Como definir a Qualidade dos Dados?
Uma das regras cruciais do uso de dados para fins comerciais é simples: a qualidade de suas decisões depende fortemente da qualidade de seus dados.
Para obter resultados tangíveis, você deve medir a qualidade de seus dados e agir com base nessas medições para melhorá-los.
Neste artigo, detalhamos problemas complicados de qualidade de dados e compartilhamos dicas sobre como resolvê-los com excelência.
Como definir qualidade de dados?
Seria correto começar esta seção com uma definição universalmente reconhecida de qualidade de dados. Mas aqui vem o primeiro problema: não há nenhuma!
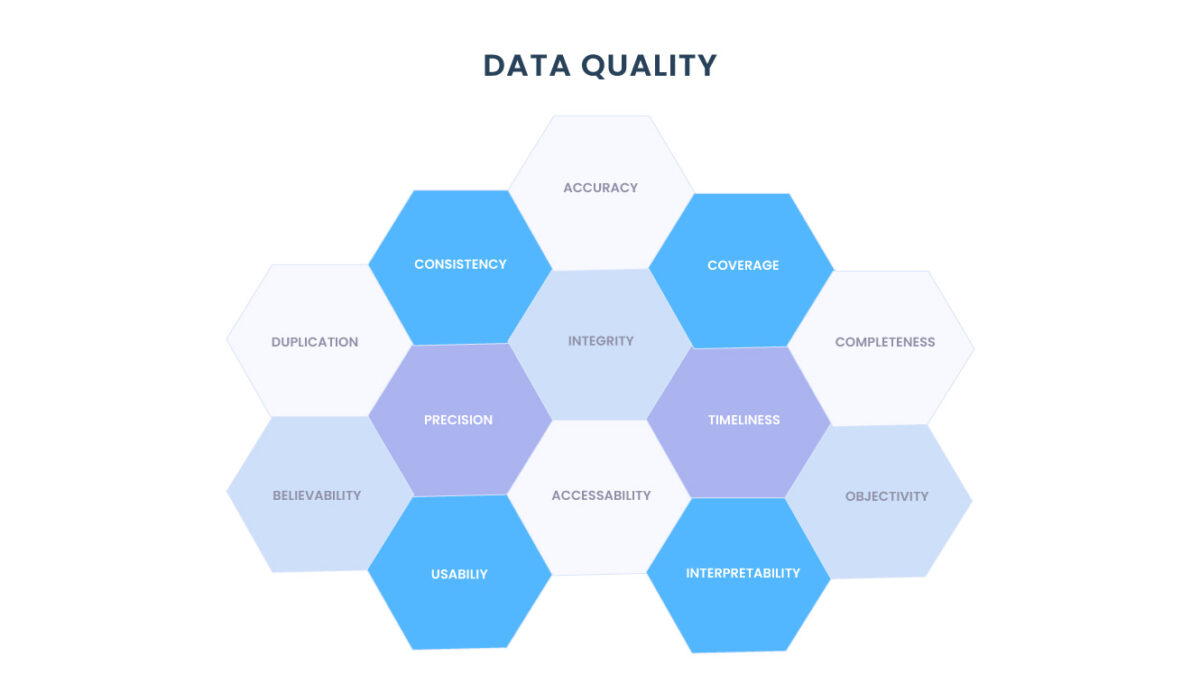
Este estado pode ser “bom” ou “ruim”, dependendo de até que ponto os dados correspondem aos seguintes atributos:
- Consistência;
- Precisão;
- Integridade;
- Auditabilidade;
- Ordem;
- Singularidade;
- Pontualidade.
Para revelar o que está por trás de cada atributo, considere esta tabela a seguir e a preencha com exemplos ilustrativos, baseados em dados de clientes. Também mencionamos amostras de métricas que podem ser escolhidas para obter resultados quantificáveis ao medir esses atributos de qualidade de dados.
