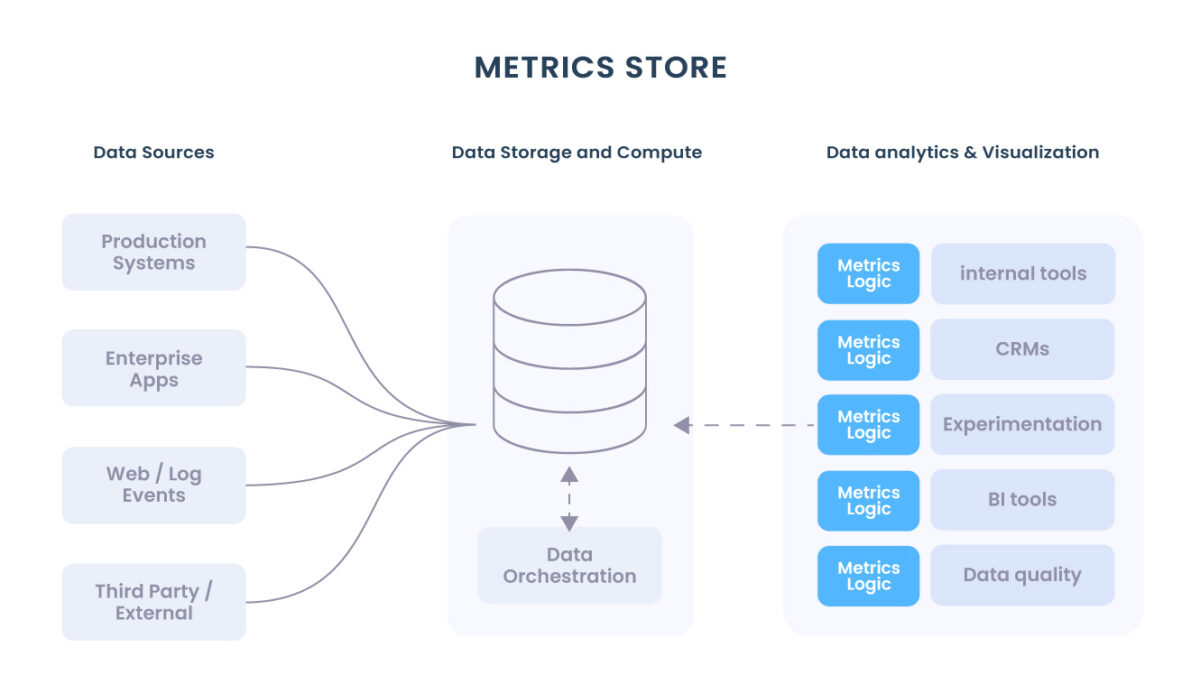
Construindo Cloud Data Lakehouse no Snowflake
Utilizamos análises, Data Science ou aplicações com dados para poder responder a perguntas, prever resultados, descobrir relacionamentos ou expandir negócios. Mas, para isso, os dados devem ser armazenados da melhor maneira para apoiar tais resultados. Essa decisão pode ser simples ao considerar um caso de uso pequeno e conhecido, mas rapidamente se torna complicada à medida que dimensiona o volume de dados, a variedade, as cargas de trabalho e os casos de uso.
Simplificar a experiência do usuário é um dos princípios de design mais importantes e isso se aplica muito ao armazenamento. Quando você armazena dados no Snowflake, todo seu esforço é drasticamente simplificado porque muitas funcionalidades de gerenciamento de armazenamento são tratadas automaticamente. Você pode confiar que seus dados são seguros, confiáveis e otimizados para acesso rápido e eficiente em praticamente qualquer escala. A seguir, vamos mergulhar nos principais recursos desta plataforma que torna tudo isso possível.
1. Suporte para todos os dados
Muitos clientes descobriram que o Snowflake é uma ótima solução para suas necessidades de data warehousing, armazenando e analisando dados estruturados e semiestruturados. No entanto, eles normalmente têm documentos, imagens, vídeos e arquivos de texto que desejam usar em conjunto com esses dados. Com o suporte adicional do Snowflake para dados não estruturados, você pode armazenar, proteger, controlar, analisar e compartilhar todos os tipos de dados: estruturados, semiestruturados e não estruturados.

