
Data Product Management: uma abordagem sobre a camada semântica
No mundo impulsionado por dados, a gestão eficiente desses ativos se tornou um diferencial competitivo essencial. Nesse contexto, o Data Product Management (Gestão de Produtos de Dados) emerge como uma prática central para maximizar o valor dos dados e entregar soluções baseadas em dados que atendam necessidades de negócios específicas.
Para quem está iniciando essa jornada agora, recomendamos começar com este outro artigo: O que é um Data Product.
O Data Product Management visa gerenciar dados como produtos ao longo de todo o seu ciclo de vida, desde a concepção até a entrega, passando por desenvolvimento e operações. Diferente de uma abordagem puramente técnica, o foco está em alinhar dados e insights com resultados de negócios tangíveis. Isso permite:
- Maior valor de negócios: através de dados de alta qualidade que suportam decisões informadas;
- Time-to-market mais rápido: processos otimizados permitem que produtos de dados cheguem mais rápido ao mercado;
- Governança e conformidade aprimoradas: com práticas robustas de gerenciamento, a conformidade com regulamentações é garantida.
No contexto de produtos de dados, uma camada semântica pode ser comparada a um guia turístico em uma cidade desconhecida. Imagine que os dados são as ruas, prédios e pontos de interesse espalhados por uma cidade gigante e complexa. Embora você possa percorrer as ruas por conta própria, sem conhecer a história ou a importância de cada local, sua experiência seria limitada e muitas vezes confusa. O guia turístico, neste caso, é a camada semântica — ele não apenas te mostra o caminho, mas também dá contexto, significado e explicações sobre o que você está vendo.
Sem o guia, você até conseguiria se locomover, mas perderia informações valiosas sobre o que torna cada ponto especial, como os lugares estão conectados e qual é a melhor maneira de explorar a cidade de acordo com seus interesses. Com o guia (ou seja, a camada semântica), você entende o propósito por trás de cada dado, como ele se relaciona com outros, e é capaz de navegar com mais eficiência e clareza.
Assim como o guia turístico adapta suas explicações dependendo do tipo de visitante (um historiador, um arquiteto ou um turista casual), a camada semântica adapta o uso dos dados de acordo com o contexto de quem está consumindo: seja um analista de negócios, um cientista de dados ou um executivo. Ela garante que todos possam explorar os dados com a mesma compreensão e precisão, independentemente do nível de familiaridade com o “terreno”.
