
O que é AI Product
Temos visto claramente uma expansão acelerada de projetos e demandas de Inteligência Artificial nas organizações globais de todos os setores. Uma informação importante para iniciarmos este artigo é sobre a efetividade desta adoção de IA, que ainda é uma barreira para empresas que já estão na expectativa de resultados para o negócio.
“Mais de 85% dos modelos de machine learning desenvolvidos nas organizações não entram em produção!”
Se você pensou que alavancar a Inteligência Artificial era tão simples quanto implantar um chatbot em seu aplicativo, você pode ter uma surpresa negativa. Como, então, criar um produto de IA que as pessoas realmente usarão?
Considere a Alexa, a assistente pessoal da Amazon alimentado por IA de conversação. Em 2016, Jeff Bezos mencionou que “a combinação de algoritmos novos e melhores, o poder de computação muito superior e a capacidade de aproveitar grandes quantidades de dados de treinamento(…) estão se unindo para resolver problemas anteriormente insolúveis“.
Um avanço rápido de cinco anos e o dispositivo Alexa perdeu cerca de US $ 10 bilhões apenas em 2022, tornando-se o maior perdedor de dinheiro da Amazon.
Notamos que muitos algoritmos e modelos desenvolvidos aplicando data science, usando ferramentas como Jupyter, a partir de uma modelagem avançada de predições, correlações, visão computacional e linguagem natural estão avançando rapidamente em grandes organizações.
Este enorme gap entre o que é desenvolvido e o que de fato é aplicado no negócio efetivamente é o que propomos mitigar nesta abordagem, apresentado o método e os fundamentos de uma visão com AI Product.
Como um termo de alto nível, um “produto de IA” implica claramente em Inteligência Artificial como a tecnologia central em uma aplicação ou serviço, em vez de algo que seja meramente “semelhante à IA” ou uma reivindicação aspiracional sobre o que algo pode ser capaz de fazer em algum momento, ponto indefinido no futuro.
Um produto é um pacote de recursos que satisfaz um caso de uso: que se refere ao principal (ou principais) motivo pelo qual as pessoas escolhem seu produto. Os casos de uso são compostos por cinco perguntas:
- Qual problema você está resolvendo?
- Quem usa seu produto?
- Por que eles usam isso?
- Qual é a alternativa?
- Com que frequência eles o usam?
Vamos pegar uma equipe de produto da Amazon Fresh como exemplo: a equipe identifica, por meio de pesquisa com usuários, que os clientes gastam uma quantidade excessiva de tempo reabastecendo os mesmos itens em suas casas, resumido pelo caso de uso ‘Reabastecimento’ abaixo:

Qual é a diferença entre um produto AI/ML e um modelo AI/ML?
A IA na empresa hoje, geralmente, significa que uma organização está executando modelos de aprendizado de máquina na produção.
Um modelo ou mesmo dezenas ou centenas deles, no caso de equipes mais avançadas, não é um produto em si. Mas o que você faz com os resultados desse modelo pode se tornar um produto de IA.
Um serviço que analisa os dados meteorológicos existentes e faz uma previsão sobre a precipitação média é, certamente, um modelo de ML e, provavelmente, uma regressão ou uma rede neural. Um produto de IA incluiria painéis, fluxos de trabalho baseado em UX (front), MLOps (back), integrações prováveis e controles de usuário necessários (apenas para ilustrar um exemplo simples).
Após esta primeira introdução, vamos nos aprofundar.
Se você está se perguntando por onde começar, esperamos que este artigo ajude a obter respostas. Temos atuado com grandes empresas e, inclusive, desenvolvemos um treinamento específico de Data & AI Products Management que abrirá horizontes e poderá impulsionar sua carreira.
Vamos começar entendendo a seguinte questão: Por que precisamos de um guide específico para criar produtos de IA, em vez de tratá-lo de maneira semelhante à metodologias padrões de desenvolvimento de software?

