Este artigo descreve como estruturar uma base de conhecimento eficiente para aplicações de IA, com foco no raciocínio por trás de cada etapa, nos erros mais comuns e nas boas práticas que diferenciam projetos...
Leia maisEste artigo descreve como estruturar uma base de conhecimento eficiente para aplicações de IA, com foco no raciocínio por trás de cada etapa, nos erros mais comuns e nas boas práticas que diferenciam projetos...
Leia maisEste artigo aborda que o sucesso da IA não começa por ela, começa nos dados. Ele defende que muitas empresas falham ao tentar escalar iniciativas de IA porque ainda tratam dados como suporte, e...
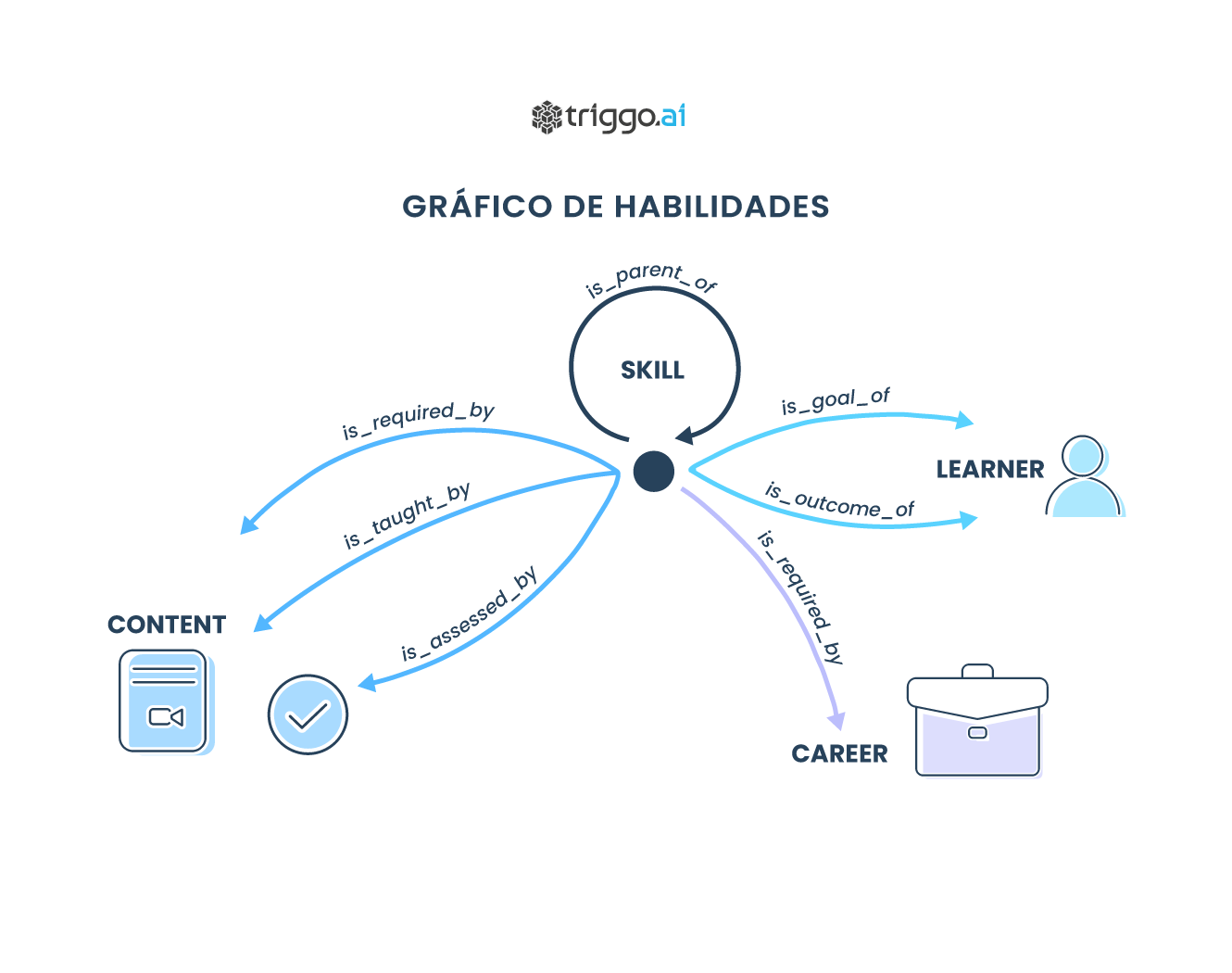
Leia maisEntenda o que é Ontologia e como ela funciona para o sucesso de projetos de Inteligência Artificial.
Leia maisEste artigo aborda a mudança de paradigma do big data e as razões das organizações alterarem o foco para small and wide data.