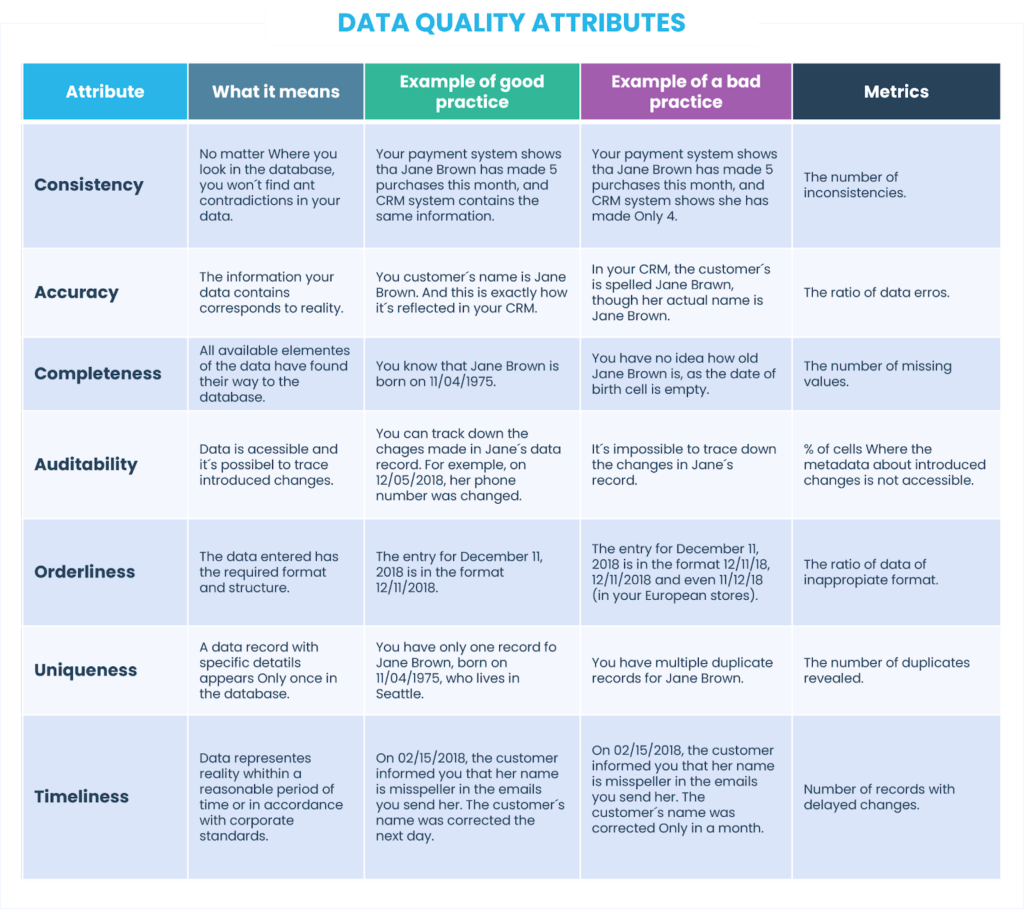
Uma observação importante: para big data, nem todas as características são 100% alcançáveis.
Por que a baixa qualidade dos dados é um problema?
Você acha que todo o problema da má qualidade dos dados é exagerado e os atributos considerados acima não valem a atenção que receberam? Vamos fornecer exemplos reais do impacto que dados de baixa qualidade podem ter nos processos de negócios.
Informação não confiável
Um fabricante acha que sabe a localização exata do caminhão que transporta seus produtos acabados do local de produção para o centro de distribuição. Eles otimizam o roteamento, estimam o tempo de entrega etc. E acontece que os dados de localização estão errados. O caminhão chega mais tarde e isso atrapalha o fluxo de trabalho normal do centro de distribuição. Sem falar nas recomendações de roteamento que se mostraram inúteis.
Dados Incompletos
Digamos que você esteja trabalhando para otimizar o gerenciamento da cadeia de suprimentos. Para avaliar fornecedores e entender quais são disciplinados e confiáveis e quais não são, você acompanha o prazo de entrega. Porém, ao contrário do horário de entrega agendado, o campo do horário de entrega real não é obrigatório em seu sistema e, naturalmente, os funcionários do seu depósito geralmente se esquecem de digitá-lo. Sem conhecer essas informações críticas (com dados incompletos), você não consegue entender como seus fornecedores atuam.
