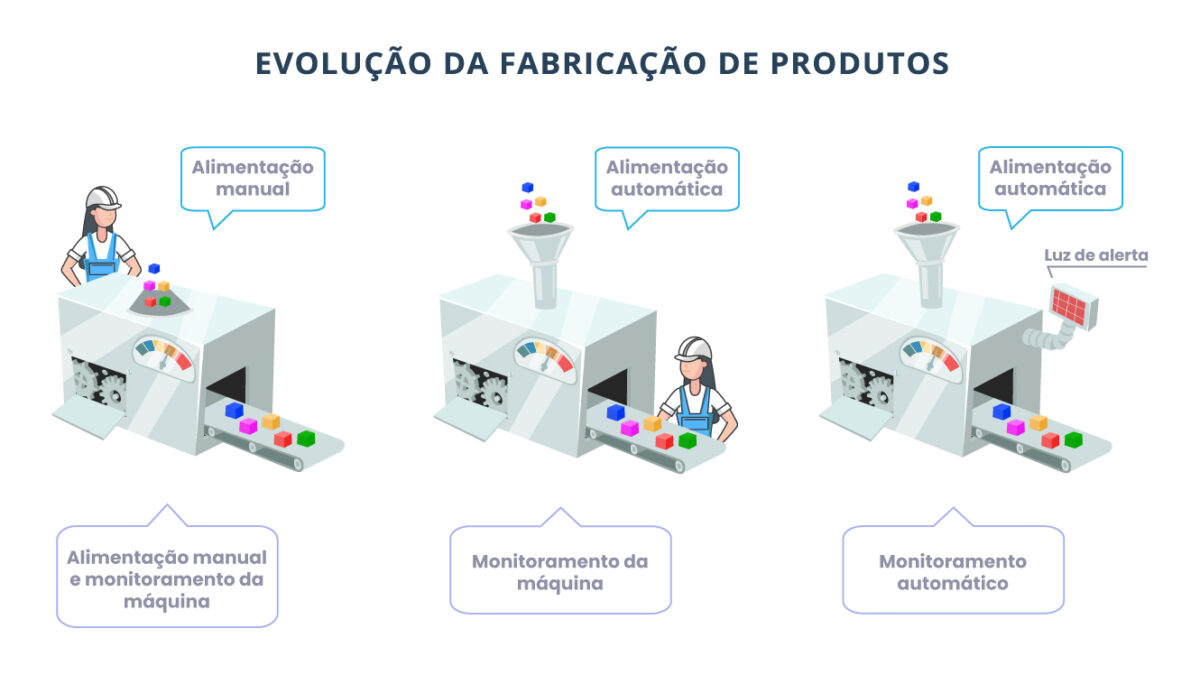
O que é Observabilidade de Dados?
Essa ideia surgiu do “tempo de inatividade de dados”, sobre o qual Barr Moses, de Monte Carlo, falou pela primeira vez em 2019: “O tempo de inatividade de dados se refere a períodos de tempo em que seus dados são parciais, errôneos, ausentes ou imprecisos”. São aqueles e-mails que você recebe na manhã seguinte a um grande projeto, dizendo: “Ei, os dados não parecem corretos…”
Não importa quão fortes são nossos pipelines ou quantas vezes revisamos nosso SQL, se nossos dados simplesmente não são confiáveis.
O tempo de inatividade dos dados, períodos de tempo em que os dados são parciais, errôneos, ausentes ou imprecisos, se multiplica à medida que os sistemas de dados se tornam cada vez mais complexos, suportando um ecossistema infinito de fontes e consumidores.
Para engenheiros de dados e desenvolvedores, o tempo de inatividade de dados significa desperdício de tempo e recursos; para os consumidores de dados, isso corrói a confiança em sua tomada de decisão.
Da mesma forma que as equipes de SRE são as primeiras a saber sobre falhas de aplicações ou problemas de desempenho, as equipes de dados também devem ser as primeiras a saber sobre pipelines ruins e problemas de qualidade de dados. Há apenas seis anos, a perda de dados e o tempo de inatividade custavam às empresas US$ 1,7 trilhão acumulados anualmente.