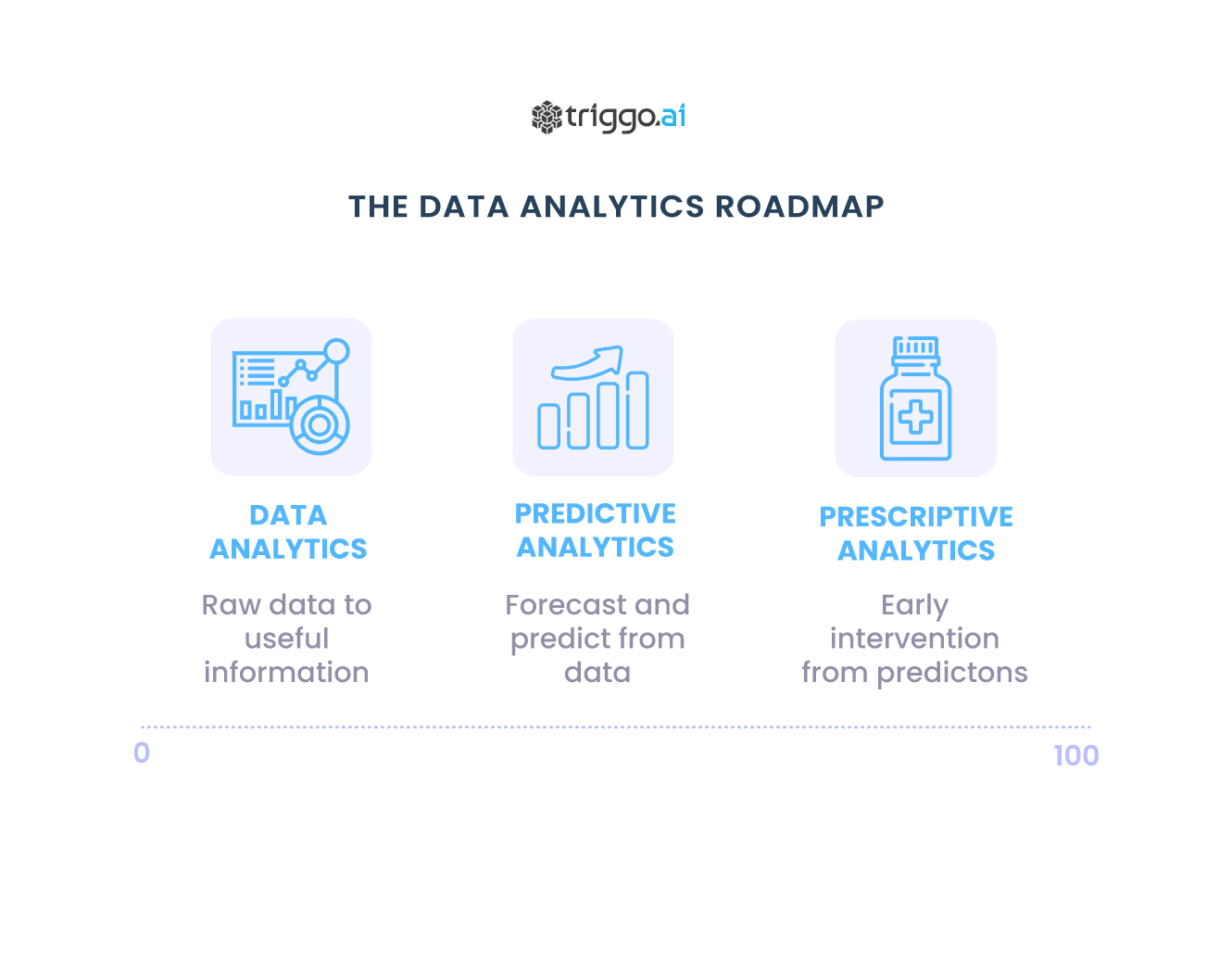
Este artigo aborda a escalada de Advanced Analytics do Canva, uma das maiores plataformas de design que permite aos usuários criar gráficos de mídia social, apresentações, infográficos, marketing digital e outros conteúdos visuais.
