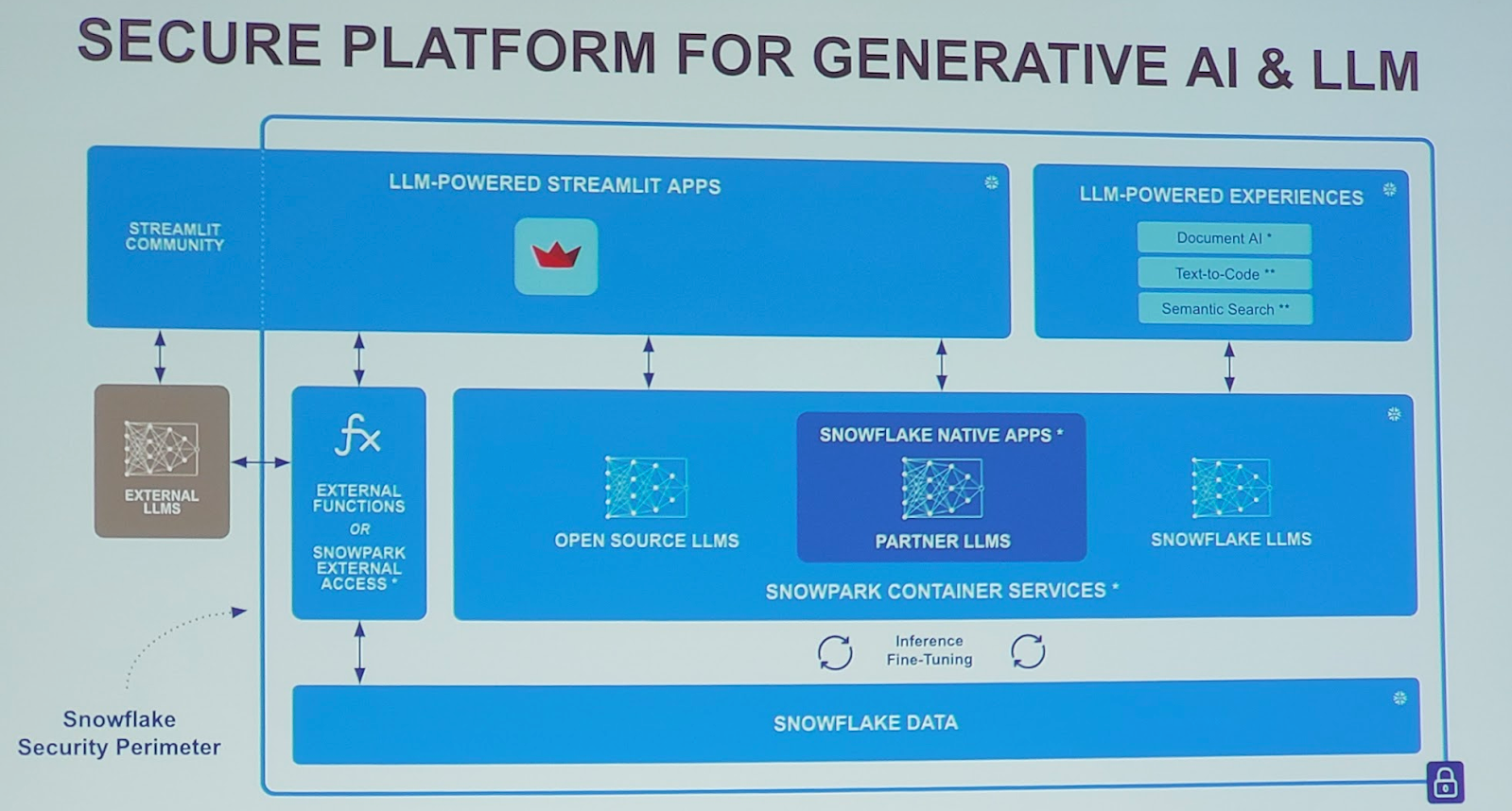
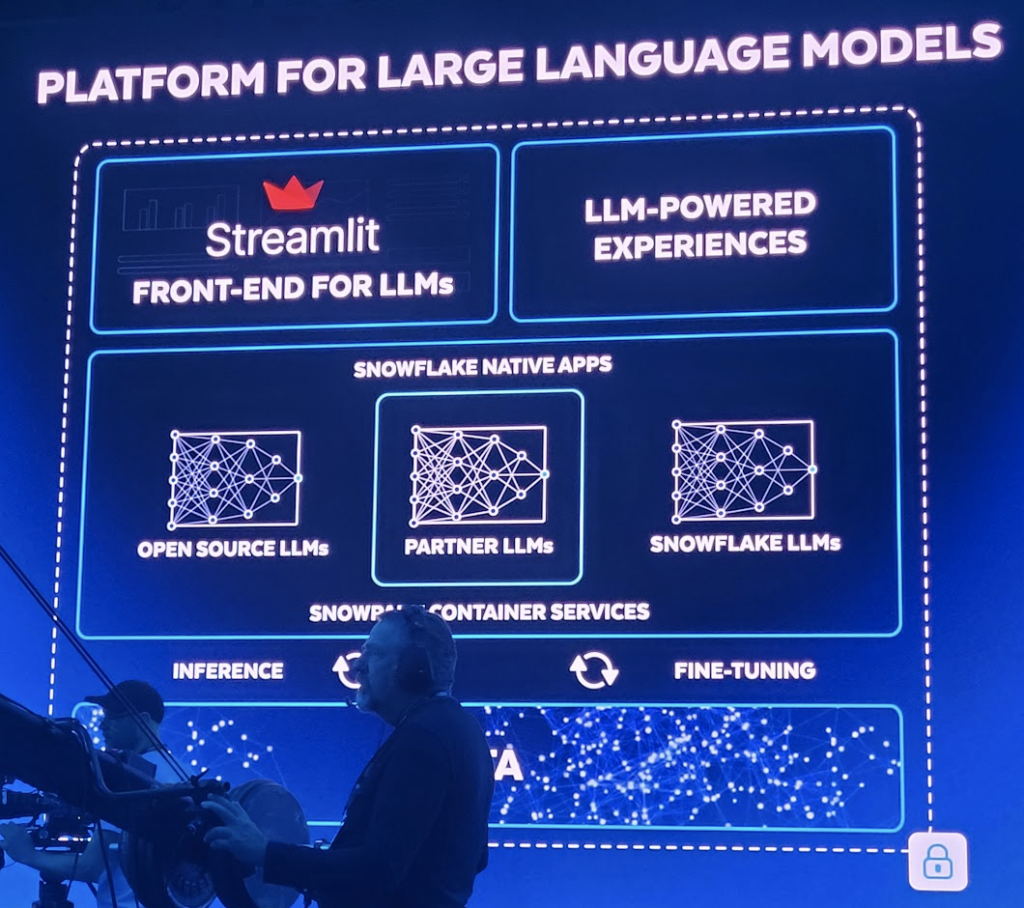
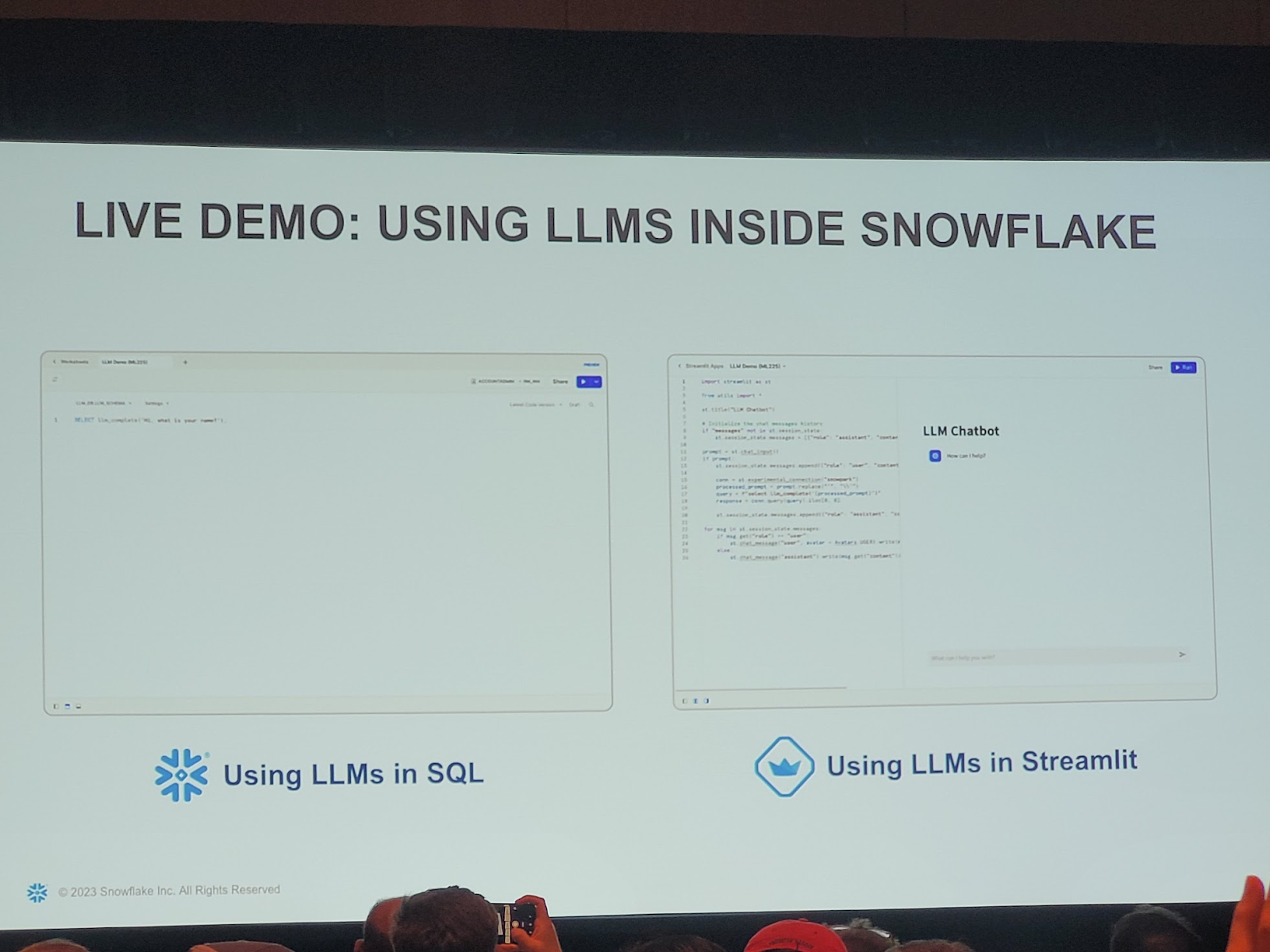
