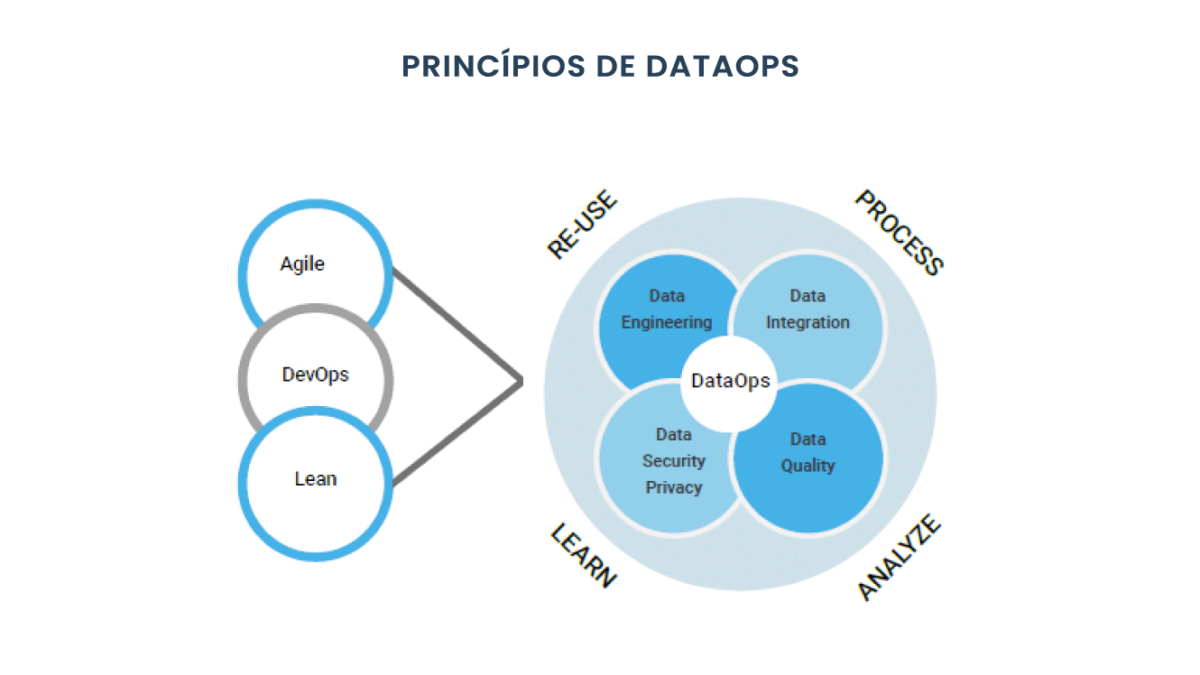
Data Mesh, Data Fabric e Active Metadata – o Futuro da Arquitetura de Dados
Neste, artigo nossa intenção é deixar claro a importância de abordar o Active Metadata como um tema que exige a mesma relevância que as empresas colocam para falar de arquitetura de fundação de dados com Data Mesh e Data Fabric, por exemplo.
A corrida “armamentista” que se seguiu para contratar mais cientistas de dados, comprar mais tecnologia e adquirir mais dados, inovando loucamente, não resultou, necessariamente, em organizações Data Driven (empresas orientadas por dados). Uma abordagem ATIVA para a gestão de metadados ajudaria a mudar as estratégias de dados de um modelo baseado na “aquisição” para um modelo baseado no “consumo”.
Já abordamos conceitos correlatos com a visão de Data & AI Product em alguns artigos anteriores como:
Dessa vez, vamos nos aprofundar ainda mais neste temas para irmos ao cerne das questões arquiteturais relevantes envolvendo Data Mesh, Data Fabric e Active Metadata.
A complexidade dos negócios atuais exige uma arquitetura de dados flexível
Alinhe os requisitos de dados aos casos de uso. Esses use cases, distribuídos e complexos, estão agora impulsionando inovações mais recentes que agregam valor aos negócios ao permitir o acesso aos dados de forma democratizada. O sucesso dependerá da capacidade de satisfazer os casos de uso dos consumidores da empresa (times de negócios e usuários), que são provavelmente distribuídos nos domínios, próximos às fontes de dados, operando em malhas e tecnologias de ponta usando GenAI (IA generativa).
Vamos começar com algumas definições importantes:
O que é Data Mesh?
Data Mesh, também conhecido como Malha de Dados, é uma abordagem de gerenciamento de dados (embora não seja uma prática recomendada estabelecida) que apoia uma prática liderada por domínio para definir, entregar, manter e governar produtos de dados.
Você pode se aprofundar mais e entender como funciona o Data Mesh, quais são seus princípios e pilares acessando nosso artigo sobre o tema: Os 4 princípios do Data Mesh.
O que é Data Fabric?
Data Fabric é um design emergente de gerenciamento de dados para obter uma administração de dados flexível, reutilizável e aumentada (ou seja, melhor semântica, integração e organização de dados) por meio de metadados.