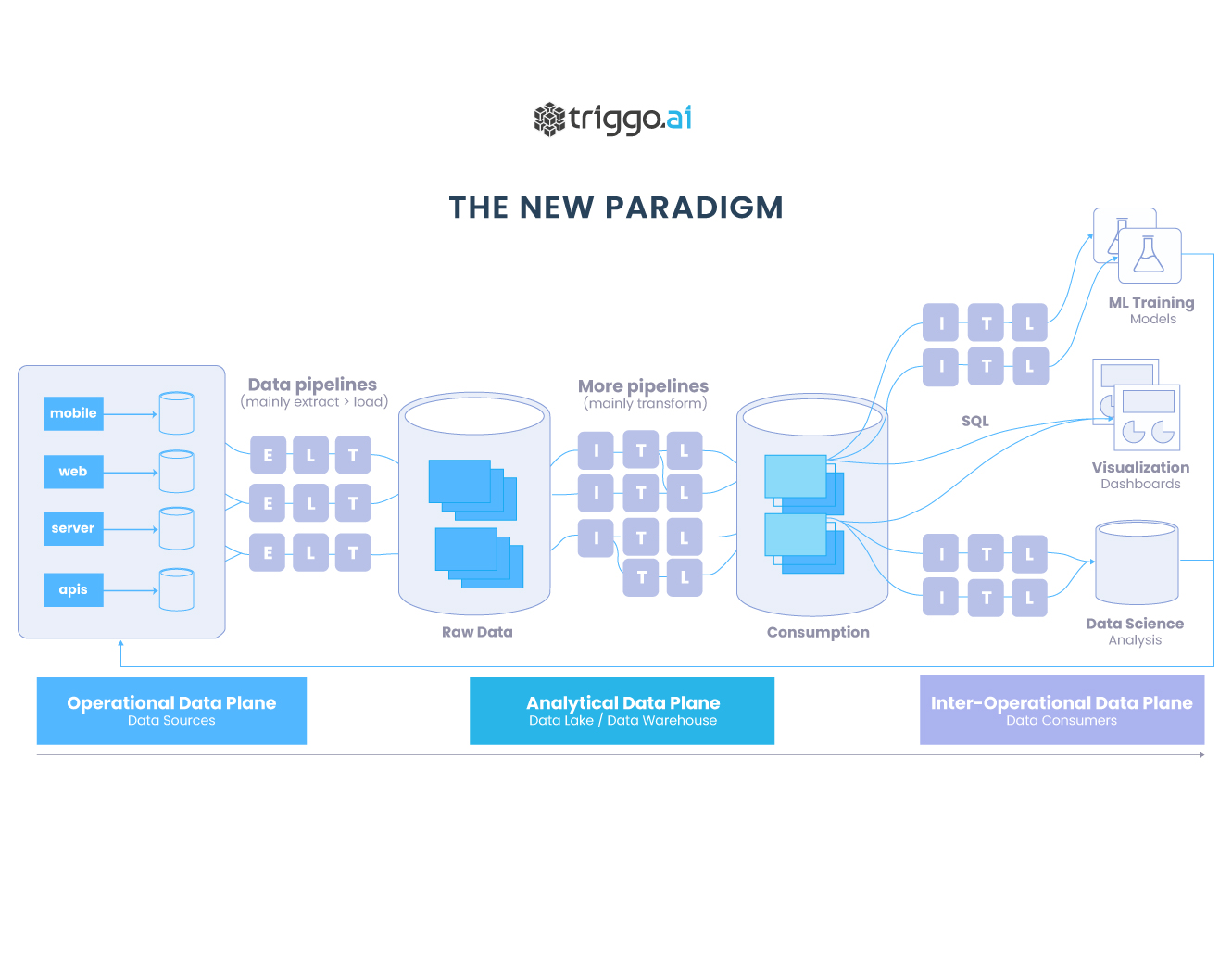
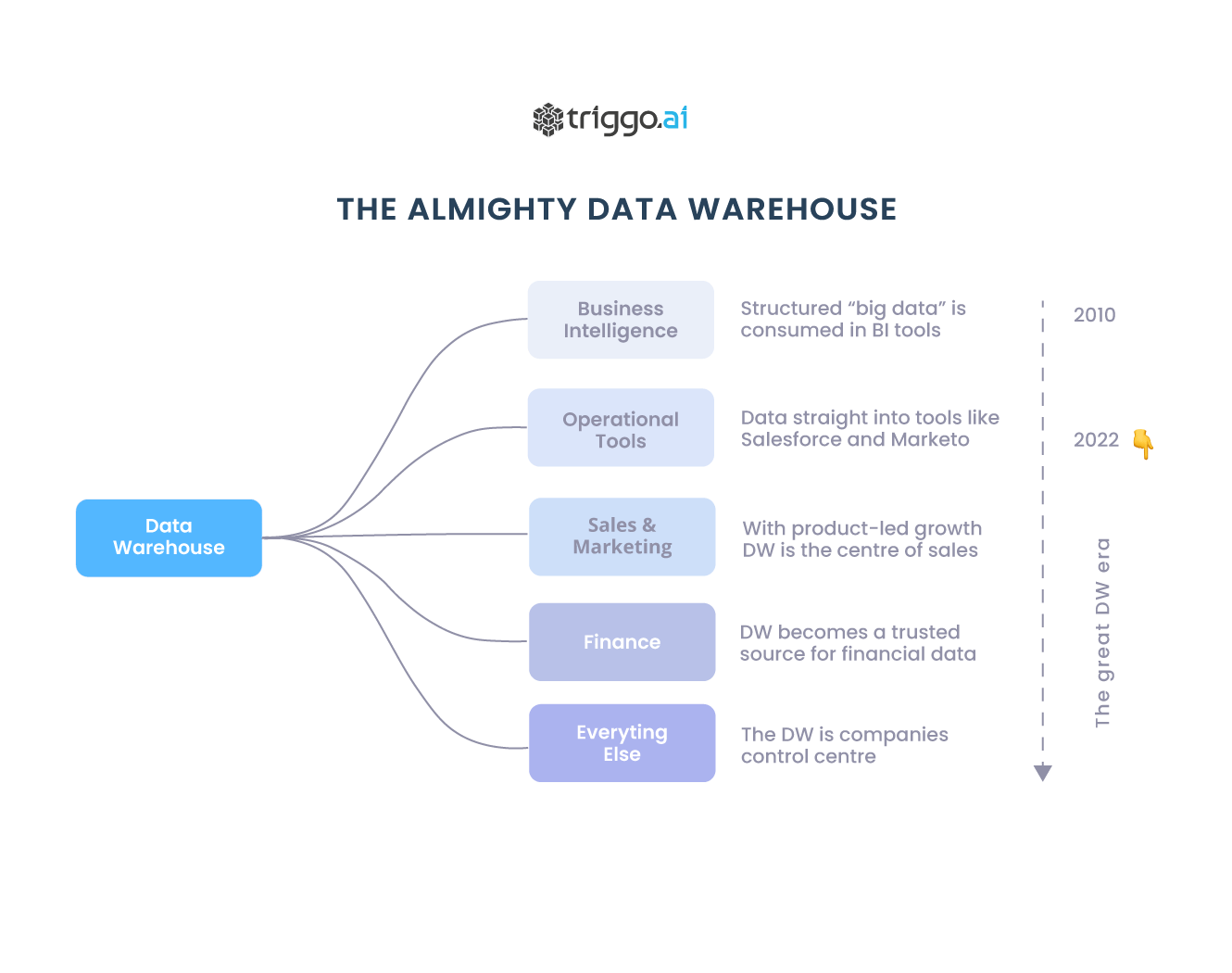
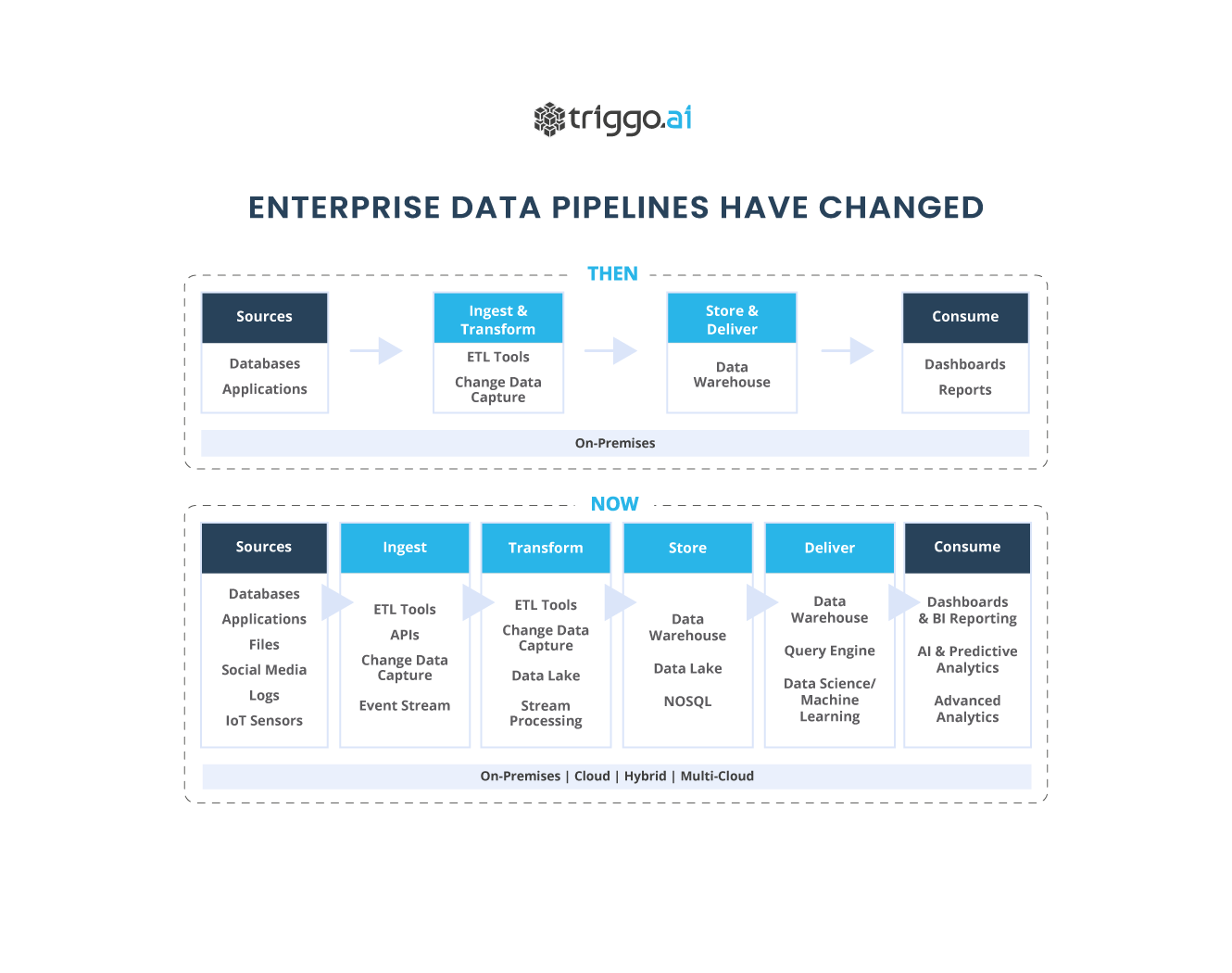
O Cloud Data Warehouse ou Lakehouse (termos que tendem a se convergir em breve) passará de uma ferramenta de inteligência de negócios para o centro de tudo o que as empresas fazem. Neste