
O que é RAG (Retrieval-Augmented Generation)?
No contexto atual de GenAI é fundamental abordarmos o conceito do RAG (Retrieval-Augmented Generation), pois ele será essencial para várias implementações.
Vamos imaginar que você está participando de um jogo de perguntas e respostas, onde você precisa responder a uma pergunta complexa com base em seu conhecimento. Agora, imagine que você tem acesso a um livro gigante, cheio de informações úteis sobre o assunto da pergunta.
- Retrieval (Recuperação): Neste jogo, a primeira etapa é encontrar a informação relevante dentro do livro. Isso é como a parte de “Recuperação” no RAG, onde o sistema busca em uma vasta quantidade de dados para encontrar as informações necessárias.
- Augmentation (Aumento): Depois de encontrar a informação, você não apenas a copia palavra por palavra, mas a interpreta e a complementa com sua própria compreensão. Isso é como a parte de “Aumento” no RAG, onde o sistema não apenas recupera informações, mas também gera respostas relevantes e bem formuladas.
- Generation (Geração): Finalmente, você apresenta sua resposta completa e bem elaborada, que não apenas responde à pergunta, mas também adiciona valor com sua análise e perspectiva. Isso é semelhante à parte de “Geração” no RAG, onde o sistema não apenas recupera e interpreta informações, mas também gera respostas completas e úteis.
Portanto, o RAG pode ser visto como um sistema que combina a capacidade de encontrar informações relevantes (recuperação), interpretá-las e complementá-las (aumento) e gerar respostas completas e bem formuladas (geração), assim como você faria ao responder a uma pergunta com base em um livro de referência.
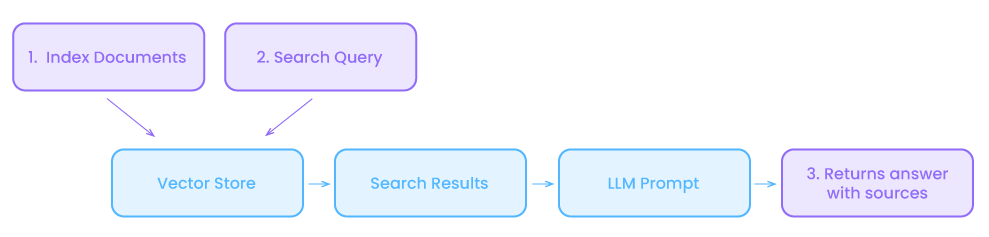
Para entender a geração aumentada por recuperação, vamos dividi-la em seus dois componentes principais: modelos de recuperação e modelos generativos.
- Modelos de recuperação: Esses modelos são projetados para recuperar informações relevantes de um determinado conjunto de documentos ou de uma base de conhecimento. Eles normalmente usam técnicas como recuperação de informações ou técnicas de pesquisa semântica para identificar as informações mais relevantes com base em uma determinada consulta. Os modelos baseados em recuperação são excelentes na localização de informações precisas e específicas, mas não têm a capacidade de gerar conteúdo criativo ou novo
- Modelos generativos: Os modelos generativos, por outro lado, são projetados para gerar novo conteúdo com base em um determinado prompt ou contexto. Esses LLMs (agora explicados em toda a Internet) usam uma grande quantidade de dados de treinamento para aprender os padrões e estruturas da linguagem natural. Os modelos generativos podem gerar textos criativos e coerentes, mas podem ter dificuldades com a precisão factual ou a relevância para um contexto específico.
Agora, a geração com recuperação aumentada combina essas duas abordagens para superar suas limitações individuais. Nesta estrutura, um modelo baseado em recuperação é usado para recuperar informações relevantes de uma base de conhecimento ou de um conjunto de documentos com base em uma determinada consulta ou contexto. As informações recuperadas são então usadas como entrada ou contexto adicional para o modelo generativo.
Outra analogia para compreender o mais recente avanço na IA generativa, imagine um tribunal.