Interpretação de Dados Ambígua
Um sistema de manutenção de máquinas tem um campo chamado “Motivo da quebra” destinado a ajudar a identificar o que causou a falha. Normalmente, assume a forma de um menu suspenso e inclui a opção “Outro”. Como resultado, o relatório semanal pode dizer que em 80% dos casos a falha do maquinário foi causada pelo motivo “Outro”. Isso faz com que o fabricante experimente a baixa eficiência geral do equipamento sem ser capaz de aprender como melhorá-lo.
Dados Duplicados
À primeira vista, dados duplicados podem não representar um desafio. Mas, na verdade, isso pode se tornar um problema sério. Por exemplo, se um cliente aparecer mais de uma vez em seu CRM, ele não apenas ocupa espaço de armazenamento adicional, mas também leva a uma contagem incorreta de clientes. Além disso, dados duplicados enfraquecem a análise de marketing: desintegram o histórico de compras, consequentemente, tornam a empresa incapaz de entender as reais necessidades do cliente para uma segmentação adequada.
Informações Desatualizadas
Imagine que um cliente tenha respondido ao questionário de um varejista e afirmado que não tinha filhos. No entanto, o tempo passou e agora eles têm um bebê recém-nascido. Os pais felizes estão prontos para gastar seu orçamento em fraldas, comida para bebês e roupas, mas o varejista está ciente disso? Este cliente está incluído no segmento “Clientes com bebês”? A resposta é não para ambas as perguntas. É assim que dados obsoletos podem resultar em segmentação errada de clientes, conhecimento insuficiente do mercado e lucros abaixo do que poderia ter.
Entrada/Atualização de Dados Atrasada
Entradas e atualizações tardias de dados podem afetar negativamente a análise e os relatórios, bem como seus processos de negócios. Uma fatura enviada para o endereço errado é um exemplo típico para ilustrar o caso. E, para apimentar ainda mais a história, aqui está outro exemplo de rastreamento de ativos: o sistema pode informar que a betoneira está indisponível no momento apenas porque o funcionário responsável está várias horas atrasado para atualizar seu status.
Quer evitar as consequências da má qualidade dos dados?
As melhores práticas de gerenciamento de qualidade de dados
Como as consequências da má qualidade dos dados podem parecer perturbadoras, é fundamental saber quais são as soluções. Aqui, compartilhamos as melhores práticas que podem ajudá-lo a melhorar a qualidade de seus dados.
Tornar a qualidade dos dados uma prioridade
A primeira etapa é tornar a melhoria da qualidade dos dados uma alta prioridade e garantir que todos os funcionários entendam os problemas que a baixa qualidade dos dados traz. Parece bastante simples. no entanto, incorporar o gerenciamento de qualidade de dados aos processos de negócios requer várias etapas sérias:
- Projetar uma estratégia de dados em toda a empresa;
- Criar papéis de usuário claros com direitos e responsabilidade;
- Configurar um processo de gerenciamento de qualidade de dados (explicaremos isso em detalhes posteriormente neste artigo);
- Ter um painel para monitorar o status quo.