O tempo de inatividade de dados faz parte da vida normal de uma equipe de dados há anos. Mas agora, com muitas empresas confiando em dados para literalmente todos os aspectos de suas operações, é um grande problema quando os dados param de funcionar.
No entanto, todos estavam apenas reagindo aos problemas à medida que surgiam, em vez de preveni-los proativamente. Foi aí que surgiu a observabilidade dos dados, a ideia de “monitoramento, rastreamento e triagem de incidentes para evitar o tempo de inatividade”.
Ainda não consigo acreditar na rapidez com que a observabilidade de dados deixou de ser apenas uma ideia para uma parte fundamental da pilha de dados moderna. (Recentemente, começou a ser chamado de “confiabilidade de dados” ou “engenharia de confiabilidade de dados”.)
O espaço deixou de ser inexistente para sediar um monte de empresas, com um financiamento coletivo de US$ 200 milhões arrecadado em 18 meses. Isso inclui Acceldata, Anomalo, Bigeye, Databand, Datafold, Metaplane, Monte Carlo e Soda. As pessoas até começaram a criar listas de novas “empresas de observabilidade de dados” para ajudar a acompanhar este espaço.
Acredito que nos últimos dois anos, as equipes de dados perceberam que ferramentas para melhorar a produtividade não são boas, mas obrigatórias. Afinal, os profissionais de dados são uma das contratações mais procuradas que você já fez, portanto, eles não devem perder tempo resolvendo problemas de pipelines.
Então, a observabilidade de dados será uma parte fundamental da pilha de dados moderna no futuro? Absolutamente. Mas a observabilidade de dados continuará existindo como sua própria categoria ou será mesclada em uma categoria mais ampla (como metadados ativos ou confiabilidade de dados)? Isso é o que eu não tenho tanta certeza.
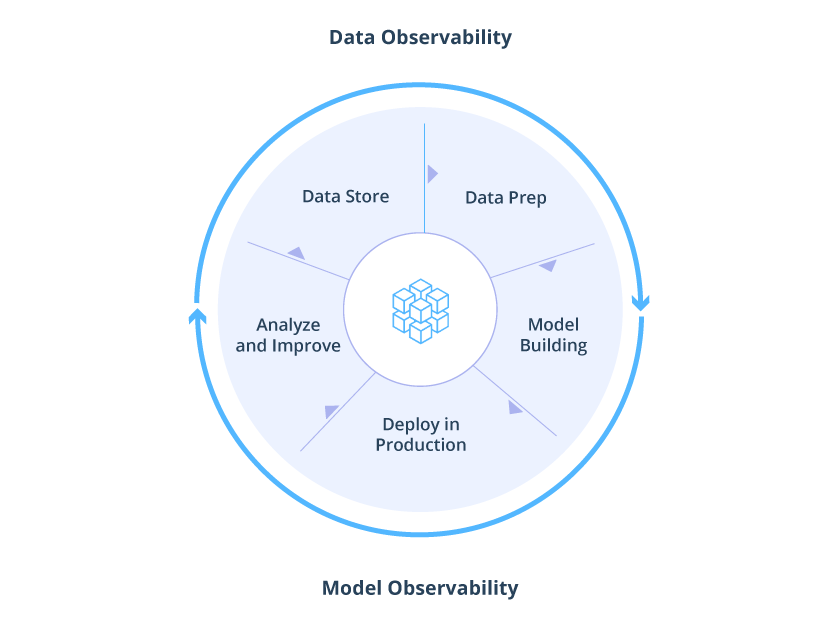
Data Observability, a capacidade de uma organização de entender completamente a integridade dos dados em seu sistema, elimina o tempo de inatividade dos dados aplicando as práticas recomendadas de observabilidade de DevOps aos pipelines de dados. Assim como sua contraparte de DevOps, a Data Observability usa monitoramento, alerta e triagem automatizados para identificar e avaliar problemas de qualidade e descoberta de dados, levando a pipelines mais saudáveis, equipes mais produtivas e clientes mais felizes.