2. Criptografia automática
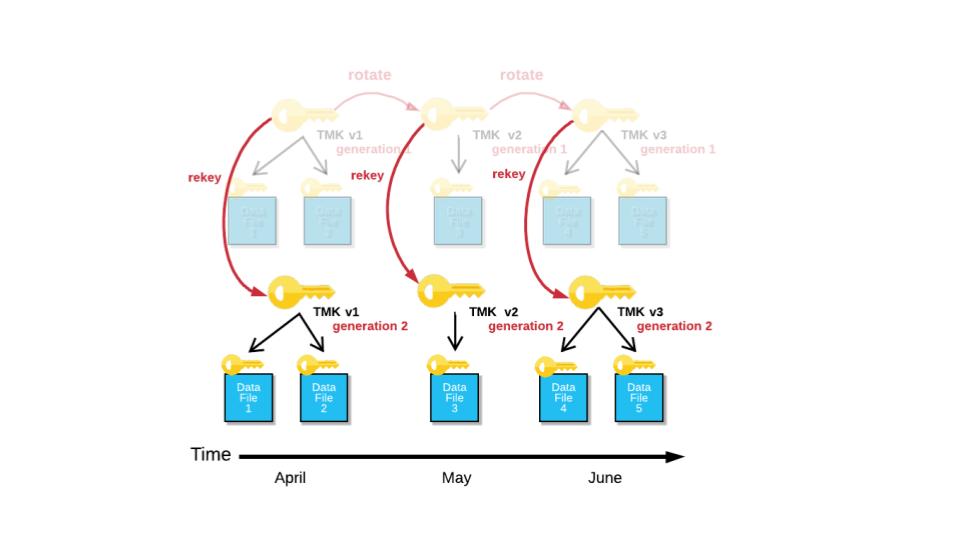
A proteção de dados é extremamente importante e pode ser difícil de gerenciar com muitos sistemas de armazenamento em uso. Mas isso é diferente no Snowflake, pois os dados em repouso e em trânsito são criptografados automaticamente. A plataforma utiliza a melhor prática da categoria, onde cada partição em cada tabela é criptografada usando chaves separadas em um modelo hierárquico, reduzindo significativamente o escopo dos dados protegidos por uma única chave.
As chaves gerenciadas também são alternadas automaticamente a cada 30 dias. A plataforma trata a segurança de várias maneiras, enquanto abstrai a complexidade para os usuários.
3. Particionamento automático
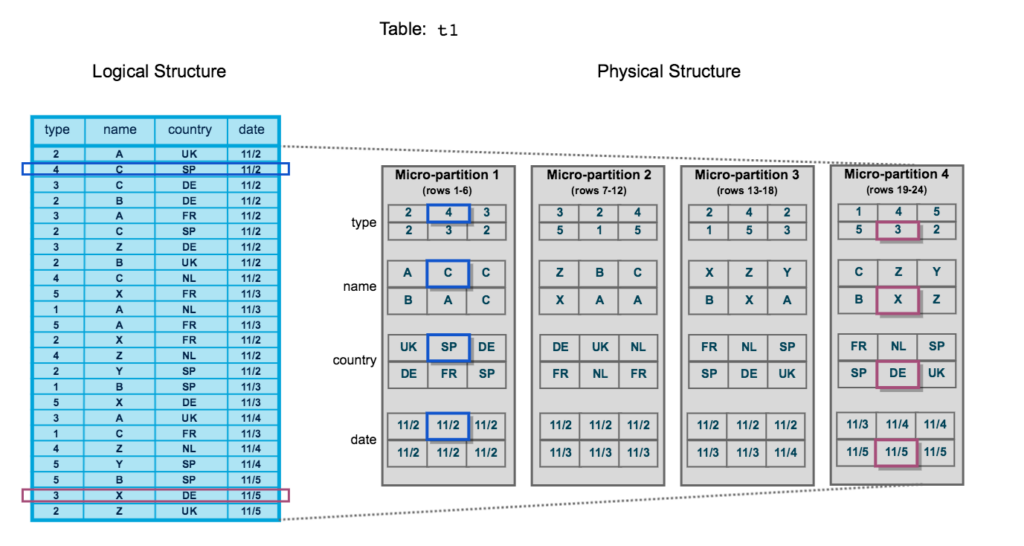
Consultar uma pequena quantidade de dados geralmente é rápido, mas, quando a escala de dados atinge centenas de terabytes ou petabytes, o particionamento eficiente se torna muito importante. Quando os dados são bem particionados, a execução da consulta pode remover as partições que não precisam ser verificadas e retornar resultados rapidamente. Outros sistemas de armazenamento geralmente exigem que você decida quais chaves de particionamento usar e qual estrutura de pastas seguir. Essas decisões se tornam ainda mais difíceis quando há várias chaves e partições aninhadas. Além disso, uma vez que os dados são particionados, alterar as chaves no futuro não é algo aconselhado.