Os juízes ouvem e decidem os casos com base na sua compreensão geral da lei. Às vezes, um caso como um processo por negligência médica ou uma disputa trabalhista requer conhecimentos especiais, por isso os juízes enviam funcionários judiciais a uma biblioteca jurídica, em busca de precedentes e casos específicos que possam citar.
Como um bom juiz, os grandes modelos de linguagem (LLMs) podem responder a uma ampla variedade de consultas humanas. Mas para fornecer respostas confiáveis que citem fontes, o modelo precisa de um assistente para fazer algumas pesquisas.
O funcionário do tribunal de IA é um processo denominado geração aumentada de recuperação, ou RAG (Retrieval-Augmented Generation).
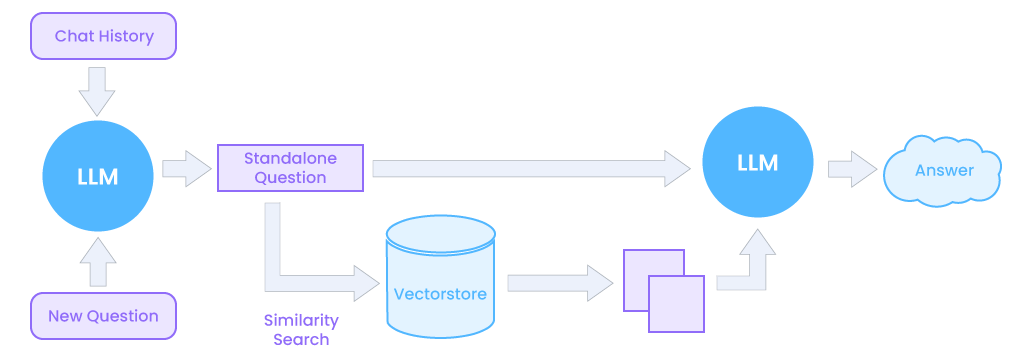
A implementação do RAG em um sistema de resposta a perguntas baseado em LLM tem dois benefícios principais: garante que o modelo tenha acesso aos fatos mais atuais e confiáveis e que os usuários tenham acesso às fontes do modelo, garantindo que suas afirmações possam ser verificadas quanto à precisão e em última análise, confiável.
RAG tem benefícios adicionais. Ao basear um LLM num conjunto de factos externos e verificáveis, o modelo tem menos oportunidades de extrair informações incorporadas nos seus parâmetros. Isto reduz as chances de um LLM vazar dados confidenciais ou “alucinar” informações incorretas ou enganosas.
O RAG também reduz a necessidade de os usuários treinarem continuamente o modelo com novos dados e atualizarem seus parâmetros conforme as circunstâncias evoluem. Dessa forma, o RAG pode reduzir os custos computacionais e financeiros da execução de chatbots com tecnologia LLM em um ambiente empresarial.
Como funciona?
Quando os usuários fazem uma pergunta a um LLM, o modelo de IA envia a consulta para outro modelo que a converte em um formato numérico para que as máquinas possam lê-la. A versão numérica da consulta às vezes é chamada de embedding ou vetor.