Pode parecer caótico e louco às vezes, mas hoje é uma era de ouro dos dados.
A observabilidade não é mais apenas para engenharia de software. Com o aumento do tempo de inatividade de dados e a crescente complexidade da pilha de dados, a observabilidade também surgiu como uma preocupação crítica para as equipes de dados.
As equipes de Operações de Engenharia (chamadas DevOps) tornaram-se um componente integral da maioria das organizações de engenharia. As equipes de DevOps removem os silos entre os desenvolvedores de software e a TI, facilitando o lançamento contínuo e confiável do software para produção.
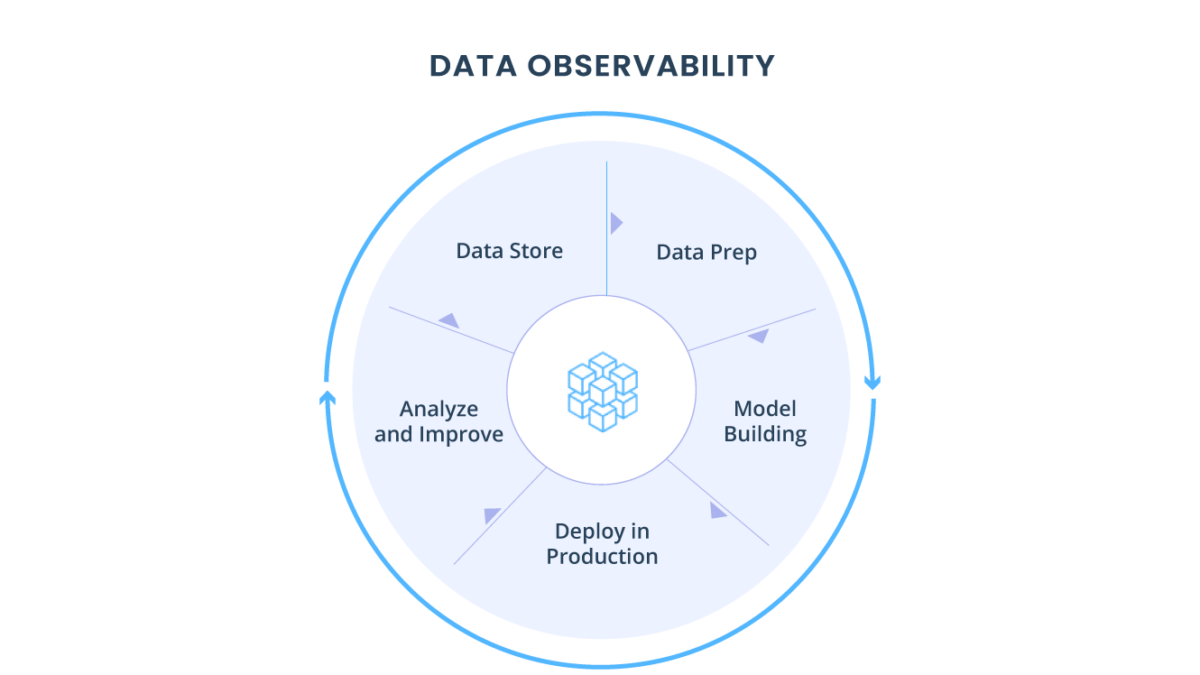
Abaixo os 5 pilares para data observability:
Os 5 pilares para Data Observability
Freshness: freshness procura entender quão atualizadas estão suas tabelas de dados, bem como a cadência em que suas tabelas são atualizadas. É particularmente importante quando se trata de tomada de decisão; afinal, dados obsoletos são basicamente sinônimo de desperdício de tempo e dinheiro.
Distribution: distribuição, em outras palavras, uma função dos valores possíveis de seus dados, informa se seus dados estão dentro de um intervalo aceito. A distribuição de dados fornece informações sobre se suas tabelas podem ou não ser confiáveis com base no que pode ser esperado de seus dados.
Volume: o volume refere-se à integridade de suas tabelas de dados e oferece insights sobre a integridade de suas fontes de dados. Se 200 milhões de linhas de repente se transformarem em 5 milhões, você
deve saber.