Quando os dados são armazenados no Snowflake, eles são particionados automaticamente usando a arquitetura de micropartição, função exclusiva da plataforma para otimizar o desempenho. Não é preciso tomar nenhuma decisão sobre chaves de partição ou a ordem delas. As operações DML aproveitam os metadados de micropartição subjacentes para simplificar a manutenção da tabela.
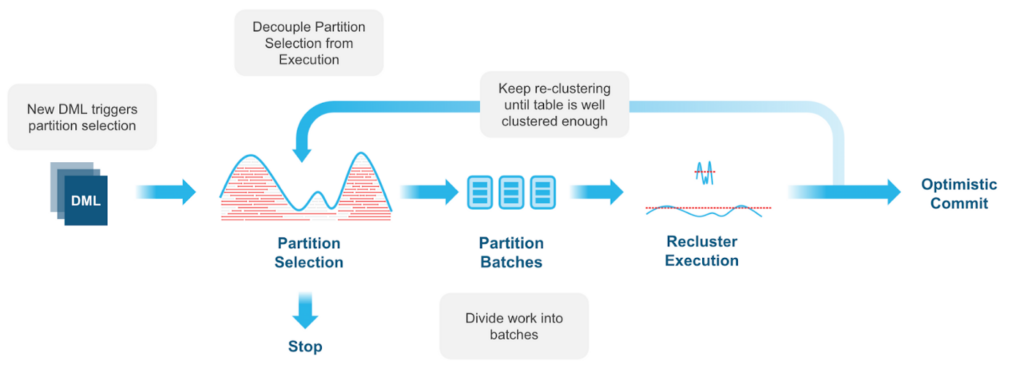
4. Clustering automático
Normalmente, os dados armazenados em tabelas são classificados em determinadas dimensões, como a data. Se não for classificado ou classificado nos campos errados, o desempenho da consulta nessas tabelas provavelmente será mais lento, deixando você com uma decisão potencialmente dispendiosa sobre onde e como classificar.
O clustering automático — um serviço opcional que consome créditos do Snowflake — gerencia de forma persistente e contínua todo o reclustering de tabelas conforme necessário. A plataforma coleta metadados de cluster para cada micropartição à medida que os dados são carregados em uma tabela e usa essas informações para evitar a verificação desnecessária de micropartições para consultas. Menos verificações significa desempenho mais rápido e isso se traduz em menor custo de computação. À medida que você executa DML em tabelas, o Snowflake monitora e avalia se você se beneficiaria do reclustering, enquanto mantém a capacidade de suspender e retomar o serviço a qualquer momento.
5. Compressão automática
Os data lakes que usam armazenamento de objetos em nuvem são uma solução comum para acomodar grandes volumes de dados a baixo custo, e a compactação pode ajudar você a economizar ainda mais nos custos de armazenamento. Existem vários algoritmos de compactação disponíveis, mas escolha com sabedoria. Alguns algoritmos podem fornecer melhor compactação, mas são lentos para descompactar, o que prejudica o desempenho da consulta. Alguns algoritmos fornecem resultados ideais para compactar colunas inteiras ou decimais, mas não são tão bons para colunas baseadas em texto (e vice-versa).