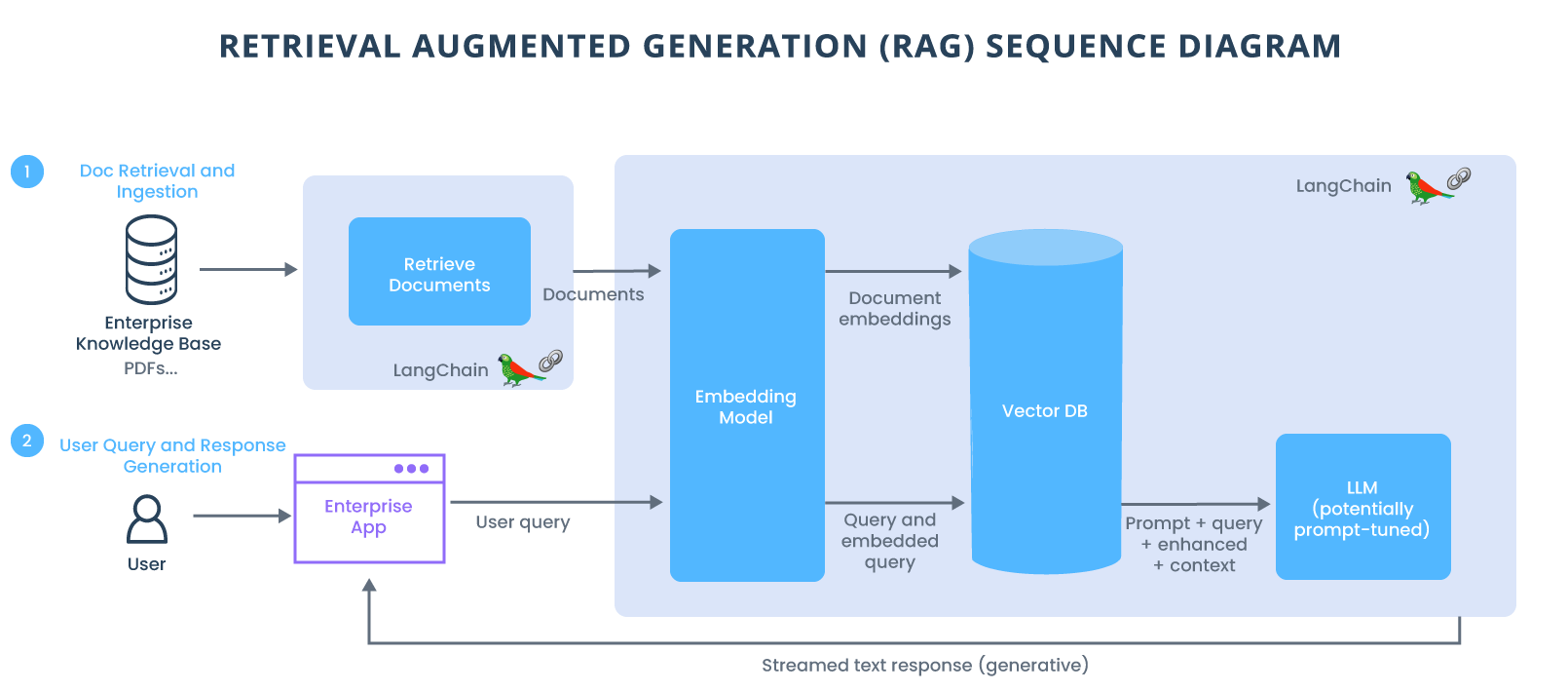
O modelo embedding compara então esses valores numéricos com vetores em um índice legível por máquina de uma base de conhecimento disponível. Quando encontra uma correspondência ou múltiplas correspondências, ele recupera os dados relacionados, converte-os em palavras legíveis por humanos e os repassa ao LLM.
Finalmente, o LLM combina as palavras recuperadas e sua própria resposta à consulta em uma resposta final que apresenta ao usuário, potencialmente citando as fontes do modelo de incorporação encontrado.
Em segundo plano, o modelo de incorporação cria e atualiza continuamente índices legíveis por máquina, às vezes chamados de bancos de dados vetoriais, para bases de conhecimento novas e atualizadas à medida que ficam disponíveis.
Essa compreensão profunda, às vezes chamada de conhecimento parametrizado, torna os LLMs úteis para responder a solicitações gerais na velocidade da luz. Porém, não atende usuários que desejam se aprofundar em um tema atual ou mais específico.
Olhando pra frente, o futuro da IA generativa reside no encadeamento criativo de todos os tipos de LLMs e bases de conhecimento para criar novos tipos de assistentes que forneçam resultados confiáveis que os usuários possam verificar.
A triggo.ai vem atuando na fronteira deste desafio, implementando soluções robustas e inovadoras de IA Generativa e aplicando metodologias de Data & AI Products para elevar e acelerar a jornada Data Driven das organizações. Fale com um de nossos consultores especialistas!



Excelente artigo.