Assim como faria em qualquer outro projeto, você quer ter a certeza de entender o que a tecnologia pode alcançar de forma realista, definir a experiência do usuário (UX) aprimorada por IA, planejar os esforços de sua equipe para criar os recursos do produto e lançar seu produto enquanto o ponto problemático do usuário é real. Mas quando seu projeto lida com Inteligência Artificial, o desafio é fazer tudo isso, com as restrições adicionais da tecnologia em rápida evolução, conhecimentos (escassos e caros) necessários para desenvolvê-lo e ser capaz de fornecer os recursos com um lançamento oportuno. Você também deseja evitar armadilhas dispendiosas de projetos de IA que podem acabar causando atrasos de meses ou, pior ainda, falha total do projeto.
Abaixo, listamos algumas características que são fundamentais para AI Product:
Proposta de Valor
O primeiro passo para começar a construir um produto de IA, como qualquer outro, é esclarecer o que estamos construindo.
Defina a proposta de valor do seu produto sem vinculá-la à Inteligência Artificial. Em vez disso, certifique-se de que o benefício que sua solução oferece ao usuário, em comparação com outros concorrentes, seja um argumento convincente para a IA.
Como qualquer produto ou recurso, partimos do ponto problemático do usuário e definimos a proposta de valor (propriedade de valor) que sua solução fornecerá ao usuário. No entanto, isso não está fundamentalmente ligado ao fato de você usar IA ou não. É muito importante que você perceba que a Inteligência Artificial está apenas aprimorando a proposta de valor, fornecendo um ou mais benefícios – reduzindo o custo para o usuário, fornecendo a solução mais rapidamente ou dimensionando para os diferentes usuários que você possui (ou seja, automação, assistência, ou personalização) e não a “pílula” principal que você está vendendo para os pontos problemáticos dos usuários. Para ser franco, o usuário não se importa se você usa IA ou não. Eles se preocupam com a “dor que estão vivendo” e se o seu produto o resolve essa dor com mais benefícios em comparação com outras soluções.
Dois passos são fundamentais para deixarmos como dica:
- Construa um Mínimo Produto Viável (MVP) para validação antecipada;
- Identifique os principais indicadores de desempenho para o produto.
Formule uma hipótese de produto 10x
Depois de priorizar seu(s) caso(s) de uso, considere como você pode aproveitar a IA para conduzir uma melhoria de mudança radical.
Aqui estão algumas categorias de proposições de valor habilitadas por Inteligência Artificial:
- Proatividade: você pode antecipar as necessidades do cliente?
- Personalização: é possível fornecer informações relevantes?
- Personalidade: você consegue injetar vida nas interações da marca?
- Automação: Há como reduzir o tempo e reduzir o esforço?
- Acessibilidade: existe a possibilidade de interações multimodais perfeitas?
O objetivo é identificar soluções que serão significativamente não incrementalmente melhores do que o status quo, a fim de superar os custos de mudança necessários para facilitar a formação de hábitos .
A equipe da Amazon apresenta algumas hipóteses para o caso de uso de reabastecimento:
“ Acreditamos que a retenção de assinaturas aumentará 100% se…
- …os usuários puderem ter a conveniência e economia de assinatura sem sentir que perderão o controle e acabarão com muitos itens;
- …os usuários forem solicitados proativamente a assinar seus itens comprados com frequência com uma projeção de economia de custos de um ano.”
Machine Learning & AI
A maneira como você enquadra o problema de ML resulta nos maiores ganhos no desempenho da solução e depois da proposta de valor bem definida este é o maior fator que contribui para o sucesso do projeto.
Identifique claramente as entradas para o seu modelo de ML e as saídas que você espera que sejam previstas, as entradas devem estar disponíveis no momento da inferência e deve ser possível para humanos anotar as saídas sem nenhum contexto além das entradas.