Ao armazenar dados no Snowflake, você não precisa tomar essas decisões complexas. Os dados são compactados automaticamente usando algoritmos de última geração e otimizados com base nos tipos de dados da coluna, que podem fornecer ganhos de compactação. Ao contrário de outros serviços de armazenamento de objetos, os custos do Snowflake são calculados após a compactação. Portanto, os ganhos se traduzem em economia direta nos custos de armazenamento. E como a compactação resulta em uma representação de armazenamento menor, as consultas estão examinando menos dados, produzindo resultados mais rapidamente e usando menos recursos de computação, o que também se traduz em melhor economia para quem utiliza a plataforma. Além disso, quaisquer melhorias no algoritmo de compactação são aplicadas automaticamente para todos os usuários, reduzindo ainda mais os custos sem exigir nenhuma ação deles.
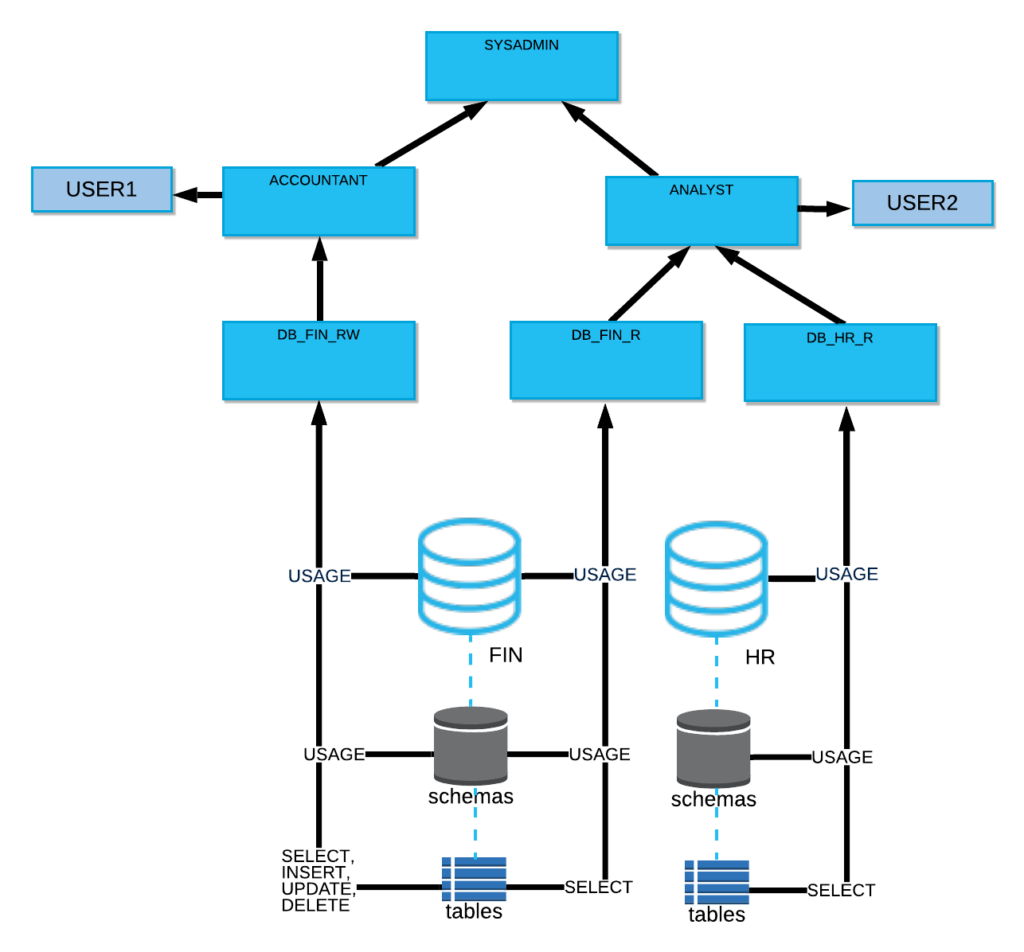
6. Controles de acesso granulares
A governança é um requisito extremamente importante a ser considerado ao projetar um data lake. Ao implementar um data lake em serviços de armazenamento em nuvem, você precisa proteger o acesso aos dados usando permissões em nível de objeto. Os serviços do provedor de armazenamento em nuvem oferecem funções e privilégios do IAM, que fornecem permissões para ler, gravar e excluir blobs ou arquivos armazenados em buckets. À medida que a escala de seus conjuntos de dados aumenta, o gerenciamento desses privilégios pode se tornar rapidamente muito complexo e complicado. Além disso, se você replicar ou migrar seu data lake para uma nuvem diferente, precisará traduzir esses privilégios para a plataforma IAM de uma nuvem diferente — uma tarefa não trivial, mesmo para os administradores de nuvem mais experientes.