Camada semântica: o core do Data Product
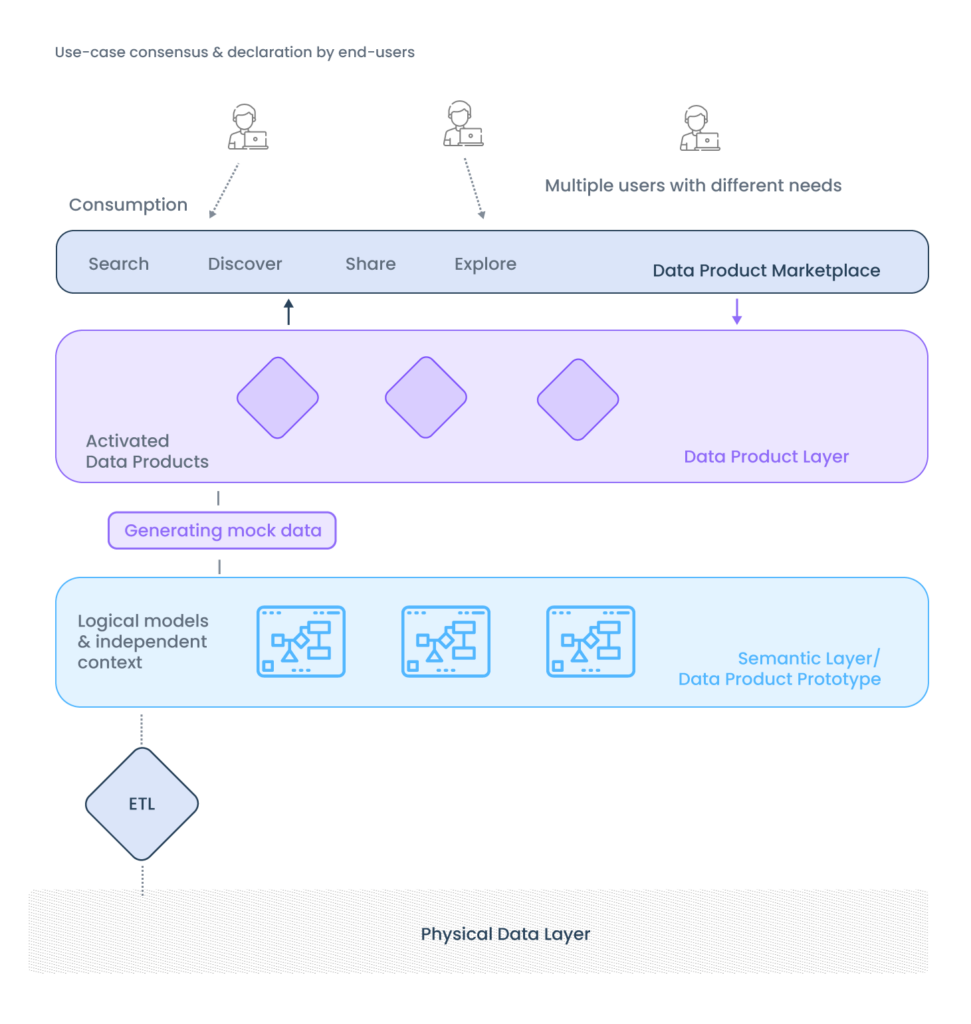
A camada semântica é o core (coração dos produtos de dados) que confere significado e contexto aos dados, permitindo que as partes interessadas compreendam seu valor. Embora o termo “camada semântica” sugira uma camada estática na stack de dados, na realidade ela funciona como uma consciência distribuída que atravessa todas as camadas de um produto. Esta abordagem distribui o contexto por diferentes pontos de contato e é central para o sucesso da solução. Sem uma camada semântica robusta, a reutilização e a interoperabilidade entre produtos de dados podem ser comprometidas.
Sendo crucial para garantir que os dados não sejam apenas consumidos, mas entendidos no contexto adequado, ela proporciona um entendimento comum do que os dados representam, ajudando as organizações a garantir consistência no uso e interpretação de informações ao longo de diferentes partes do negócio.
Semântica, no contexto de produtos de dados, refere-se à criação de contexto e significado ao redor dos dados. Isso inclui aspectos como a descrição, linhagem, relações entre entidades de dados, políticas, condições de qualidade e até mesmo as inter-relações entre diferentes conjuntos de dados. Assim, a camada semântica serve como um “guia” para que os consumidores de dados possam usá-los de maneira eficaz e sem ambiguidades.
Semântica distribuída: uma nova perspectiva
Embora o termo “camada semântica” seja amplamente utilizado, sua concepção vai além de um simples “nível” na arquitetura de dados. Tradicionalmente, muitas organizações viam a semântica como uma camada horizontal que tratava da organização e categorização dos dados. No entanto, a semântica moderna é vista como algo mais dinâmico, funcionando como uma camada distribuída ao longo da stack de dados (semantic layer). Ela permeia todas as camadas do produto de dados, incluindo as portas de entrada, processos de transformação e até as interfaces de consumo de dados.
Essa abordagem distribuída proporciona contexto ao longo de todo o ciclo de vida do dado, desde a origem até o consumo final. Por exemplo, ao gerar um dado de vendas, o contexto semântico pode incluir detalhes sobre a qualidade do dado, sua linhagem (de onde ele veio), e como ele se relaciona com outros dados no domínio, como marketing ou financeiro. Isso é crucial para garantir que todos os stakeholders possam acessar, usar e interpretar os dados corretamente.
