Data Mesh – Conheça seus 4 princípios
Bem-vindo à revolução do gerenciamento de dados! Este artigo aborda os 4 princípios do Data Mesh que norteiam alguns dos principais desafios de Data & Analytics para as organizações. Vamos mergulhar um pouco nos princípios do Data Mesh, uma abordagem inovadora que pode ajudar muito na democratização dos dados.
Prepare-se para descobrir como essa estratégia está transformando a maneira como as empresas lidam com seus dados e ampliam a o autoatendimento das equipes com dados confiáveis e de alta qualidade.
O que é um Data Mesh?
Antes de começar, é importante que você saiba qual a definição de Data Mesh. Também chamada de Malha de Dados, essa é uma abordagem de gerenciamento de dados que apoia uma prática liderada por domínio para definir, entregar, manter e governar produtos de dados.
Se você quiser entender um pouco mais sobre o tema, temos um artigo que explica mais sobre Data Mesh, Data Fabric e Active Metadata.
Embora o modelo centralizado possa funcionar para organizações que possuem um domínio mais simples com um número menor de casos de consumo diversos, ele falha para empresas com domínios ricos, um grande número de fontes e um conjunto diversificado de consumidores/usuários.
Desde o início da década de 2010, as arquiteturas de microsserviços foram adotadas por empresas em toda parte (Uber, Netflix e Airbnb , entre outras) como o paradigma de software atual, provocando discussões entre as equipes de engenharia sobre os prós e contras do design orientado ao domínio.
Agora, em 2022, você terá dificuldade em encontrar um engenheiro de dados cuja equipe não esteja debatendo se deve ou não migrar de uma arquitetura monolítica para uma malha de dados descentralizada.
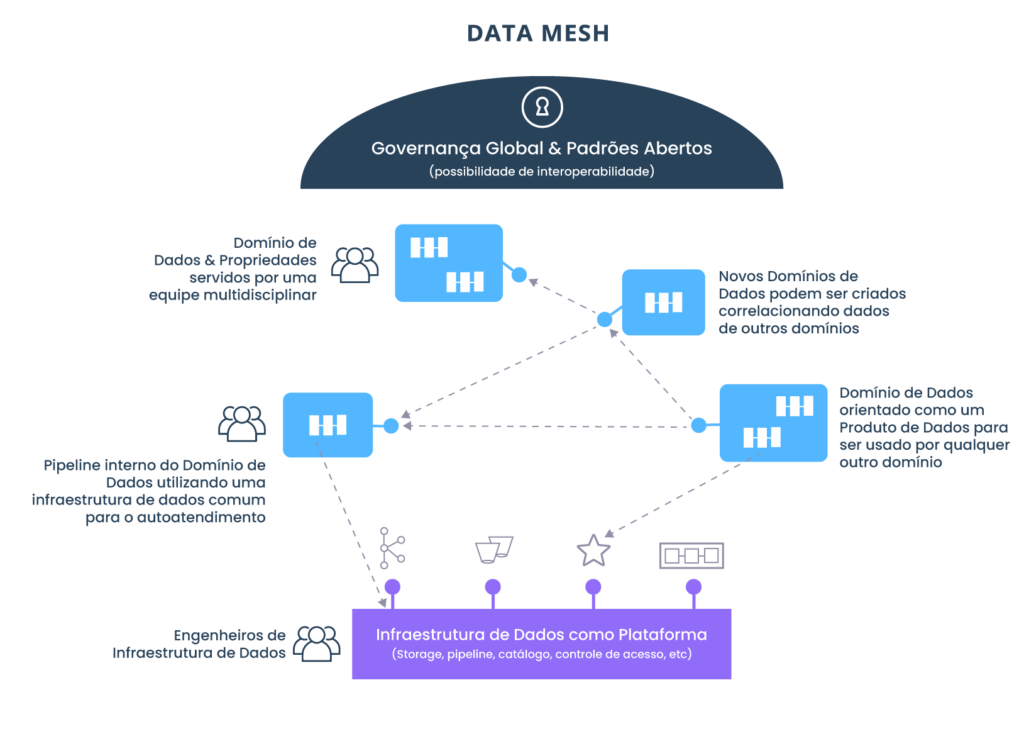
Desenvolvida por Zhamak Dehghani da Thoughtworks , a malha de dados é um tipo de arquitetura de plataforma de dados que abrange a onipresença dos dados na empresa, aproveitando um design de autoatendimento orientado por domínio.