O Snowflake simplifica o gerenciamento de privilégios fornecendo controle de acesso baseado em função em objetos de tabela, que se traduzem automaticamente em privilégios em micropartições subjacentes. Os proprietários de tabelas podem conceder acesso aos usuários finais usando comandos que funcionam exatamente com a mesma sintaxe, independentemente do provedor de nuvem subjacente no qual a plataforma está implementada. Mesmo que suas tabelas sejam replicadas entre nuvens, as concessões são replicadas automaticamente e mantidas em sincronia com o serviço Snowflake.
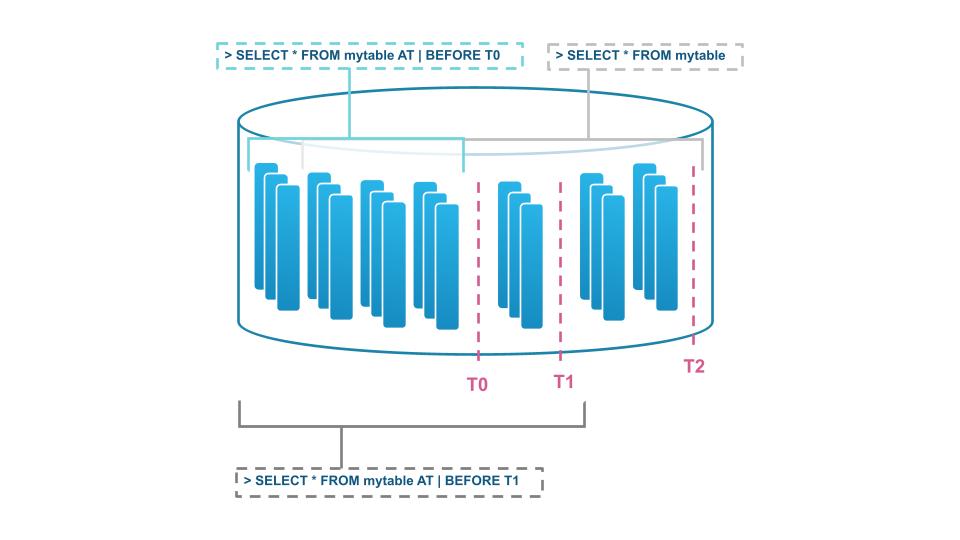
7. Versionamento automático, Time Travel e Fail Safe
À medida que você executa cargas de trabalho e operações em dados armazenados, provavelmente desejará um plano de contingência para exclusões acidentais de tabelas ou bancos de dados inteiros. Para dados armazenados no Snowflake, você não precisa se preocupar com a exclusão ou atualização acidental de dados devido aos recursos automáticos de Time Travel e Fail Safe. É possível ver o estado dos dados e objetos no passado e, se necessário, fazer UNDROP nos objetos.