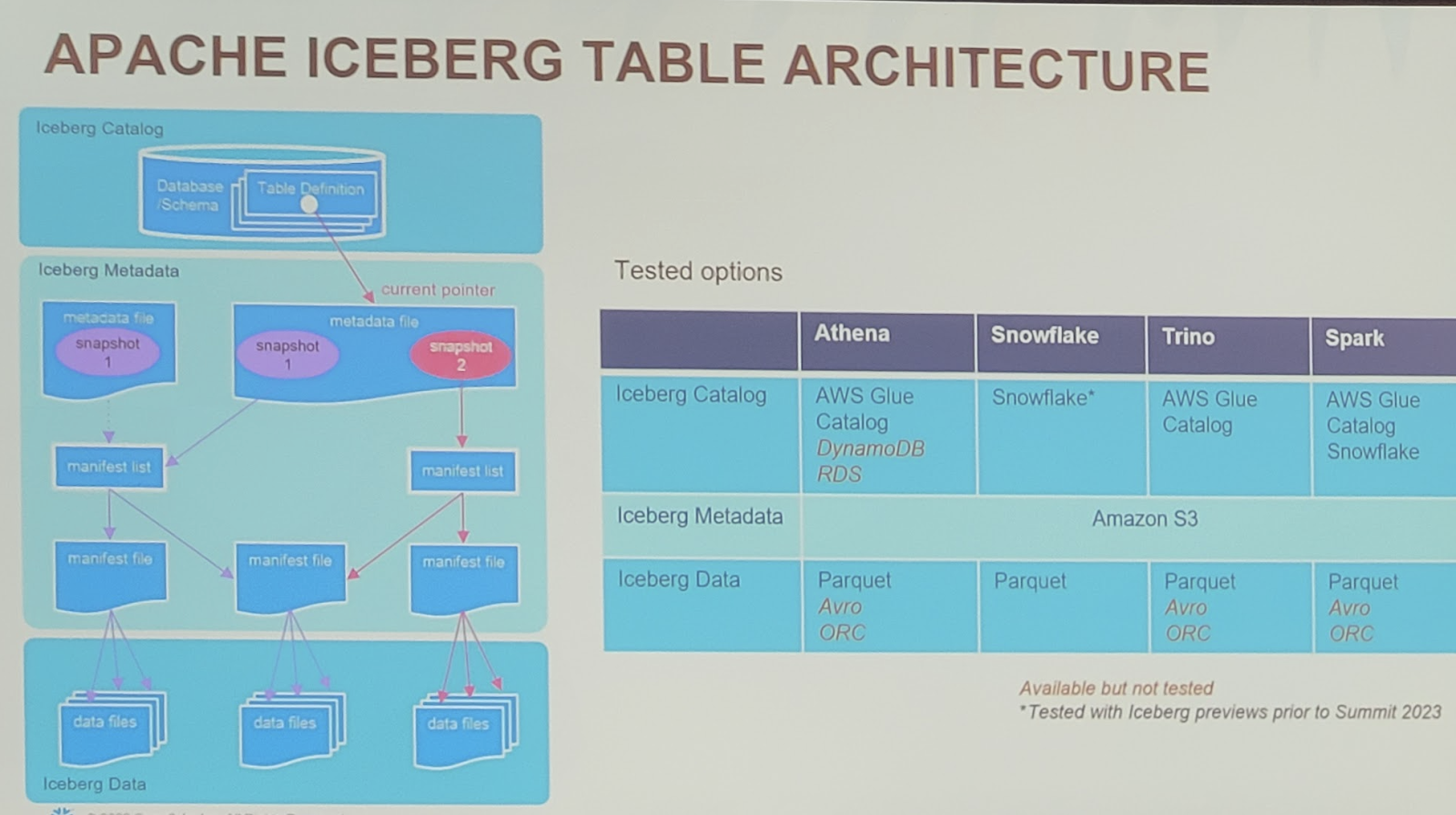
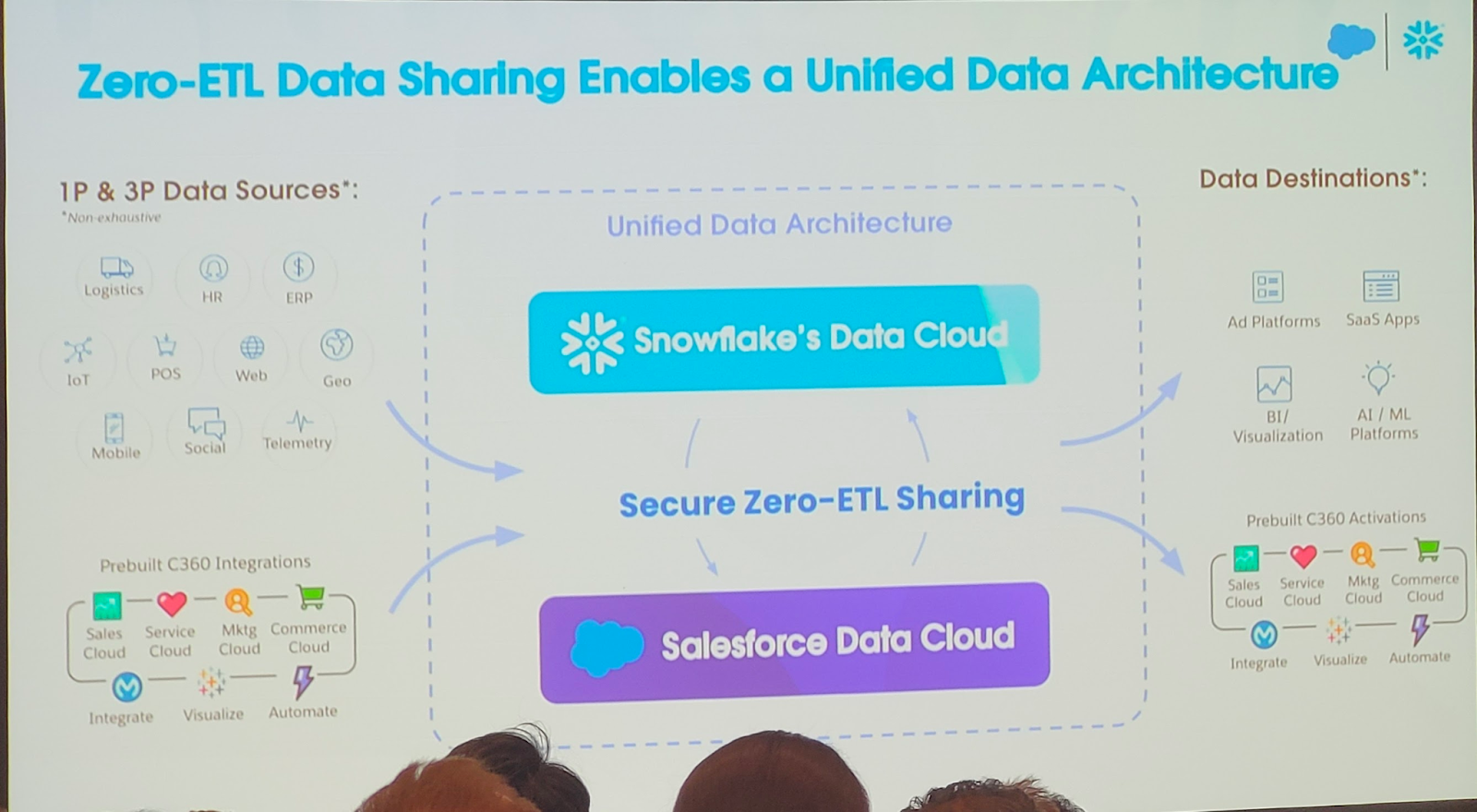
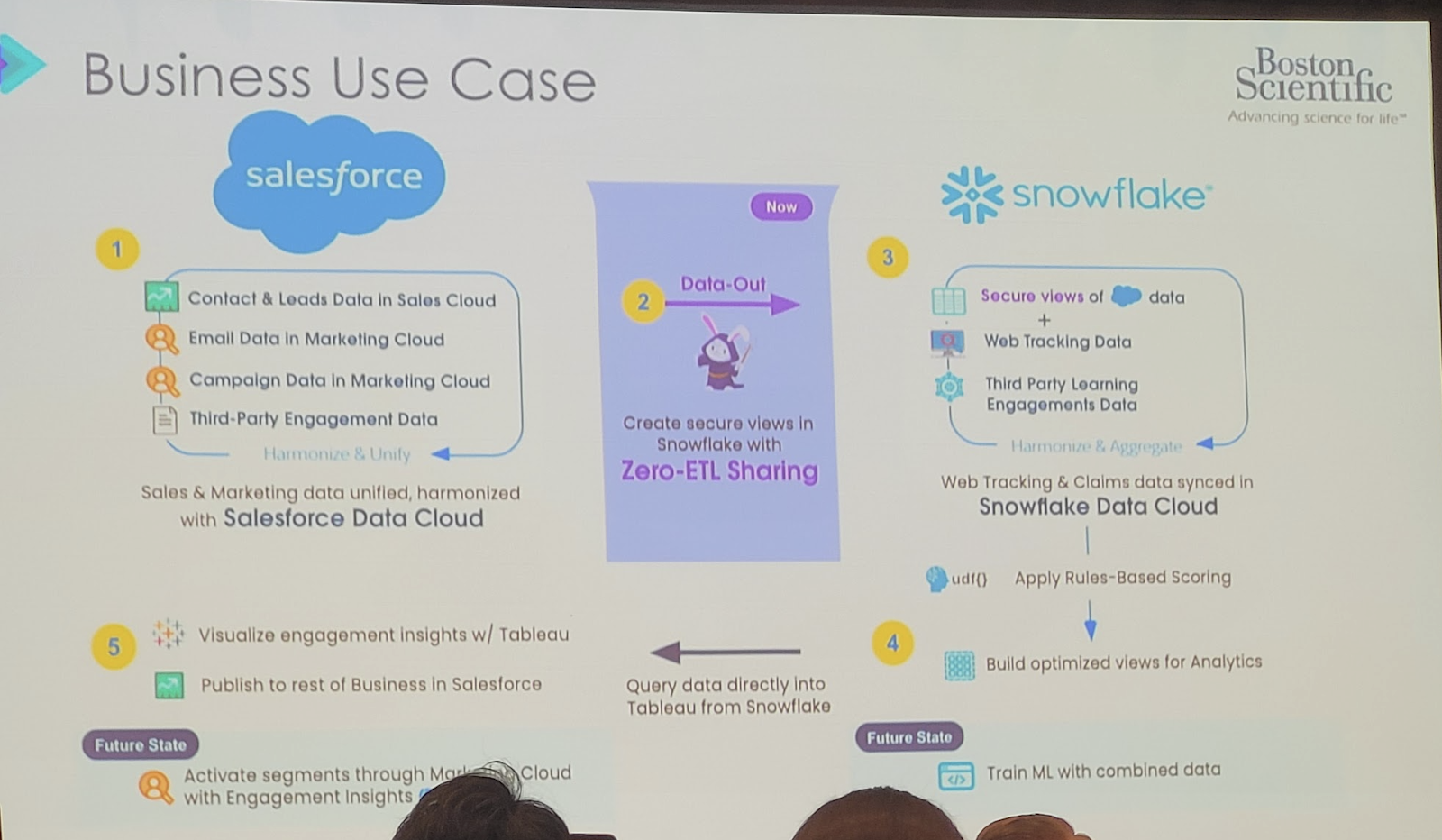