artigo abordamos como tudo isso vai acontecer ou, na verdade, o que já está começando a acontecer.
Em sua essência, os dados precisam de medição e existem boas razões para isso. Confira neste artigo quais são as principais métricas e o que elas entregam para as equipes de dados.
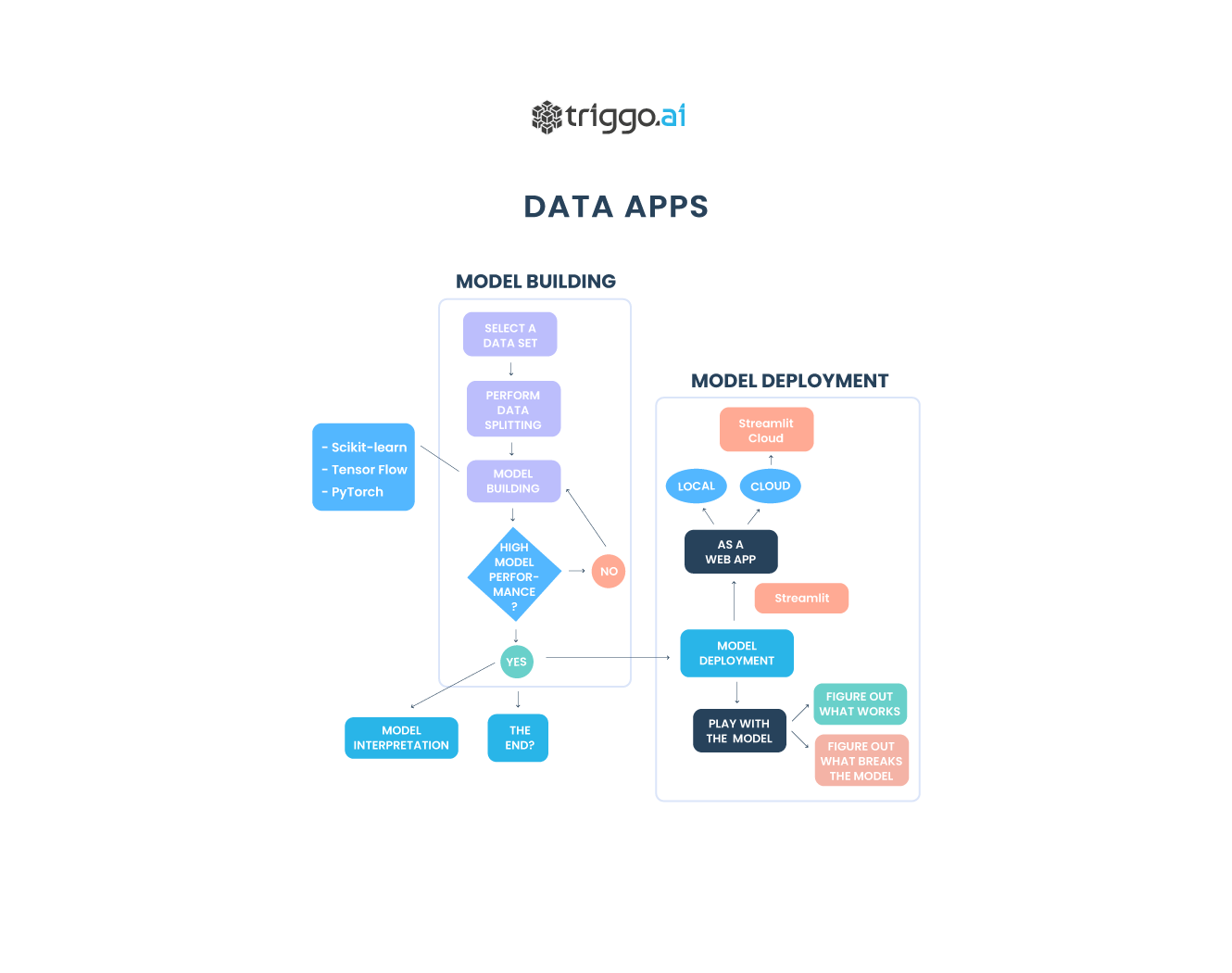
Este artigo aborda sobre a nova geração de ferramentas para a criação de Data Apps, que irá fornecer análise de dados colaborativa, interativa e, acima de tudo, realmente útil.
Este artigo aborda os tipos e as vantagens da produtização de dados (Data Products) para a maturidade de Data Analytics & AI.