Vantagens da camada semântica para a Arquitetura da Informação
A camada semântica oferece escalabilidade e reutilização de componentes de dados. Sem uma arquitetura semântica robusta, os times de dados podem acabar criando soluções redundantes ou duplicando esforços, o que pode levar à ineficiência operacional. Ao contrário de abordagens ad hoc, a camada semântica permite a construção incremental da arquitetura de dados, onde novos produtos de dados podem ser desenvolvidos reutilizando componentes semânticos existentes, como dimensões ou medidas.
Essa reutilização se torna particularmente útil quando se considera a necessidade de diferentes domínios da empresa consumirem os mesmos dados, mas com contextos e propósitos distintos. Por exemplo, uma equipe de marketing pode estar interessada em um conjunto de dados de clientes com foco em comportamento de compra, enquanto a equipe financeira pode usar os mesmos dados para entender padrões de receita. A camada semântica assegura que, mesmo com diferentes visões, os dados são interpretados e utilizados de forma consistente.
Semântica centralizada e distribuída: o híbrido ideal
A semântica eficaz exige um equilíbrio entre centralização e distribuição. Por um lado, é necessário ter uma centralização em sistemas como um grafo de conhecimento (Knowledge Graph), que serve como um repositório comum onde todos os metadados semânticos são armazenados e compartilhados. Esse grafo pode conectar dados de diferentes produtos, permitindo a interoperabilidade entre sistemas e assegurando que o conhecimento seja acessível em toda a organização.
Por outro lado, há um forte componente de contexto distribuído que ocorre localmente nos próprios produtos de dados. O contexto distribuído permite que a semântica seja aplicada no ponto em que o dado está sendo gerado ou consumido. Um exemplo seria um analista de vendas que adiciona uma tag ou anotação específica a um conjunto de dados relacionado a campanhas de marketing. Essa anotação pode ser utilizada por outros produtos de dados relacionados, mesmo que os objetivos de marketing e vendas sejam diferentes.
Desafios e considerações para implementar a camada semântica
Implementar uma camada semântica robusta em uma organização pode ser desafiador. Algumas das principais dificuldades incluem:
- Complexidade técnica: a integração de diferentes sistemas, catálogos de dados, glossários de negócios e grafos de conhecimento requer uma arquitetura bem planejada;
- Mudança cultural: a transição para uma visão semântica distribuída pode exigir uma mudança de mentalidade dentro das equipes de dados, que tradicionalmente podem ter se concentrado apenas em aspectos técnicos sem considerar o impacto do contexto;
- Manutenção e atualização contínuas: a semântica não é estática; ela deve evoluir à medida que os dados e as necessidades de negócios mudam.
Ainda assim, apesar dos desafios, a camada semântica é fundamental para garantir que os produtos de dados tenham escalabilidade, reutilização e interoperabilidade, tornando a arquitetura da informação uma verdadeira vantagem competitiva. Sem esse alicerce, os produtos de dados podem se tornar fragmentados, perdendo eficácia e valor a longo prazo.
AI Augmentation para escalar Data Products e sua relação com a camada semântica
A utilização de Inteligência Artificial (IA) para ampliar e escalar produtos de dados tem se tornado uma prática indispensável no cenário atual, à medida que as empresas buscam maneiras mais eficientes e automáticas de lidar com o crescente volume e complexidade dos dados. A camada semântica desempenha um papel crítico nesse processo, pois ela fornece o contexto e o significado necessários para que a IA funcione de maneira mais eficaz na automação e no entendimento dos dados.
Automação e contextualização com IA na camada semântica
A camada semântica, ao fornecer um modelo estruturado e contextualizado dos dados, permite que a IA compreenda as inter-relações entre diferentes conjuntos de dados e as regras de negócios associadas a eles. Quando uma IA é usada para ampliar um produto de dados, ela depende dessa camada para obter informações enriquecidas sobre a natureza dos dados, como descrições, tags, sinônimos e relações entre entidades.
Por exemplo, ao utilizar IA para criar recomendações automáticas em um marketplace de produtos de dados, a camada semântica pode fornecer as informações necessárias para que o algoritmo de IA compreenda quais produtos são mais relevantes para determinados contextos de negócio. Essa contextualização garante que as recomendações sejam precisas e alinhadas com as necessidades específicas dos usuários.