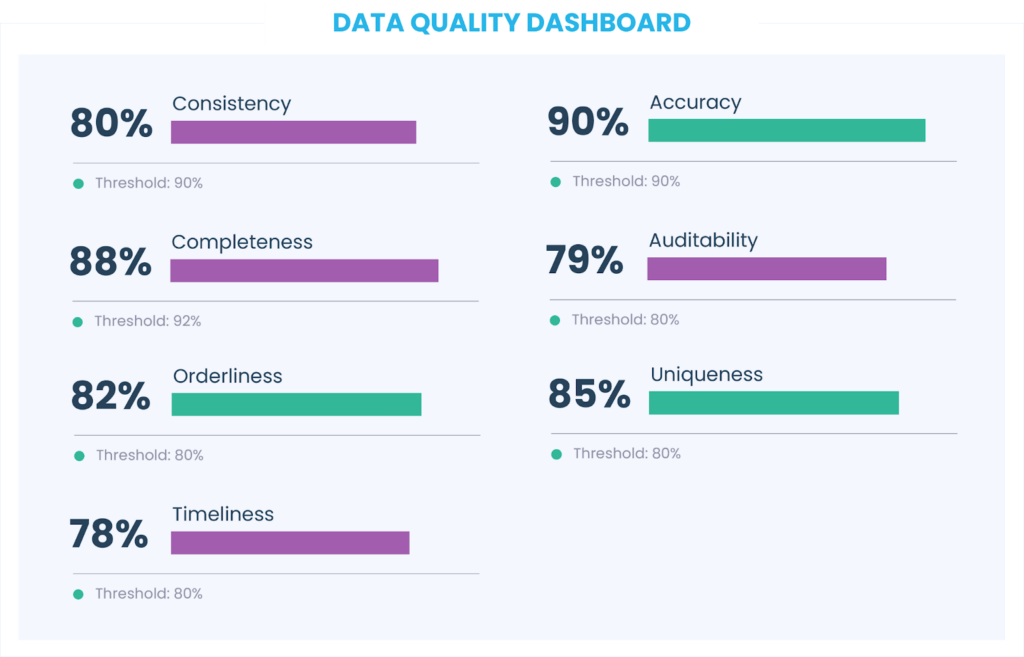
Automatizando a entrada de dados
Uma causa raiz típica para a baixa qualidade dos dados são as entradas manuais realizadas por funcionários, por clientes ou mesmo por vários usuários. Assim, as empresas devem pensar em como automatizar os processos de entrada de dados para reduzir o erro humano. Sempre que o sistema puder fazer algo automaticamente (por exemplo, preenchimento automático, registro de chamadas ou e-mail), vale a pena implementar.
Prevenir duplicatas, não apenas curá-las
Uma verdade bem conhecida é que é mais fácil prevenir uma doença do que curá-la. Você pode tratar duplicatas da mesma forma! Por um lado, você pode apenas limpá-las regularmente, mas, por outro lado, você pode criar regras de detecção de duplicatas que permitem identificar que já existe uma entrada semelhante no banco de dados proibindo a criação de outra ou sugerindo a fusão das entradas.
Cuidando dos mestres e dos metadados
Cuidar dos seus dados mestres é extremamente importante, mas você também não deve esquecer dos seus metadados. Por exemplo, sem os carimbos de data/hora que os metadados revelam, as empresas não poderão controlar as versões dos dados. Como resultado, eles poderiam extrair valores obsoletos para seus relatórios, em vez de valores atualizados.
Gerenciamento de qualidade de dados: etapas do processo descritas
O gerenciamento de qualidade de dados é um processo de configuração, que visa alcançar e manter alta qualidade de dados. Suas principais etapas envolvem a definição de limites e regras de qualidade, avaliação de qualidade de dados, resolução de problemas, monitoramento e controle de dados.
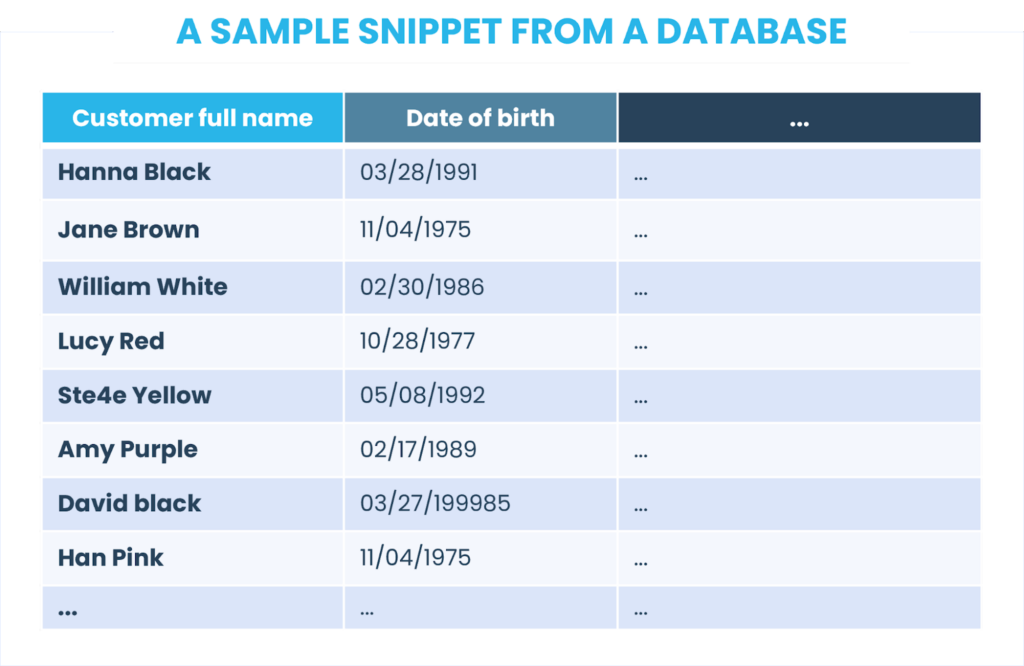
Para fornecer uma explicação mais clara possível, iremos além da teoria e explicaremos cada etapa com um exemplo baseado em dados do cliente. Aqui está um trecho de amostra de um banco de dados:
1. Definir limites e regras de qualidade de dados
Se você acha que há apenas uma opção dados perfeitos que são 100% compatíveis com todos os atributos de qualidade de dados (em outras palavras, 100% consistente, 100% preciso e assim por diante), você pode se surpreender ao saber que existem mais cenários do que este. Em primeiro lugar, atingir 100% em todos os lugares é um esforço extremamente custoso e intensivo, então normalmente as empresas decidem quais dados são críticos e se concentram em vários atributos de qualidade de dados que são mais aplicáveis para a sua realidade. Em segundo lugar, uma empresa nem sempre precisa de 100% de qualidade de dados, às vezes eles podem fazer muito progresso com o nível ‘bom o suficiente’. Em terceiro lugar, se você precisar de vários níveis de qualidade para vários dados, poderá definir vários limites para diferentes campos.