Schema: mudanças na organização de seus dados, ou seja, esquema, muitas vezes indicam dados quebrados. Monitorar quem faz alterações nessas tabelas e quando é fundamental para entender a integridade do seu ecossistema de dados.
Lineage: quando os dados quebram, a primeira pergunta é sempre “onde?”. A linhagem de dados fornece a resposta informando quais fontes upstream e ingestores downstream foram impactados, bem como quais equipes estão gerando os dados e quem os está acessando. A boa linhagem também coleta informações sobre os dados (também chamados de metadados) que falam sobre governança, negócios e diretrizes técnicas associadas a tabelas de dados específicas, servindo como uma única fonte de verdade para todos os consumidores.
A observabilidade de dados é a espinha dorsal da capacidade de qualquer equipe de dados de ser ágil e iterar em seus produtos. Sem ela, uma equipe não pode confiar em sua solução ou ferramentas porque os erros não podem ser rastreados com rapidez suficiente. Isso leva a menos agilidade na criação de novos recursos e melhorias para seus clientes, o que significa que você está basicamente jogando dinheiro fora ao não investir nessa peça-chave da estrutura DataOps!
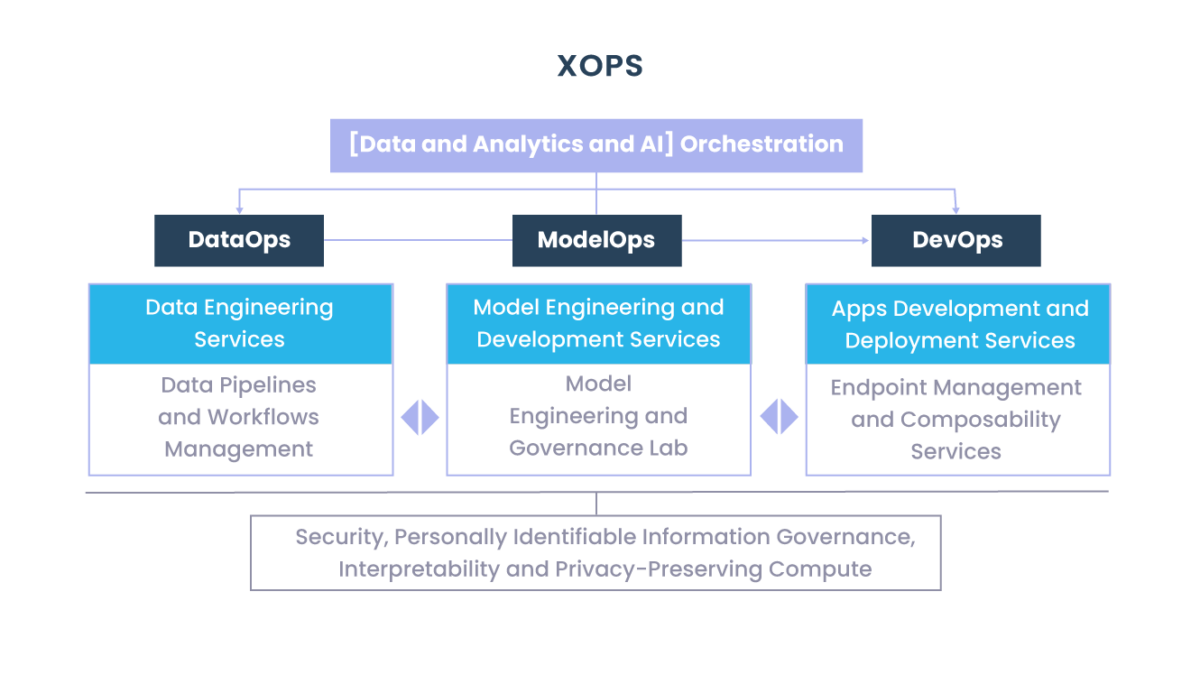
A triggo.ai é especialista em Data Analytics & AI, pioneira em XOps (DataOps|ModelOps|MLOps), e coloca a observabilidade bem como qualidade dos dados em primeiro plano, fale com um dos nossos especialistas!