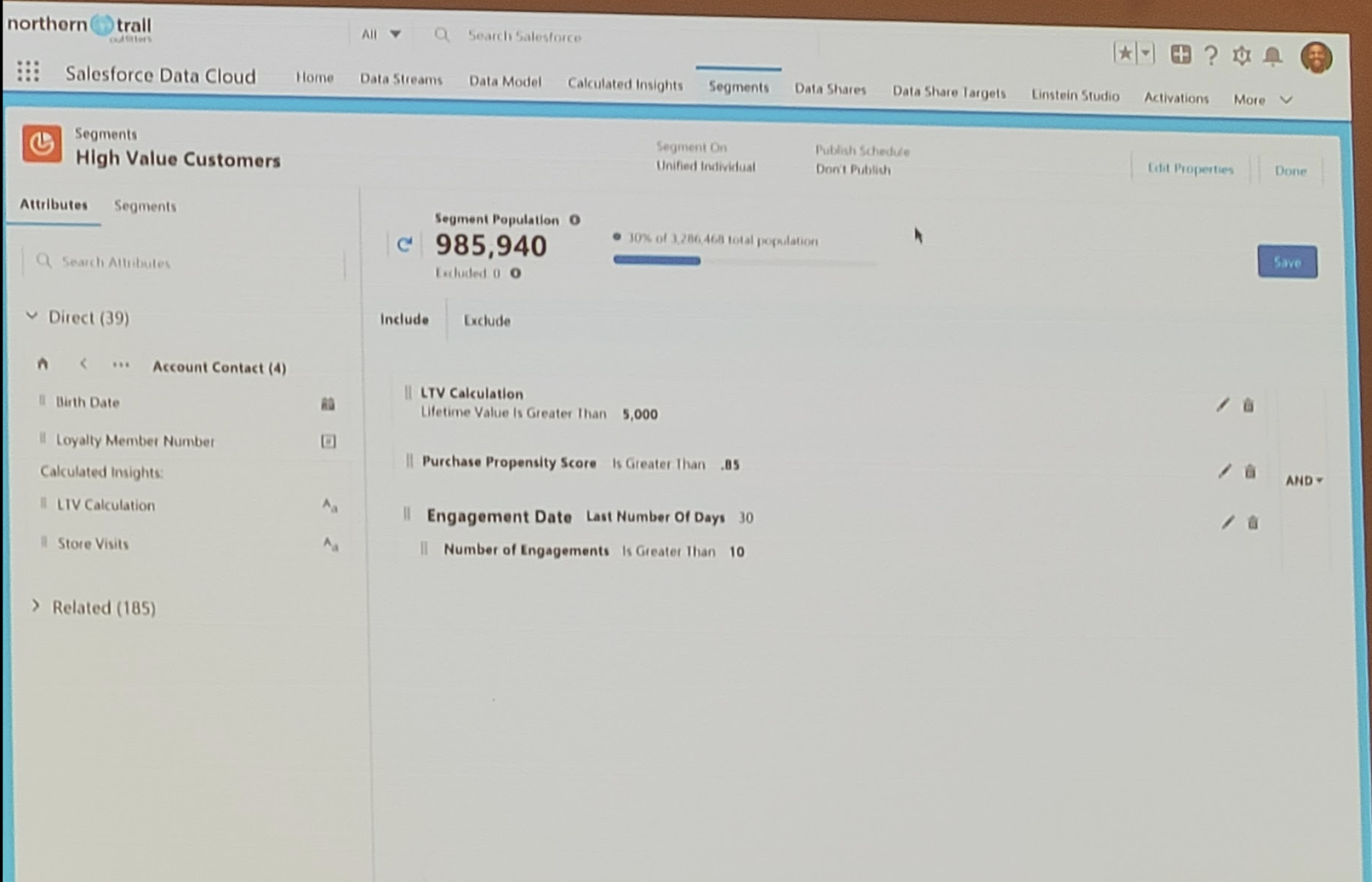
Com as duas aquisições recentes, Neeva e Streamlit, será mais fácil pesquisar e criar aplicativos com base nos dados. Com o anúncio do novo serviço de container e da parceria com a Nvidia, a Snowflake pretende facilitar a criação de aplicativos generativos de IA, usando todos os dados e executando-os nas GPUs da Nvidia.