- Aprendizado Supervisionado: onde os humanos conhecem a relação entre a entrada e a saída, e podemos obter a saída anotada para nossas entradas sem nenhuma informação contextual além da que está presente na entrada. O modelo aprendido com esses dados se aproxima do julgamento humano e gera a saída dada uma entrada, assumindo que é semelhante aos exemplos nos quais é treinado;
- Aprendizado não supervisionado: onde a saída varia de acordo com os dados. Por exemplo, você pode querer agrupar suas entradas em grupos diferentes, mas não sabe o que os grupos devem ser – como encontrar segmentos de clientes, quais são os recursos mais importantes, etc;
- Aprendizagem por Reforço: onde você aprende uma política para prever uma ação com base em seu estado, mas em vez de ensinar o modelo como essa decisão é tomada, você sabe como pode recompensar ou penalizar as previsões do modelo, que você pode usar para o treinar simulando um mecanismo de aprendizado semelhante a um jogo, tornando o modelo mais robusto.
Escolha a técnica de ML (entre aprendizado supervisionado, aprendizado não supervisionado ou aprendizado por reforço) mais adequada para criar o modelo para sua solução de IA. Isso também ajuda a definir seus dados rotulados ou requisitos de plataforma de Machine Learning.
Um modelo raramente resolve completamente o problema de negócios e pode precisar ser dividido em problemas solucionáveis menores, empregar heurística ou lidar com exceções.
Machine Learning & UX
Antes de começarmos a construir os modelos, primeiro devemos estabelecer critérios de sucesso. A UX da sua solução é diretamente afetada pela precisão do modelo e pelo tempo de previsão da seguinte forma:
- Precisão: a precisão do modelo informa quantas solicitações de usuário este atenderá com sucesso;
- Tempo de Previsão: a UX pode ser inutilizada se o tempo de previsão for maior do que o que os humanos estão acostumados.
Foque nos benefícios mais importante para o usuário, bem como na escolha do algoritmo de ML correto, arquitetura de modelo etc.
As equipes de produtos estão acostumadas a interagir com um Canvas que é apenas uma ferramenta inicial para simplificar o processo da visão do todo e, principalmente, alinhando pessoas, estratégia, proposta de valor, fluxos, experiência, e outras.