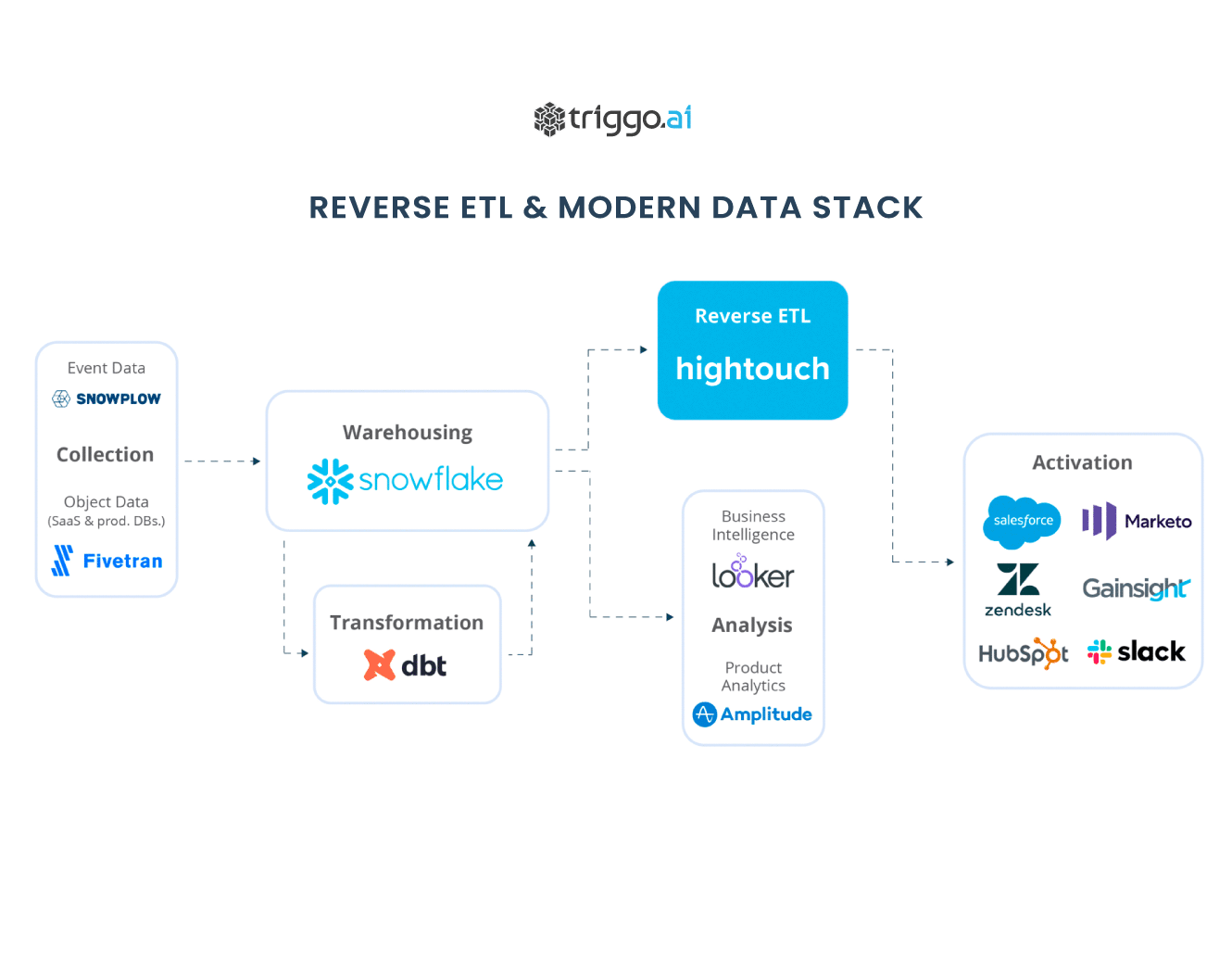
Esse artigo aborda as diferenças entre ETL e ETL reverso, apontando os ganhos com o uso de ferramentas flexíveis de pipeline, permitindo a combinação de dados de diversas fontes com o objetivo de aumentar a capacidade de inteligência do negócio.