Christian Kleinerman diz que o objetivo é permitir que as pessoas usem os dados sem ter que copiá-los e movê-los para um aplicativo externo. “Queremos permitir que nossos clientes tragam computação para seus dados corporativos e não precisem enviar seus dados corporativos para todos os tipos de sistemas externos”, disse Kleinerman ao TechCrunch.
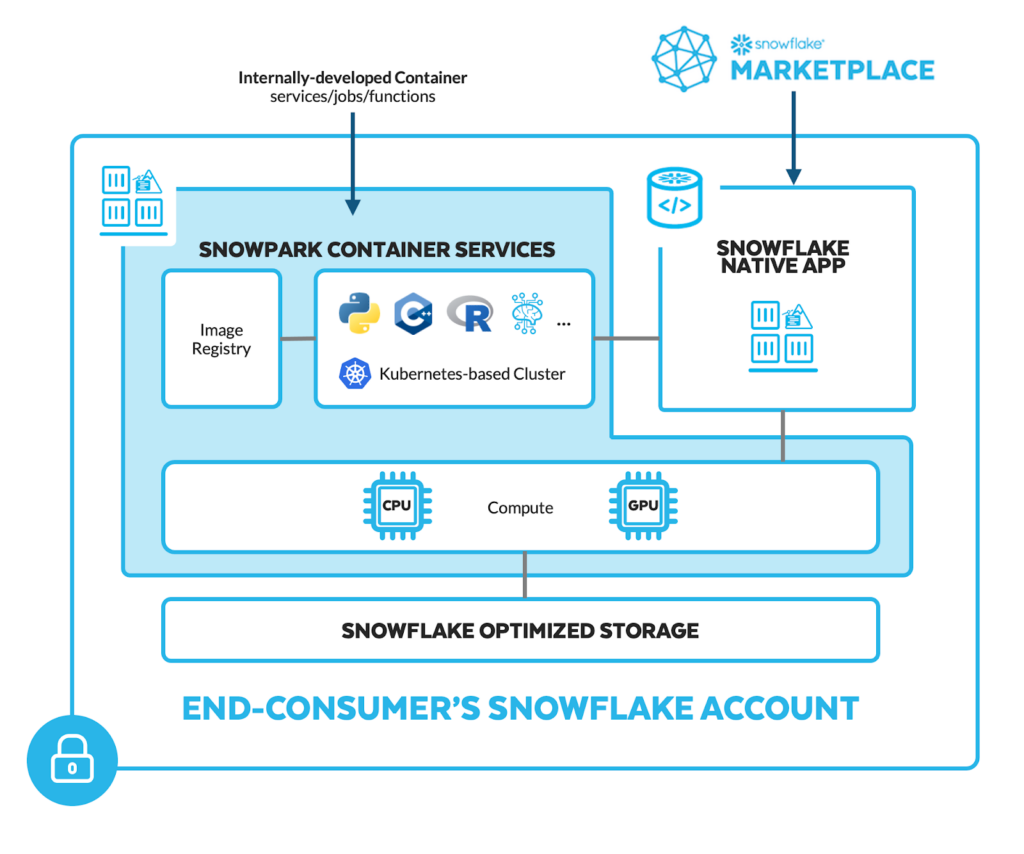
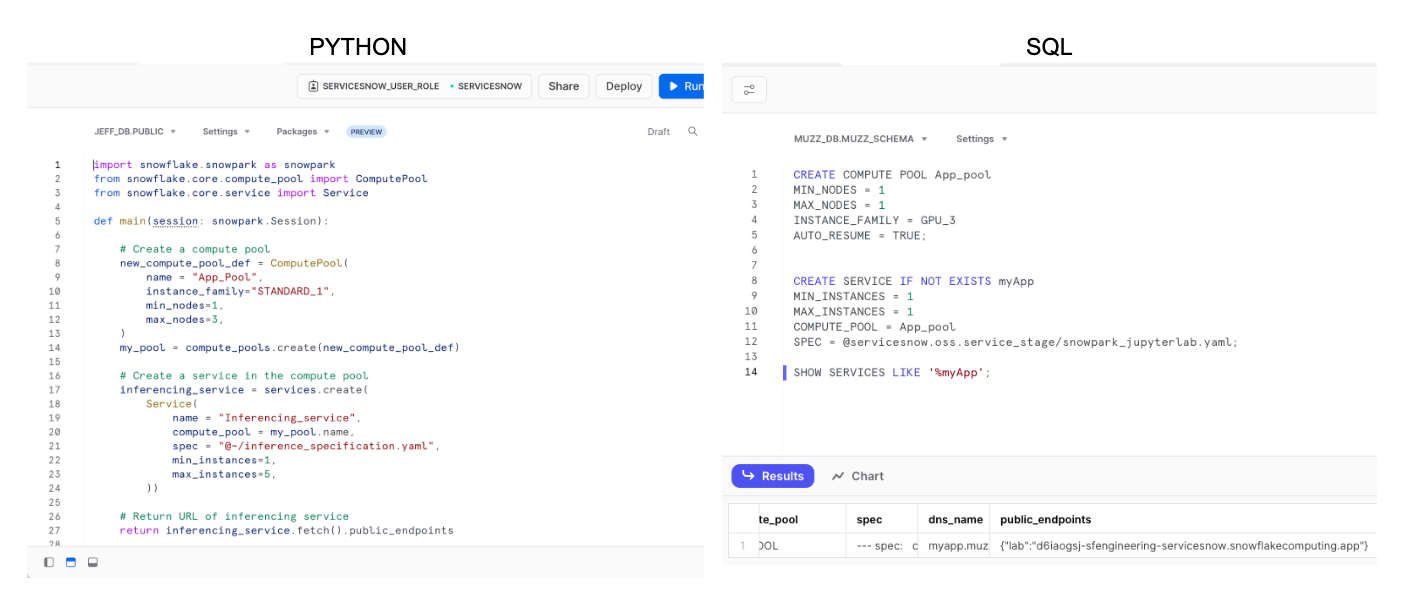
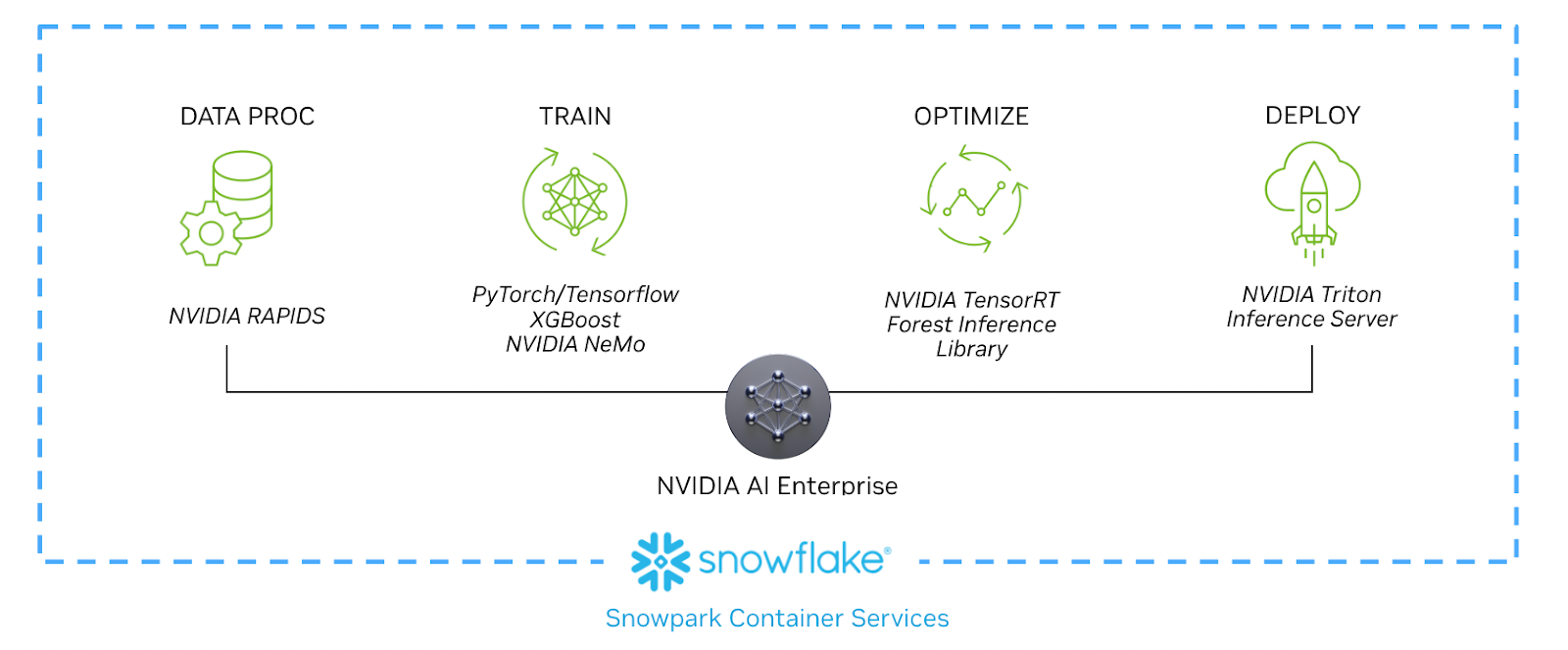
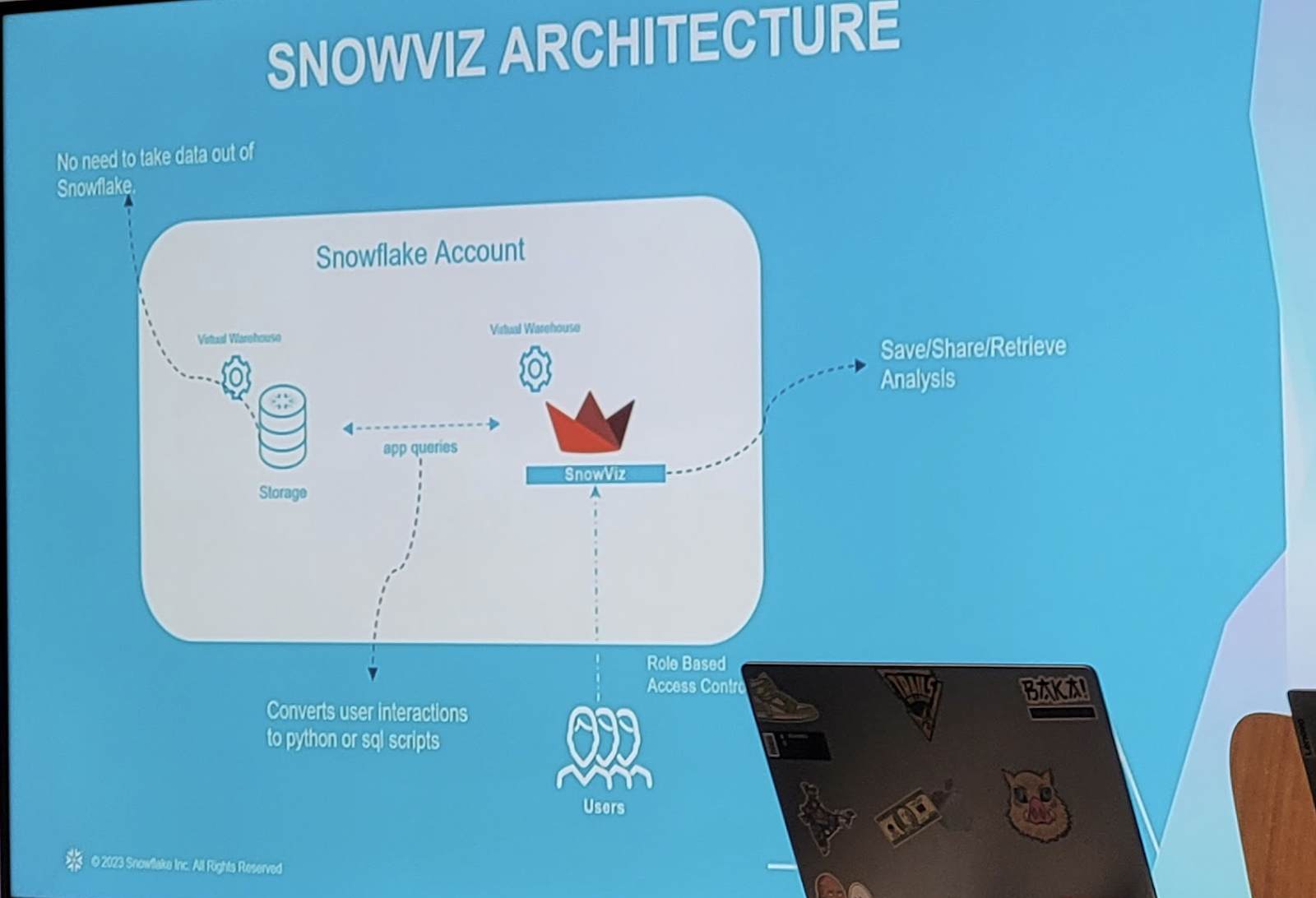
A empresa está apresentando o Snowpark Container Services, juntamente com a capacidade de executar aplicativos em containers em GPUs Nvidia, tudo sem mover nenhum dado para fora do Snowflake. “Estamos oferecendo aos clientes e parceiros a capacidade de executar containers Docker dentro do perímetro de segurança do Snowflake, dando a eles acesso controlado aos dados corporativos que residem ali”, disse Kleinerman.