Neste momento, você pode ter uma pergunta: como medir se os dados atendem a esses limites ou não? Para isso, você deve definir regras de qualidade de dados.
Agora, quando a parte teórica acabou, vamos passar um exemplo prático.
Digamos que você decida que o campo de nome completo do cliente é crítico para o seu negócio e defina um limite de qualidade de 98% para ele, enquanto o campo da data de nascimento é de menor importância e você ficará satisfeito com o limite de 80%. Como próximo passo, você decide que o nome completo do cliente deve ser sempre preenchido e com precisão, e a data de nascimento deve ser válida (ou seja, deve estar de acordo com o atributo ordem). Como você escolheu vários atributos de qualidade de dados para o nome completo do cliente, todos eles devem atingir um limite de qualidade de 98%.
O próximo passo é definir as regras de qualidade de dados que você acha que abrangerão todos os atributos escolhidos. No nosso caso de exemplo, são os seguintes:
- O nome completo do cliente não deve ser N/A (para verificar se está completo);
- O nome completo do cliente deve incluir pelo menos um espaço (para verificar a precisão);
- O nome completo do cliente deve consistir apenas em letras, sem permitir números (para verificar a precisão);
- Apenas as primeiras letras do nome do cliente, nome do meio (se houver) e sobrenome devem ser maiúsculas (para verificar a precisão);
- A data de nascimento deve ser uma data válida que caia no intervalo de 01/01/1900 a 01/01/2010.
2. Avalie a qualidade dos dados
Agora, é hora de dar uma olhada em nossos dados e verificar se eles atendem às regras que estabelecemos. Então, começamos a criar perfis de dados ou, em outras palavras, obter informações estatísticas sobre eles. É assim que funciona: temos 8 registros individuais (embora seu conjunto de dados real seja certamente muito maior do que isso) que verificamos em nossa primeira regra O nome completo do cliente não deve ser N/A. Todos os registos cumprem a norma, o que significa que os dados estão 100% completos.
Para medir a precisão dos dados, temos 3 regras:
- O nome completo do cliente deve incluir pelo menos um espaço;
- O nome completo do cliente deve consistir apenas em letras, sem permitir números;
- Apenas as primeiras letras do nome do cliente, nome do meio (se houver) e sobrenome devem ser maiúsculas.