À medida que as empresas se tornam cada vez mais orientadas por dados, a malha de dados se presta bem a três elementos-chave da organização de dados moderna:
- A necessidade por mais e mais dados , ingeridos e aproveitados pelas partes interessadas em toda a empresa, em oposição a uma equipe solitária de “engenheiros de dados”
- A crescente complexidade dos pipelines de dados à medida que as equipes buscam fazer coisas cada vez mais inteligentes com seus dados
- O surgimento de uma camada padronizada de observabilidade e descoberta de dados para entender a integridade de seus ativos de dados em todo o ciclo de vida
Como ir além de um Data Lake monolítico para uma malha de dados distribuída – A peça original de Zhamak Deghani é o Santo Graal de todo o conteúdo de malha de dados. Pense neste artigo como sua porta de entrada , aguçando seu apetite para futuras discussões sobre oportunidades, desafios e principais considerações ao implementar o design na prática. Seus diagramas de arquitetura são essenciais para entender como a malha de dados atinge uma nova pose em relação às arquiteturas centralizadas.
A plataforma de Data Mesh é uma arquitetura de dados distribuídos intencionalmente projetada, sob governança centralizada e padronização para interoperabilidade, habilitada por uma infraestrutura de dados de autoatendimento compartilhada e harmonizada. Espero que fique claro que está longe de ser uma solução de silos fragmentados de dados inacessíveis.
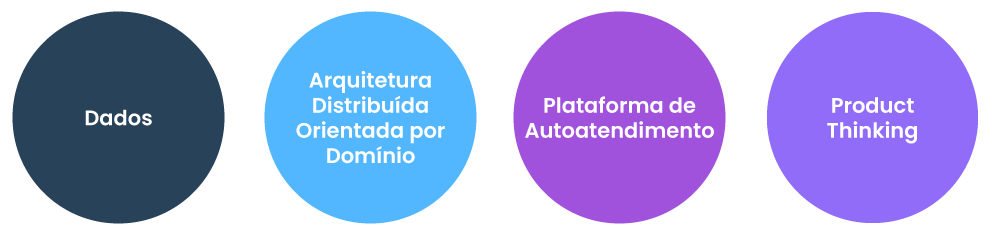
Data Mesh ou Malha de Dados é uma arquitetura de dados emergente para organizar e fornecer dados corporativos e deve ser baseada em 4 principíos:
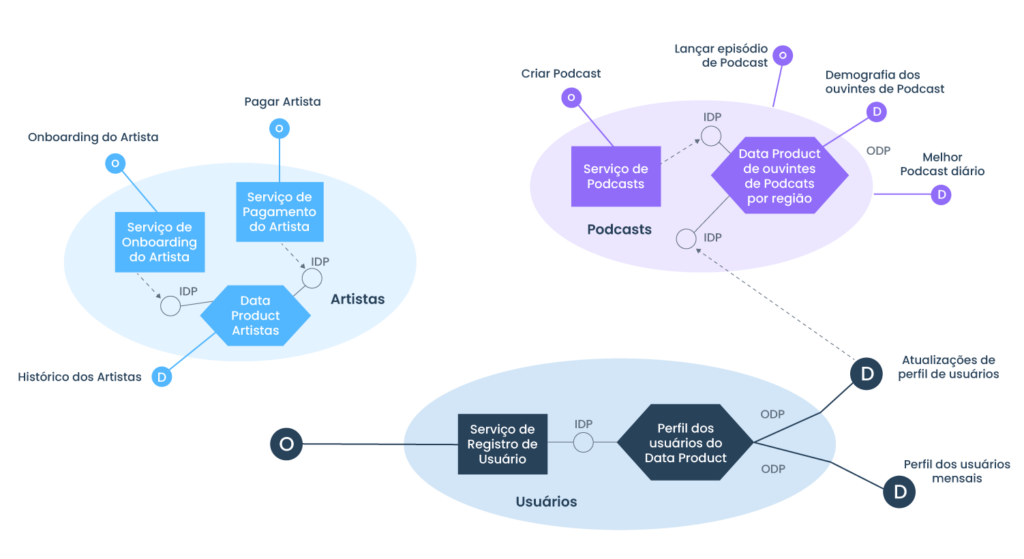
1. Data Product
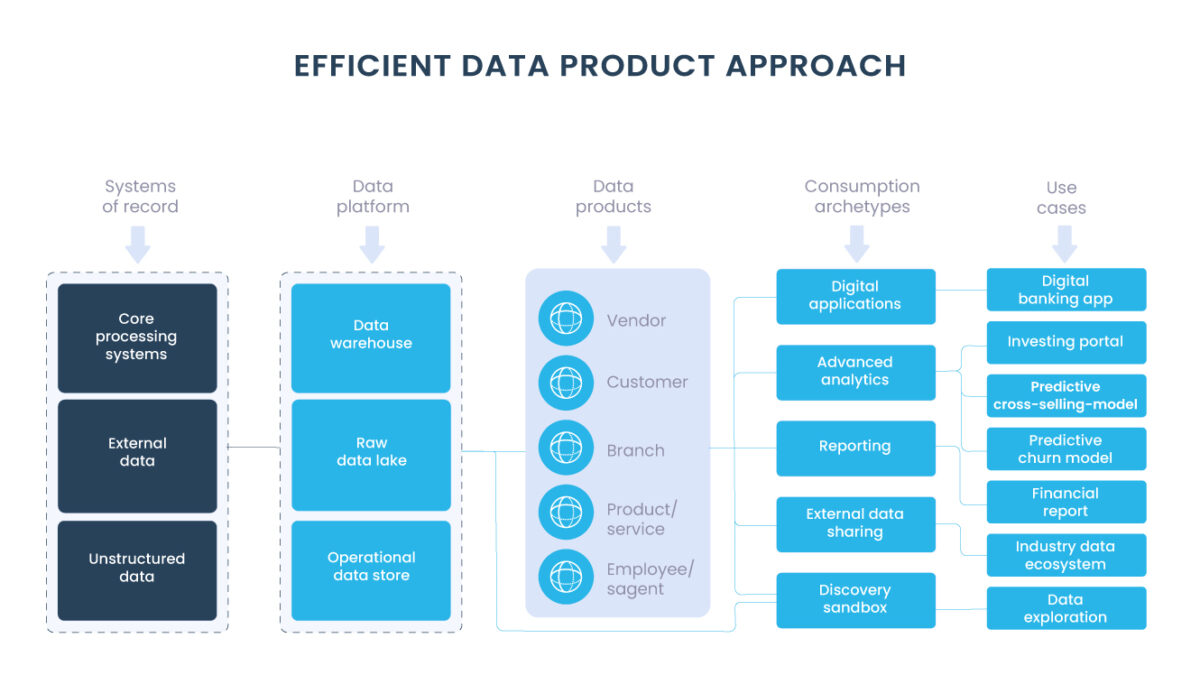
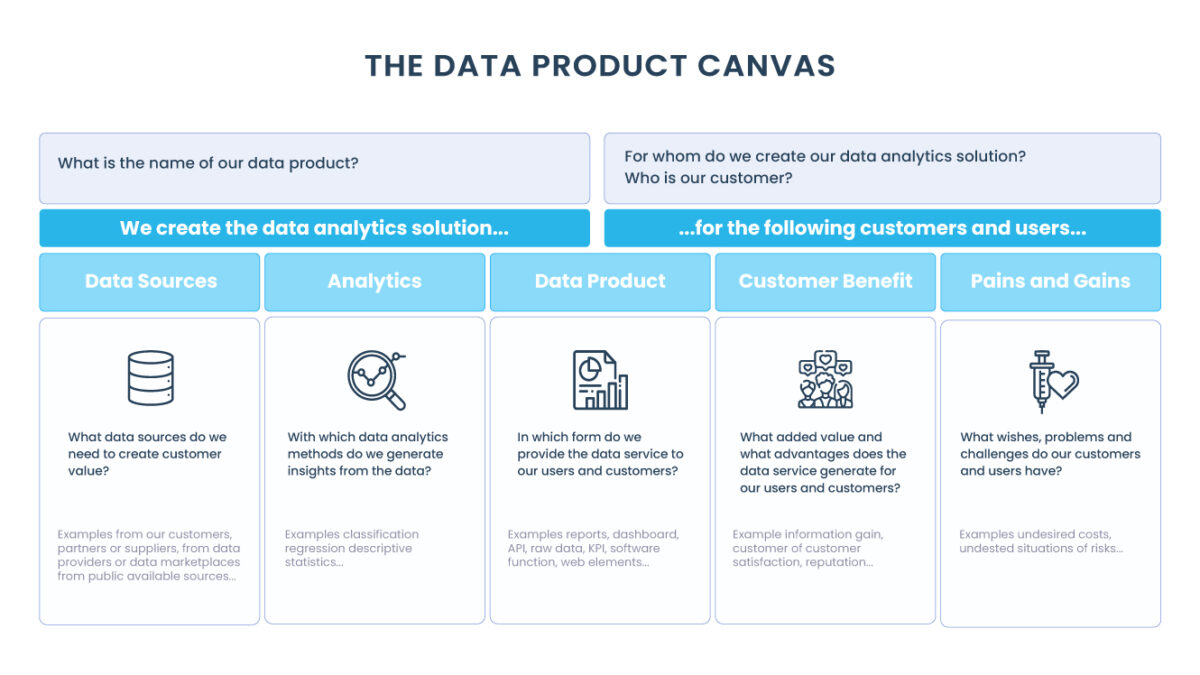
Os dados analíticos fornecidos pelos domínios devem ser tratados como um produto, e os consumidores desses dados devem ser tratados como clientes, clientes felizes e encantados. Os produtos de dados devem ser compostos por dados limpos, atualizados e completos, dessa forma são entregues a qualquer consumidor de dados, a qualquer hora, em qualquer lugar, com base em permissões e funções.