Entenda como o Data Reliability Engineer ajuda a garantir que dados de alta qualidade estejam prontamente disponíveis em toda a organização e sejam confiáveis em todos os momentos.
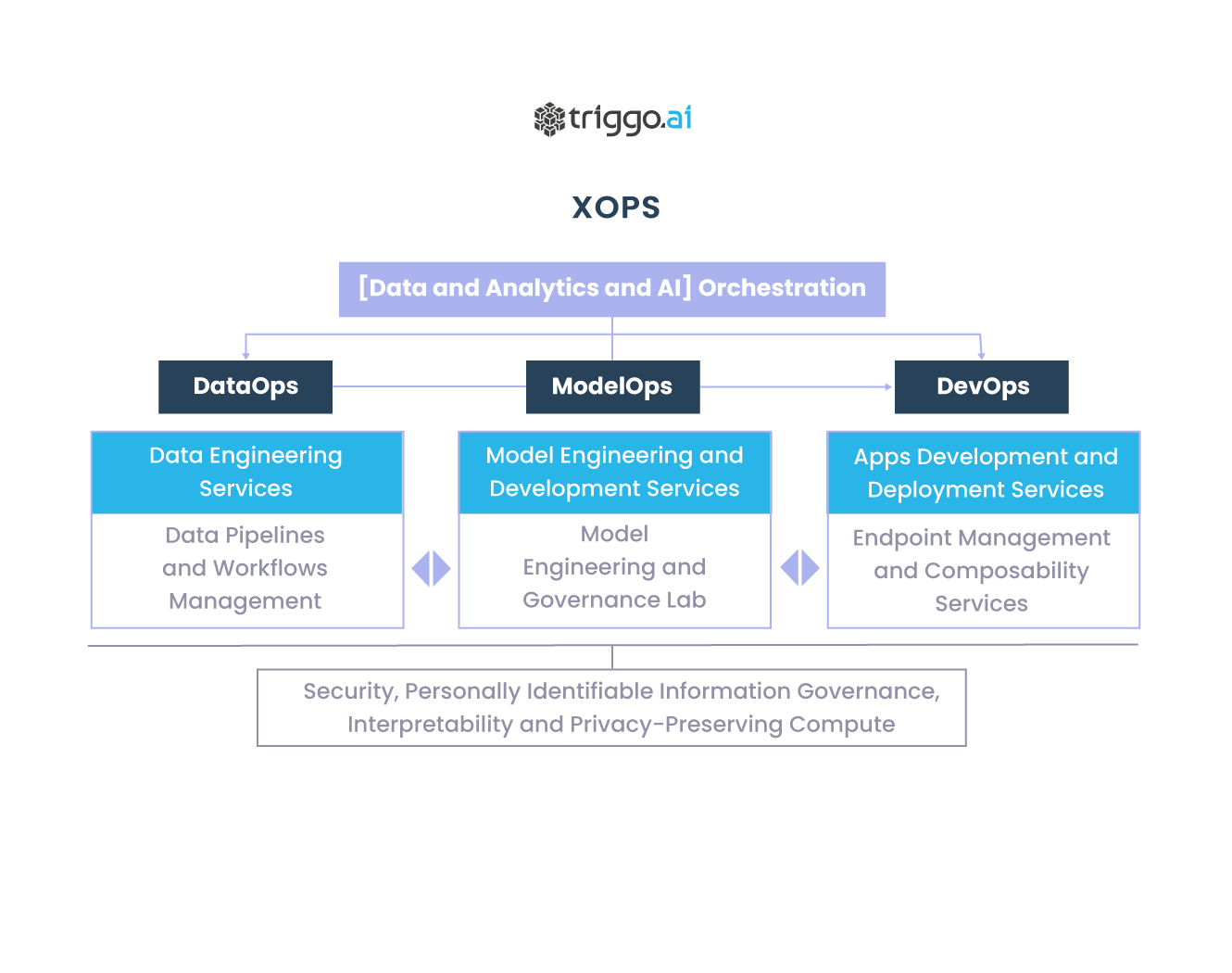
Este artigo aborda o conceito de XOps e como a sua aplicação pode ajudar a equalizar a maturidade de Data Analytics & AI, permitindo que as organizações operacionalizem dados e análises para gerar maior valor comercial.