A IA também pode facilitar a geração automática de métricas, utilizando o entendimento semântico para sugerir novas combinações de medidas e dimensões baseadas em dados históricos ou predefinições semânticas. Isso não apenas acelera a criação de produtos de dados, mas também melhora a qualidade e a relevância das informações geradas.
Aceleração da criação de modelos semânticos e protótipos com IA
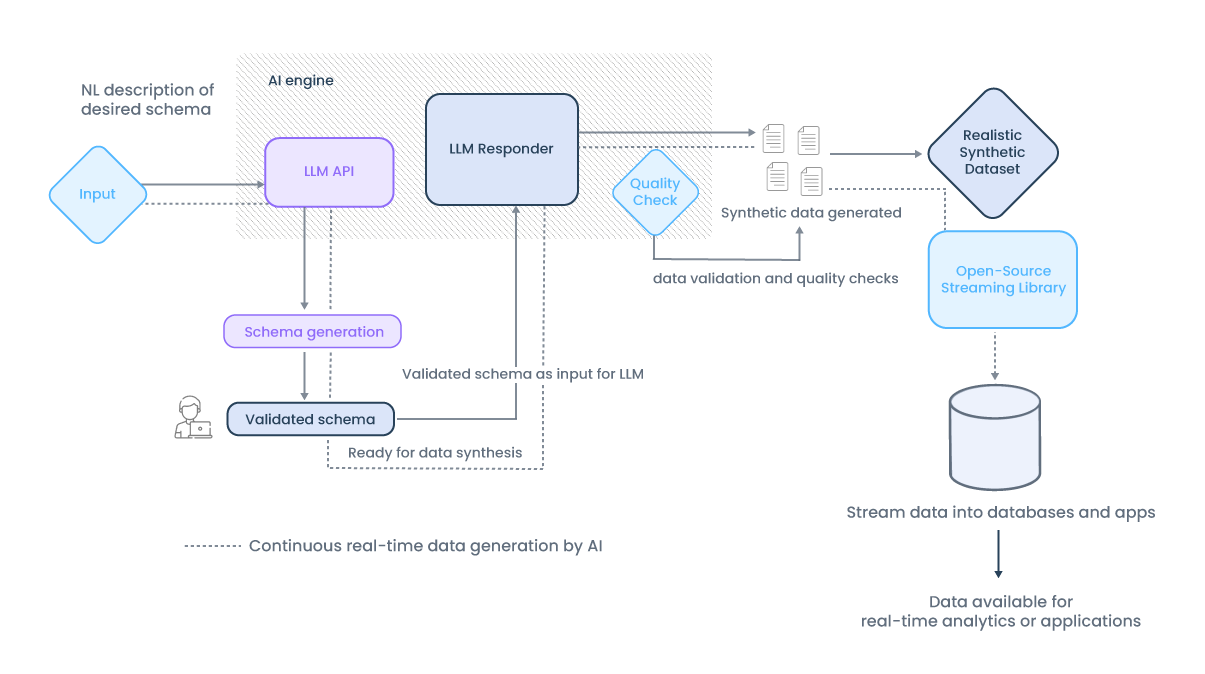
Uma das principais contribuições da IA na criação de produtos de dados é a aceleração dos processos de prototipagem e modelagem semântica. Quando se trata de construir um novo produto de dados, a IA pode ajudar a superar o problema da “folha em branco”, que muitas vezes impede os analistas de iniciar um projeto. Através de algoritmos de IA, como os modelos de linguagem natural (LLMs), é possível gerar automaticamente árvores de métricas e modelos lógicos com base no contexto semântico existente.
Esses modelos gerados por IA podem sugerir associações entre entidades de dados e fornecer descrições e tags automáticas, baseadas em padrões extraídos de outros produtos de dados ou domínios de negócio. Isso facilita a criação de novos produtos de dados e melhora a velocidade de desenvolvimento. A IA também pode auxiliar na validação de protótipos, criando dados simulados (mock data) para testar as hipóteses de design antes da implementação em produção.