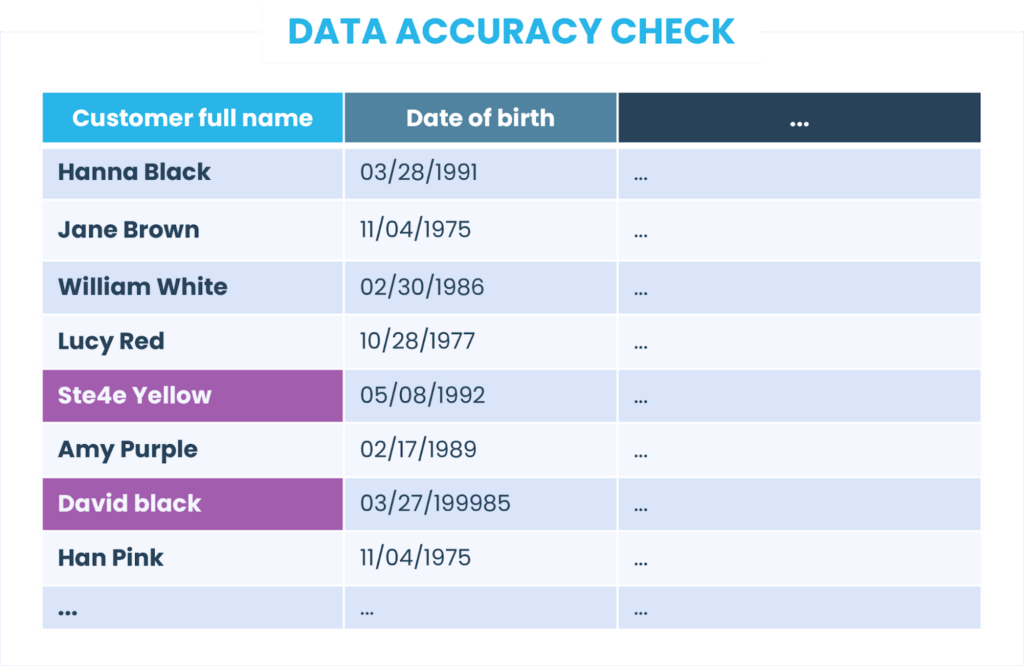
Novamente, fazemos o perfil de dados, para cada uma das regras, e obtemos os seguintes resultados: 100%, 88% e 88% (abaixo, destacamos os registros não conformes à regra de precisão dos dados). No total, temos apenas 92%, o que também está abaixo do nosso limite de 98%.
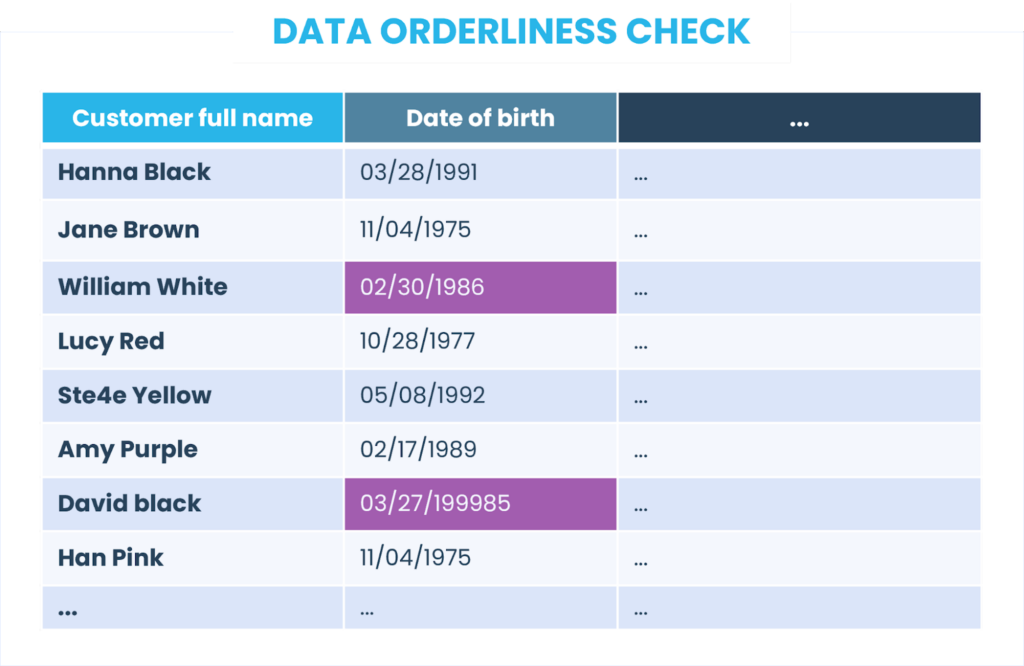
Quanto ao campo data de nascimento, identificamos dois registros de dados que não cumprem a regra definida. Portanto, a qualidade dos dados para esse campo chega a 75%, o que também está abaixo do limite.