Existe uma maneira melhor de construir e administrar uma organização de dados, execute-a como se você estivesse construindo um produto de dados e todos os seus colegas fossem seus clientes. Acreditamos que isso tem a capacidade de transformar a organização e ajudar as equipes a alcançar seu verdadeiro potencial.
Na mentalidade da organização de serviço, a oportunidade é desperdiçada. Mas quando você começa a ver seus dados como um produto que ajuda a orientar as decisões, então você tem a chance de maximizar o potencial.
2. Orientado ao domínio de negócios
É o que reduz a dependência de equipes de dados centralizadas (geralmente incluindo engenheiros de dados e cientistas de dados).
Quando os usuários de negócios/empresas são forçados a trabalhar com engenheiros de dados ou cientistas de dados fora de seu domínio, fornecer os dados certos, para os consumidores de dados certos, no momento certo, é demorado, muitas vezes propenso a erros e, em última análise, ineficaz.
Em comparação com as abordagens tradicionais de arquitetura de dados que promovem o isolamento das equipes, o Data Mesh propõe uma solução em que os especialistas e proprietários de domínio de dados devem estar no comando. Isso ocorre por meio de maior conhecimento do domínio, equipes de negócios e de TI mais próximas, além de equipes virtuais ágeis.
Na implementação do data mesh, cada domínio de negócios mantém o controle sobre todos os aspectos de seus produtos de dados para casos de uso analíticos e operacionais, em termos de qualidade, atualização, conformidade de privacidade, etc. E é responsável por compartilhá-los com outros domínios (departamentos na empresa).
3. Plataforma de dados Self Service (simplificação)
A única maneira que as equipes podem obter de forma autônoma seus produtos de dados é ter acesso a uma abstração de alto nível da infraestrutura que remove a complexidade e o atrito do provisionamento e gerenciamento do ciclo de vida dos produtos de dados. Isso exige um novo princípio, a infraestrutura de dados de autoatendimento como plataforma para permitir a autonomia do domínio.
- NoOps
- Multicloud + Cloud First
- Data Sharing + Data Governance
Habilitado por novos níveis de abstração e automação , projetado para compartilhar dados relevantes de forma multifuncional, sob demanda.
4. Governança de dados consistente
Cada domínio governa seus próprios produtos de dados, mas depende do controle central de modelagem de dados, políticas de segurança e conformidade.
Encontrar um equilíbrio entre o que deve ser padronizado globalmente, implementado e aplicado pela plataforma para todos os domínios e seus produtos de dados, e o que deve ser deixado para os domínios decidirem, é uma arte. O modelo de dados de domínio é uma preocupação que deve ser localizada em um domínio que esteja mais intimamente familiarizado com ele.
Por exemplo, como a semântica e a sintaxe do modelo de dados de ‘audiência de podcast’ são definidas devem ser deixadas para a equipe de ‘domínio de podcast’. No entanto, em contraste, a decisão sobre como identificar um ‘ouvinte de podcast’ é uma preocupação global.
De fato ainda estamos iniciando o entendimento deste novo modelo emergente, acredito que os 4 conceitos chaves acima são inquestionáveis e requerem priorização das empresas, em busca de entregar mais resultados para a organização e reduzir o TCO na produtização de dados.
Conclusão
Independente da discussão sobre Data Mesh e suas nuances, que será inevitável assim como aconteceu na engenharia de software com os microsserviços, todas as organizações deveriam estar priorizando transformar o modelo de Data & Analytics centralizado na TI em uma esteira de produtização de dados de toda a empresa. Sendo os dados a principal matéria prima do século, precisa ser tratado como produto, especializado por domínios de negócios e distribuído por soluções self service para tomadas de decisões ágeis, tudo isso com governança ágil e efetiva.
A triggo.ai é especialista em Data Analytics & AI, pioneira em Data Product e DataOps, e pode apoiar sua empresa nesta jornada de produtização de dados para aumentar o ROI e acelerar a gestão Data Driven. Fale com um dos nossos especialistas!