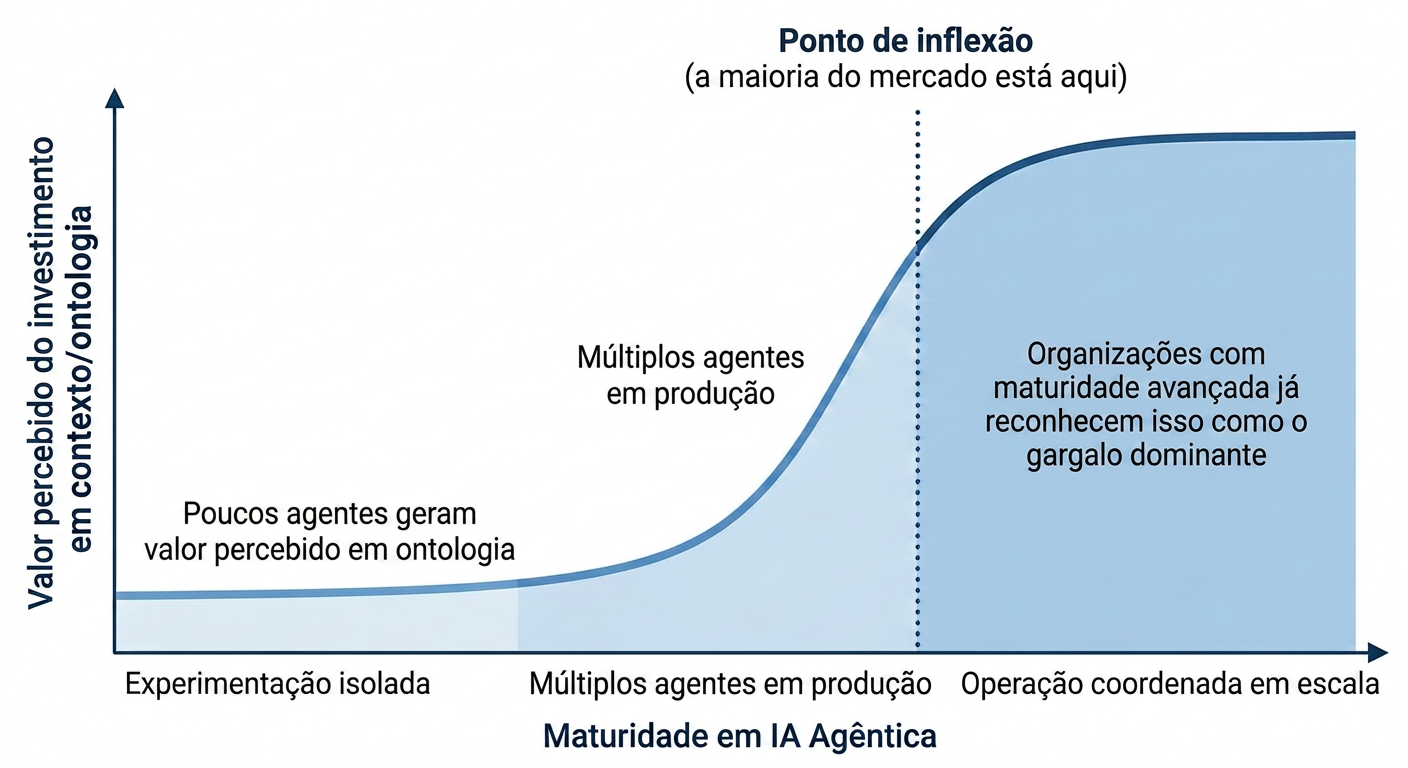
Gráfico de linha com eixo X "Maturidade em IA Agêntica" (de "Experimentação isolada" a "Operação coordenada em escala") e eixo Y "Valor percebido de investir em contexto/ontologia". A curva começa baixa e plana na fase de experimentação isolada (poucos agentes, baixo valor percebido em ontologia), sobe abruptamente na transição para múltiplos agentes em produção, e se torna o fator dominante na fase de operação coordenada em escala. Uma linha vertical pontilhada marca o "ponto de inflexão" onde a maioria das empresas ainda não chegou, rotulada "a maioria do mercado está aqui". Outra área sombreada à direita do ponto de inflexão rotulada "organizações de maturidade avançada já reconhecem isso como o gargalo dominante".
Conclusão
A Fronteira que Vale Antecipar
O argumento central deste relatório não é que toda organização deva, hoje, priorizar um programa formal de ontologia corporativa. Para empresas nas fases iniciais de adoção de IA, isso seria prematuro — o retorno mais imediato ainda está em validar casos de uso, construir confiança organizacional e amadurecer práticas básicas de governança de dados.
O argumento é outro, mais estratégico: essa fronteira está chegando, é previsível, e as organizações que a antecipam — modelando seus domínios críticos antes de serem forçadas pela dor da inconsistência em produção — chegam à fase de operação coordenada em escala com uma vantagem estrutural que é muito cara de reconstruir depois. Assim como a divergência entre o agente do CRM e o agente do ERP do cenário do Capítulo 1.2 não é causada por um erro pontual corrigível com um ajuste técnico, mas por uma lacuna estrutural de significado compartilhado, a camada de contexto para IA agêntica é uma inevitabilidade arquitetural à medida que mais agentes entram em produção simultânea — a única pergunta em aberto é quais organizações chegam preparadas e quais chegam reagindo depois que a primeira decisão errada já foi tomada com base em números contraditórios.
Recomendações triggo.ai
Avalie sua maturidade real antes de investir. Se sua organização ainda está validando pilotos isolados de IA, o investimento prioritário não é ontologia — é consolidar a base de Data Products e governança que a sustentará depois (ver nosso book "Data Product & AI" para esse percurso).
Se você já opera múltiplos agentes em produção, não espere a dor aparecer. Inconsistência entre agentes, baixa confiança dos usuários de negócio e retrabalho de reconciliação manual são sinais de que o problema de contexto já chegou — mesmo que ainda não tenha esse nome dentro da sua organização.
Comece pelo domínio de maior atrito semântico, não pelo maior volume de dados. O ganho mais rápido e mais visível vem de resolver a primeira contradição de definição que já causa dor reconhecida entre áreas — não de modelar a empresa inteira de uma vez.
Trate isso como modelagem de domínio, não como compra de ferramenta. Nenhuma plataforma resolve isso sozinha. A camada de contexto exige tempo de especialistas que entendem tanto a arquitetura técnica quanto a semântica real do negócio — um investimento de competência interna, não apenas de licenciamento.
"Ninguém sentia falta de uma camada de contexto compartilhado enquanto havia apenas um agente de IA em produção — até que o segundo, o terceiro e o quarto agente entraram em cena e começaram a discordar entre si. A IA agêntica corporativa está se aproximando, rapidamente, desse mesmo ponto de inflexão, empresa após empresa."
— triggo.ai · Data & AI Product Management
By continuing to use our site, you acknowledge the use of cookies to improve your experience, analyze traffic, and personalize content. Read our Privacy Policy.