Abaixo, um exemplo de Canvas voltado para Inteligência Artificial:
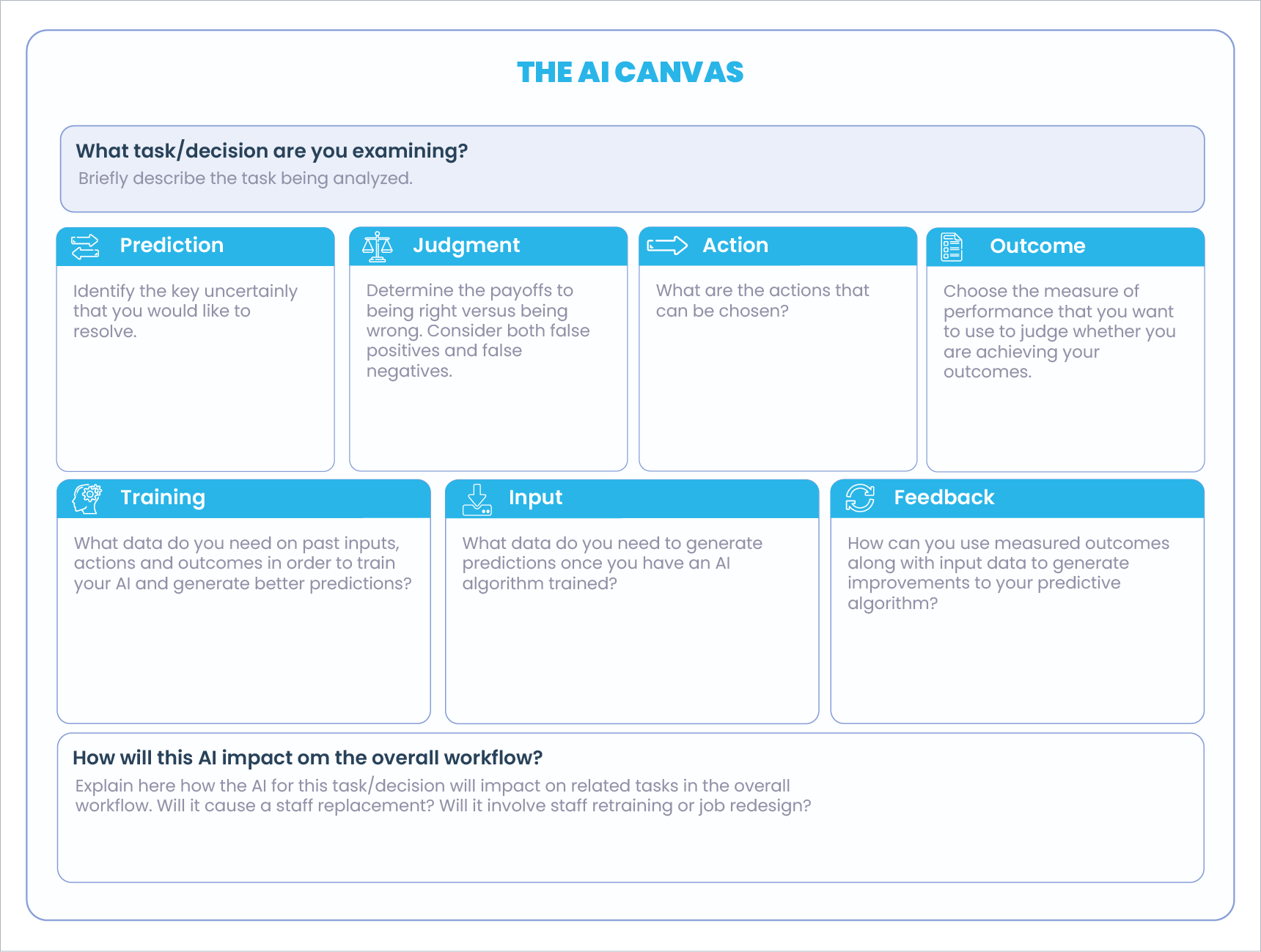
Pessoas e Recursos
O próximo passo é reunir uma equipe e prepará-la para o sucesso na construção do modelo.
Construir uma equipe de ciência de dados é difícil, a experiência é escassa e, como resultado, o mercado de trabalho é caro para contratar. Ao buscar talentos externamente, é muito difícil encontrar pessoas que tenham colocado modelos em produção.
Você precisará defender as habilidades de que precisa para contratar pessoas para sua equipe. Então, qual competência Data Science/ML é a certa para o seu projeto?
- Engenheiro de ML: para uma equipe de produto, a função de ciência de dados mais impactante a ser preenchida é um engenheiro de Machine Learning. Se o problema de ML puder ser enquadrado em um dos algoritmos e arquiteturas conhecidos, o profissional poderá treinar o modelo usando estruturas populares e empacotá-los para implantação. É necessário também ter um conjunto de habilidades secundárias de engenharia, o que é muito importante para mover os dados para treinar o modelo e colocá-lo em produção.
- Cientistas de Dados: se o seu produto precisa usar ML de uma maneira nova, que não tenha algoritmos e arquiteturas conhecidos, sua equipe deve ter um especialista em Visão Computacional, Processamento de Linguagem Natural, Aprendizado por Reforço, etc. que ajudará a criar a tecnologia para você. Lembre-se, essa função é pesada em pesquisa (pense em mestres, doutores, PhDs) e geralmente tem um ciclo de vida de criação de modelo que dura meses. Eu diria que um Cientista de Dados é extremamente crítico para o sucesso apenas quando você está criando Propriedade Intelectual em IA à qual seus concorrentes não deveriam ter acesso. Mas, nesse ponto, você deve investigar os cronogramas de seus produtos, talvez você esteja em um estágio de pesquisa e a tecnologia não esteja pronta para o horário nobre.
- MLOps: uma função emergente recentemente na qual o profissional de MLOps lida com a implantação e manutenção dos modelos em produção. Pense em MLOps como uma função dentro de DevOps especializada na implantação de seus modelos. O escopo dessa função deve manter os serviços de previsão do modelo de Machine Learning saudáveis e com bom desempenho.