“A maneira como estamos apresentando esses serviços de containers é fornecendo flexibilidade de instância mais ampla por meio do que o Snowflake já oferece tradicionalmente e, obviamente, o maior vetor de flexibilidade para o qual recebemos solicitações é o acesso a GPUs”, disse ele, que é onde a parceria Nvidia entra em jogo. O VP de Computação Corporativa da Nvidia, Manuvir Das, diz que vê o Snowflake como um local onde as empresas armazenam seus principais dados e, quando você pode criar aplicativos com base nesses dados e, em seguida, executar esses aplicativos nas GPUs da Nvidia, temos uma combinação muito poderosa, especialmente quando você traz IA generativa para a equação.
Manuvir reforça que, quando você combina o poder da GPU da Nvidia com sua estrutura NeMo, as empresas podem pegar os dados no Snowflake e começar a construir modelos refinados de aprendizado de máquina com base em seus próprios dados exclusivos. “É por isso que essa parceria é linda, porque o Snowflake tem todos esses dados e agora, pela primeira vez, tem o mecanismo para executar diferentes softwares com esses dados. Temos aquele agente de execução no NeMo que a Nvidia construiu para treinamento, para ajuste fino, para aprendizado por reforço e tudo mais”, disse Das.
O executivo ainda afirma que, reunir os dados dos clientes, os modelos que eles criaram usando esses dados e, em seguida, os aplicativos que eles estão executando que acessarão esses modelos, tudo em um só lugar, tornará mais fácil manter a segurança e controle desses dados, e a tecnologia Nvidia apenas torna tudo mais rápido.
O Snowpark Container Services da Snowflake já está disponível em versão beta privada.