IA no ciclo de vida de Produtos de Dados: de dados brutos a insights refinados
O impacto da IA ao longo do ciclo de vida de produtos de dados é vasto, e a camada semântica desempenha um papel de facilitador essencial para garantir que a IA trabalhe com dados contextualizados desde a origem até o consumo. A IA pode ser usada para:
- Automatizar processos de ingestão de dados, interpretando a semântica associada a diferentes fontes de dados, como APIs, bancos de dados ou sistemas de telemetria;
- Realizar transformações automáticas em dados brutos com base nas regras semânticas, aplicando agregações, normalizações e enriquecimentos específicos de domínio;
- Gerar insights personalizados para diferentes usuários, aproveitando o entendimento semântico para adaptar a experiência do usuário final de acordo com o contexto dos dados consumidos.
Por exemplo, um sistema de IA pode usar a camada semântica para ajustar automaticamente as transformações de dados aplicadas a diferentes domínios. Em um caso de uso de otimização de rotas, a IA pode aplicar previsões de tráfego com base nos padrões históricos capturados na semântica dos dados de localização, permitindo otimizações em tempo real sem intervenção humana.
Recomendações automatizadas e personalização de experiência
A personalização é um dos principais benefícios trazidos pela combinação de IA e camada semântica. Ao integrar o contexto semântico com algoritmos de IA, as empresas podem oferecer uma experiência mais personalizada para os usuários, sugerindo produtos de dados, relatórios ou métricas que sejam mais relevantes para o seu papel ou função dentro da organização.
Essa abordagem é comparável a plataformas de e-commerce, onde a IA recomenda produtos baseados em interações anteriores e nas preferências do usuário. No contexto de produtos de dados, a camada semântica ajuda a IA a compreender a função do usuário (por exemplo, analista de vendas ou gerente de marketing) e a sugerir produtos de dados ou insights que sejam particularmente valiosos para suas atividades.
Redução de resistências culturais e de mudança
Outro benefício importante da IA, especialmente em conjunto com a camada semântica, é a capacidade de reduzir as resistências culturais em torno da adoção de novas tecnologias e processos. Muitos dos desafios enfrentados por organizações na adoção de produtos de dados estão relacionados a mudanças culturais e resistência à inovação, especialmente em ambientes que ainda operam com sistemas legados.
A IA pode atuar como um facilitador, simplificando processos complexos e aliviando as barreiras de adoção ao automatizar tarefas que tradicionalmente exigiriam esforço manual ou treinamento especializado. Ao tornar o uso e a interação com produtos de dados mais intuitivos e naturais, a IA, junto com a camada semântica, ajuda a suavizar a transição para uma cultura orientada por produtos de dados.
A integração entre IA e a camada semântica é essencial para a escalabilidade dos produtos de dados, pois fornece o contexto necessário para que a IA opere de maneira eficiente e eficaz. A camada semântica atua como uma “cola” que conecta diferentes partes da stack de dados e permite que a IA faça recomendações, automatize processos e acelere o desenvolvimento de novos produtos de dados. Com essa combinação, as empresas podem não apenas escalar suas operações, mas também personalizar as experiências e otimizar a tomada de decisões em toda a organização.
Conclusão
O Data Product Management é uma abordagem essencial para organizações que desejam maximizar o valor dos seus dados e transformar insights em resultados de negócios. A combinação de uma camada semântica robusta, componentes operacionais bem definidos e a utilização de IA para escalar processos, forma a base para o sucesso dos produtos de dados. Organizações que adotam essa prática não só melhoram a qualidade e eficiência de seus dados, mas também transformam sua cultura, promovendo a inovação e a tomada de decisões orientadas por dados.
Se você quiser entender melhor como Data Products pode mudar a forma como os dados são tratados e vistos na sua empresa, clique aqui. Somos especializados em construir Data Products confiáveis e soluções analíticas e estamos prontos para ajudar você nesta jornada.