- Outros Engenheiros: finalmente, tão importante quanto as funções de Ciência de Dados acima, sua equipe também deve contar com os Engenheiros de Front-end (para criar a UI/App), Back-end (a lógica de negócios e os serviços necessários para mover os dados) e Engenheiros DevOps (para implantar e manter os modelos e servidores back-end em produção).
Embora seja difícil construir uma equipe de Ciência de Dados, é necessário o equilíbrio certo entre todos os profissionais envolvidos (Cientistas de Dados, Engenheiros de ML, Operações de ML e outros engenheiros) para garantir que você tenha o conjunto de habilidades e conhecimentos certos para concretizar sua solução.
Plataforma & Dados
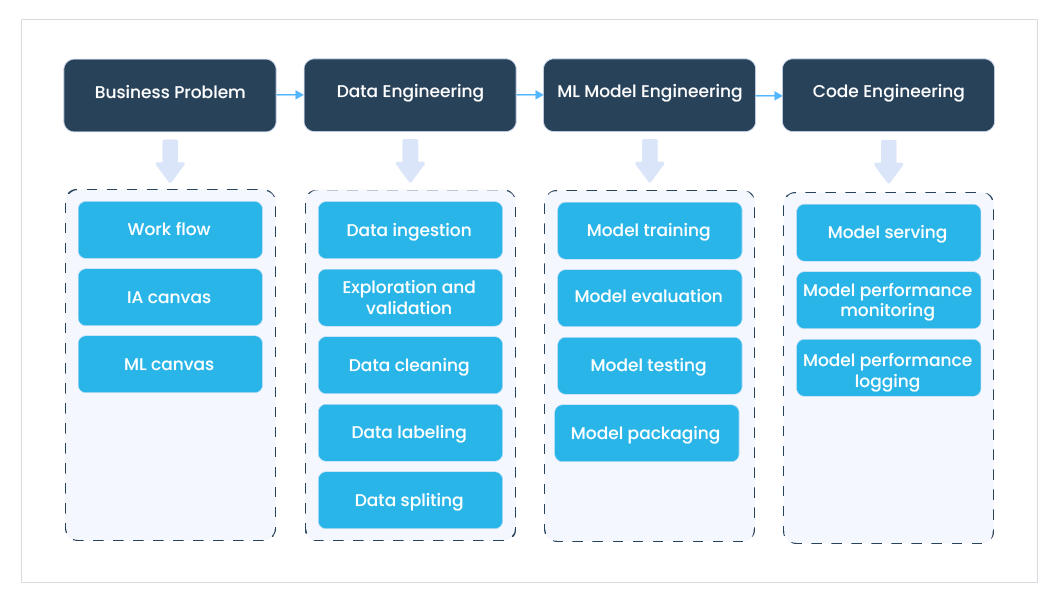
A imagem acima talvez traduza bem a diferença entre criar um modelo de Machine Learning no Jupyter e de fato criar um produto de Inteligência Artificial. Perceba que é um caminho bem complexo envolvendo muitas etapas e componentes.
Juntamente com as pessoas e os dados necessários para treinar seu modelo, você precisa ter certeza de que está escolhendo a plataforma certa para suas necessidades.
A escolha de uma plataforma afeta sua flexibilidade de criar a solução de IA necessária para fornecer uma UX bem-sucedida, em contraste com a velocidade com que você pode lançar o modelo ou a equipe/recursos necessários para iniciá-lo sozinho.
Cada empresa deverá encarar seu desafio com a perspectiva da estratégia que mais se adequa ao seus investimentos, pessoas e prazos.
O desenvolvimento usando uma plataforma requer atenção à matéria prima principal, que são os dados.
Quais são as fontes de dados que você usará para treinar seu modelo?
Depois de “Enquadrar o problema de ML”, sua fonte de dados tem o maior impacto no desempenho do modelo. Portanto, é muito importante garantir que você tenha os dados corretos para as entradas e saídas do seu modelo.
- Entradas para o modelo: não há outra maneira de contornar isso: faça com que seus dados de treinamento estejam o mais próximo possível dos dados em produção. Por exemplo, para um caso de uso de Visão Computacional a câmera usada para capturar a imagem, sua posição, movimento, condições de iluminação, etc. precisam corresponder exatamente ao ambiente de produção.