3. Resolvendo problemas de qualidade de dados
Nesta fase, devemos pensar o que causou os problemas para eliminar sua causa raiz. Em nosso exemplo, identificamos falhas no campo de nome completo do cliente que podem ser resolvidas com a introdução de padrões claros para entradas manuais de dados, bem como indicadores-chave de desempenho relacionados à qualidade para os funcionários responsáveis por inserir dados em um sistema de CRM.
No exemplo com do campo data de nascimento, os dados inseridos não foram validados em relação ao formato ou intervalo de data. Como medida temporária, limpamos e padronizamos esses dados. Mas para evitar tais erros no futuro, devemos definir uma regra de validação no sistema que não aceitará uma data que não esteja de acordo com o formato e o intervalo.
4. Monitorando e controlando dados
O gerenciamento de qualidade de dados não é um esforço único, mas um processo ininterrupto. Você precisa revisar regularmente as políticas e regras de qualidade de dados com a intenção de melhorá-las continuamente. Isso é obrigatório, pois o ambiente de negócios está em constante mudança.
Digamos que um dia uma empresa opte por enriquecer os dados de seus clientes comprando e integrando um conjunto de dados externo que contenham dados demográficos. Então, provavelmente, eles terão que criar novas regras de qualidade de dados, já que um conjunto de dados externo pode conter informações com as quais eles não lidaram até agora.
Categorias de ferramentas de qualidade de dados
Para abordar vários problemas de qualidade de dados, as empresas devem considerar não uma ferramenta, mas uma combinação delas. Por exemplo, o Gartner nomeia as seguintes categorias:
- As ferramentas de análise e padronização dividem os dados em componentes e os trazem para um formato unificado;
- As ferramentas de limpeza removem entradas de dados incorretas ou duplicadas, além de modificarem os valores para atender a certas regras e padrões;
- As ferramentas de correspondência integram ou mesclam registros de dados intimamente relacionados;
- As ferramentas de criação de perfil coletam estatísticas sobre os dados e depois as usam para avaliação da qualidade dos dados;
- As ferramentas de monitoramento controlam o status quo da qualidade dos dados;
- As ferramentas de enriquecimento trazem dados externos e os integram aos dados existentes.
Atualmente, o mercado possui uma longa lista de ferramentas de gestão de qualidade de dados. O truque é que algumas delas se concentram em uma determinada categoria de problemas de qualidade, enquanto outras cobrem vários aspectos. Para escolher as ferramentas certas, você deve dedicar um tempo significativo à pesquisa ou deixar que consultores especialistas façam esse trabalho para você.
Gerenciamento ilimitado de qualidade de dados compactado em um parágrafo
O gerenciamento de qualidade protege você de dados de baixa qualidade que podem desacreditar totalmente seus esforços de análise. No entanto, para fazer esse gerenciamento corretamente, é preciso ter em mente muitos aspectos. Escolher as métricas para avaliar a qualidade dos dados, selecionar as ferramentas e descrever as regras e limites de qualidade dos dados são apenas algumas etapas importantes.
A triggo.ai é especialista em Data Analytics & AI, pioneira em Data Product e DataOps, e coloca a qualidade dos dados em primeiro plano para apioar sua empresa nesta jornada. Fale com um dos nossos especialistas!