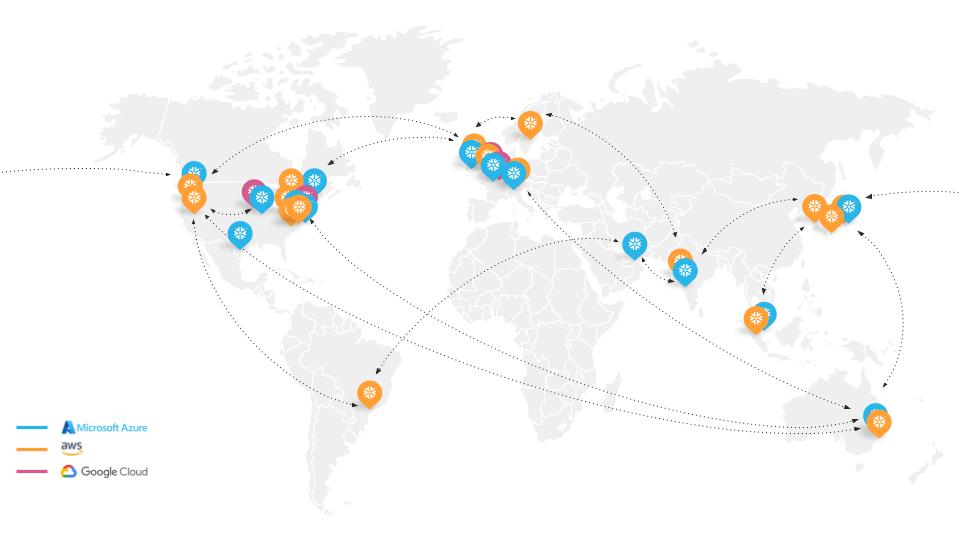
8. Replicação entre nuvens
Embora o Time Travel seja muito útil, não é suficiente para constituir uma contingência completa para a continuidade total dos negócios, seja um evento planejado ou não. Ao optar pelo armazenamento em nuvem, você geralmente fica limitado à disponibilidade dessa nuvem e região específica. No entanto, armazenar dados no Snowflake ajuda você a se preparar melhor para a continuidade dos negócios e a recuperação de desastres com recursos de replicação, failover e redirecionamento.
Isso significa que, no caso de uma interrupção, você pode promover objetos de conta de réplica secundária em outra região ou plataforma de nuvem para servir como objetos primários de leitura/gravação. Com o Snowflake, você também pode mover sua conta para uma região ou plataforma de nuvem diferente sem interrupções, o que é especialmente útil durante fusões, aquisições ou mudanças na estratégia de nuvem, por exemplo.
Escolhendo o armazenamento certo - Snowflake
Construir um data lake e armazenar dados no Snowflake traz grande flexibilidade ao criar a arquitetura que melhor atenda às necessidades do negócio. Existem opções exclusivas para suportar diferentes padrões e casos de uso.
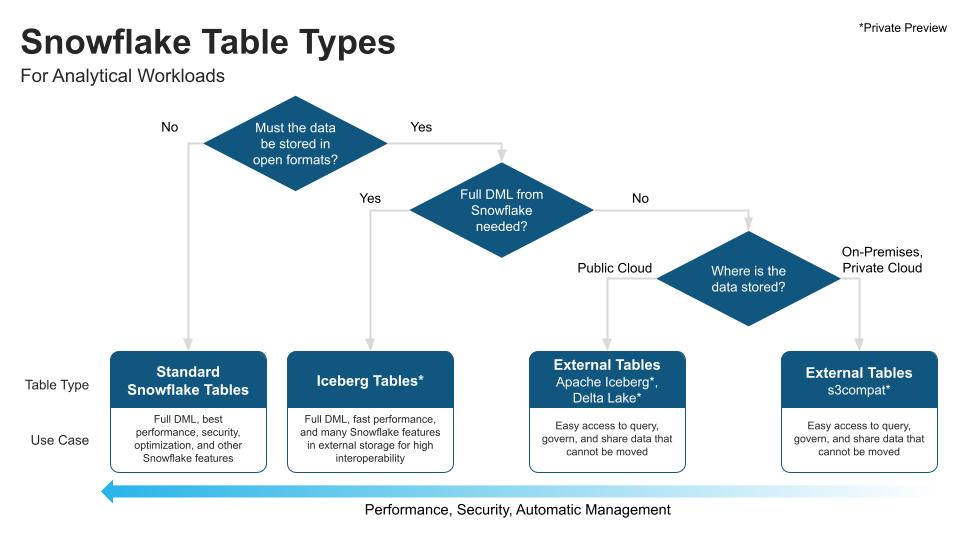
O armazenamento é uma peça fundamental da arquitetura de dados e pode ser bem complexa e dispendiosa para uma organização. O Snowflake simplifica essa situação com automação, otimizando o desempenho, a segurança e a facilidade de uso.
A triggo.ai é pioneira e especialista em MDS – Modern Data Stack & DataOps no Brasil, desenvolvemos produtos e soluções que permitem nossos clientes atingir o melhor ROI para Data Analytics & AI. Fale com um de nossos especialistas!