- Saídas do modelo: se você estiver usando uma técnica de Aprendizado Supervisionado, precisará de dados anotados para as saídas do modelo para treiná-lo. A rotulagem de dados é cara e, embora várias empresas ofereçam serviços para anotações (a maioria de países em desenvolvimento em todo o mundo, onde a mão de obra é barata), você precisa escolher uma que tenha fortes verificações de qualidade. Você também precisa estar ciente da privacidade de dados, segurança e outras preocupações sobre pessoas que fazem uso indevido dessas informações. Os dados rotulados geralmente são mais valiosos do que o próprio modelo, principalmente porque qualquer concorrente que tenha acesso aos seus dados rotulados poderá criar uma oferta de produto semelhante, mas um concorrente sem seus dados não pode fornecer os mesmos benefícios ao usuário.
Os dados são o combustível com o qual seu modelo aprende e não há nada melhor que o uso de dados para treinamento que foram capturados exatamente nas mesmas condições do ambiente de produção. No lado da saída do modelo, obter dados inequívocos e de alta qualidade é mais importante do que gastar tempo melhorando o próprio modelo.
Agilidade
Idealmente, depois de validar um MVP, você deve apontar inicialmente para uma cadência de releases mensais e, em seguida, seguir os padrões predominantes do scrum, uma vez a cada sprint. Mais do que isso, você corre o risco de tornar sua exploração de modelo muito “pesquisa”. A cada iteração, você pode progredir melhorando seu UX aprimorado por IA, expandindo a fatia de recursos fornecidos, melhorando o desempenho do modelo e treinando-o com melhores dados.
Como parte de seu ciclo enxuto, o feedback que você obtém de seus clientes é valioso para identificar se sua proposta de valor e os benefícios que você está fornecendo são o que o usuário precisa. Qualquer validação ou invalidação, qualquer alteração no UX, direciona as alterações para os modelos, dados, etc. Caso contrário, você corre o risco de gastar uma quantidade considerável de tempo, dinheiro e recursos resolvendo um problema que não é mais relevante.
O próprio treinamento do modelo é um processo iterativo. Cada uma das técnicas de aprendizado não supervisionado, supervisionado e por reforço tem vários algoritmos dos quais sua solução pode se beneficiar. Seu cientista de dados ou engenheiro de ML deve otimizar os pipelines de treinamento para que seu tempo de experimentação seja reduzido e a tomada de decisões seja o mais orientada por dados possível. Controlar a versão do modelo, ter uma métrica de referência em seu conjunto de dados de teste a ser superado para colocar um novo modelo em produção, estabelecer um CI/CD para o código do modelo e a lógica de negócios são otimizações operacionais importantes necessárias para tornar isso o mais fácil possível.
É importante que você melhore gradativamente seu modelo na produção. Ao iterar rapidamente em seu produto e validar/invalidar sua proposta de valor e recursos rapidamente, você pode garantir que trabalhará continuamente para fornecer benefícios aos usuários e valor às partes interessadas.
Para resumir as principais conclusões:
Criar um modelo de Machine Learning já é uma realidade para as organizações, porém colocar em produção ainda não. Este processo é árduo e um modelo validado, passando por todas as fases e entrando em produção com visão de produto, leva em média 12 meses no método tradicional, isso não é escalável.
Tudo leva a entendermos a necessidade e a importância para a abordagem Data & AI Product.
- A IA sozinha não pode atrapalhar seus negócios, mas seus concorrentes que utilizam Inteligência Artificial definitivamente podem;
- A IA evoluirá exponencialmente a cada ano , portanto, a adoção antecipada é crucial;
- Produtos de IA para o negócio requererem avaliação de onde seu produto de fato se enquadra na proposta de valor.
A triggo.ai é uma startup especializada em Data & AI Products e pode ajudar a sua empresa a atingir melhores resultados nesta corrida. Fale com um de nossos consultores especialistas!