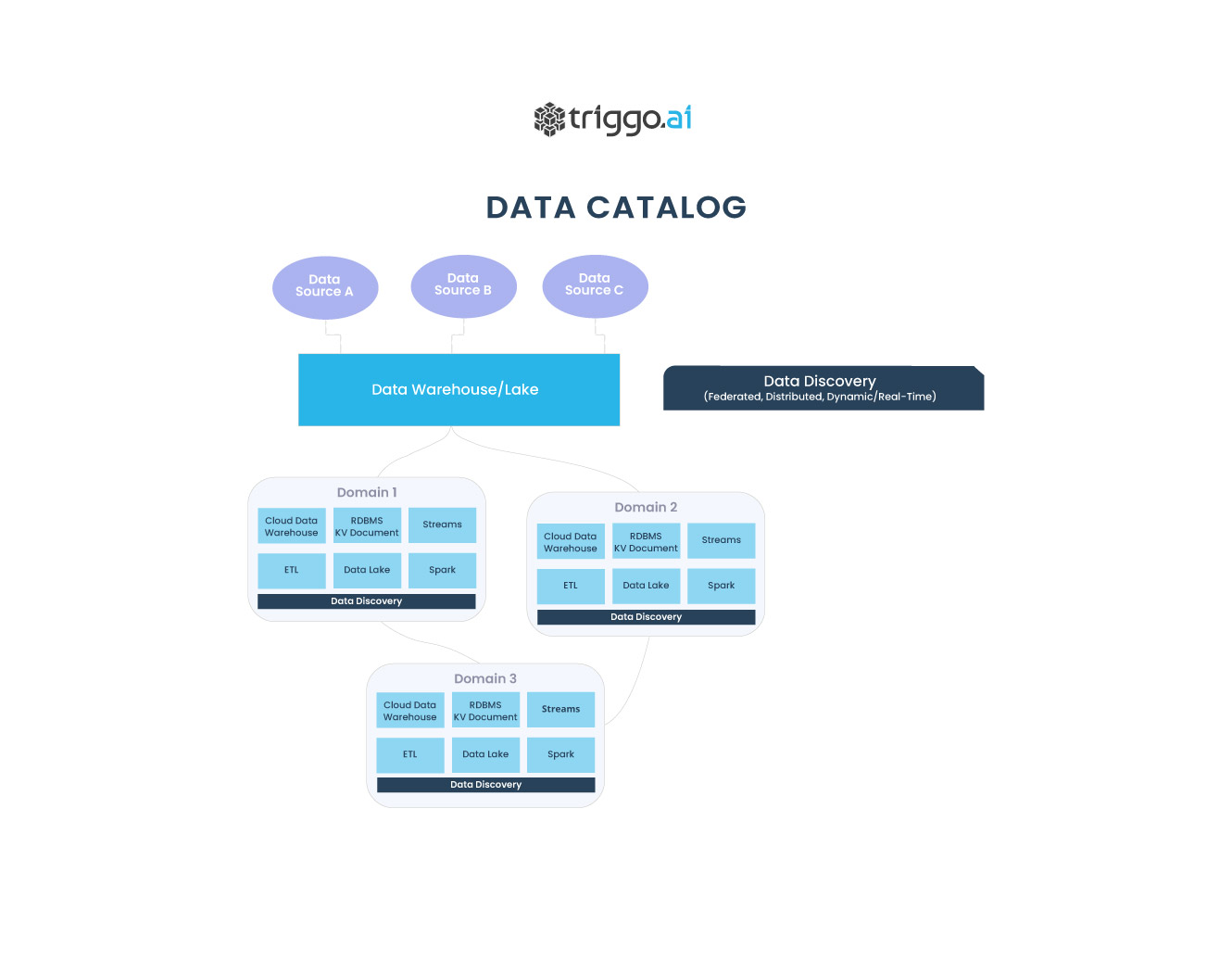
À medida que as operações de dados amadurecem e os pipelines se tornam cada vez mais complexos, os catálogos tradicionais geralmente não atendem os requisitos mínimos da sua função. Veja como o Discovery de dados pode suprir o catálogo de dados moderno.