O que é Active Metadata?
Active Metadata, também conhecido apenas como metadados, são dados que descrevem várias facetas dos ativos de dados, fornecendo o contexto dos dados e melhorando a nossa compreensão sobre eles ao longo do seu ciclo de vida.
Se você quiser conhecer um pouco mais sobre Active Metadata, acesse nosso artigo: Data Catalog – Modern Data Stack
Qual é a diferença entre Data Fabric e Data Mesh?
Data Fabric e Data Mesh são conceitos desenvolvidos de forma independente, frequentemente usados de forma complementares. Embora compartilhem o mesmo objetivo de fácil acesso aos dados, eles são diferentes.
- Data Fabric é um padrão de tecnologia orientado por metadados para automatizar tarefas de gerenciamento de dados por meio de acesso unificado.
- Data Mesh é uma abordagem de arquitetura impulsionada pela federação de responsabilidades de gerenciamento de dados por meio de governança distribuída.
Nas circunstâncias certas, o Data Fabric e Data Mesh podem ser complementares.
Mesh é o objetivo e depende muito da cultura de dados e maturidade junto aos times de negócios de toda a organização. Fabric é o meio que está intimamente ligado a governança e cuidado nos detalhes do processo de equalizar os dados de diversos produtores com diversos consumidores e contextos para que possam ser consumidos de forma ampla e confiável.
A arquitetura de dados está evoluindo para fornecer autoatendimento de dados habilitado por metadados
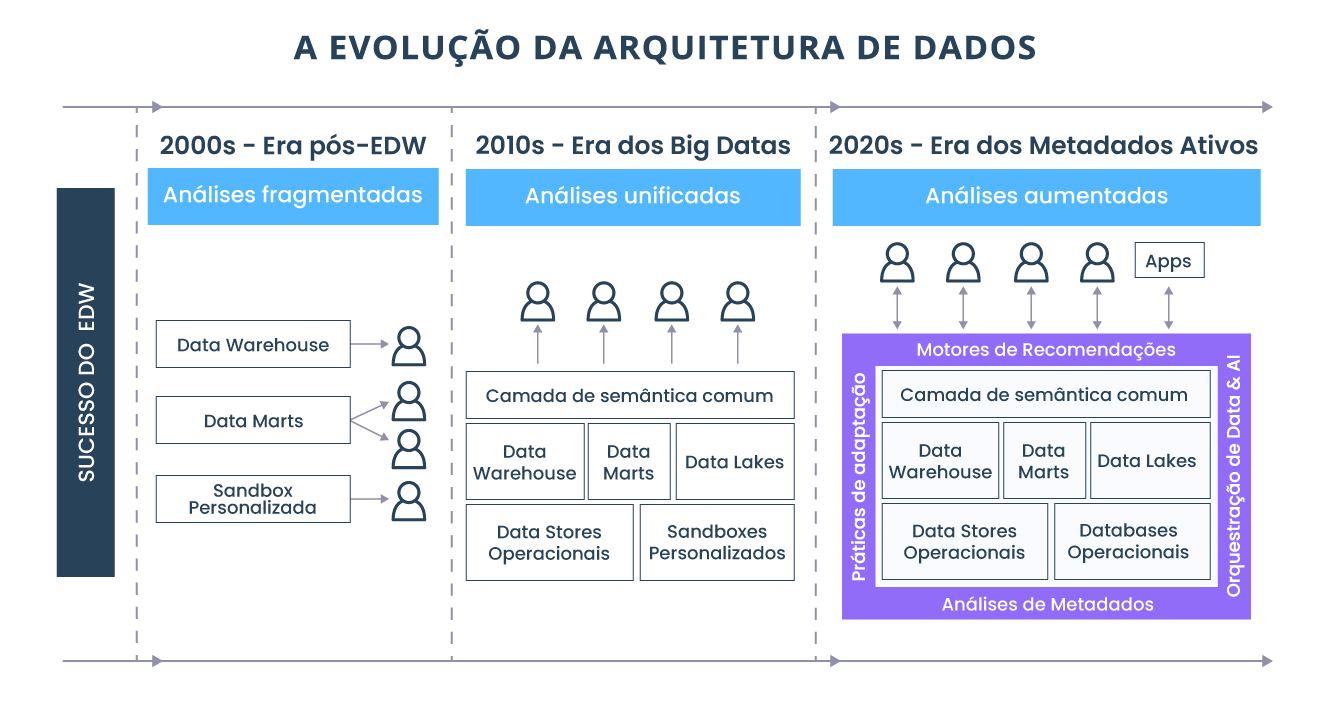
As melhores práticas de arquitetura de análise de dados passaram por várias eras nas últimas décadas, à medida que as iniciativas de transformação digital destacaram a necessidade de modernizar a estratégia de dados e aproveitar as oportunidades de utilização dos dados. Essas eras incluem:
- Período anterior a 2000 — Era do Enterprise Data Warehouse: arquitetura de dados centrada no sucesso do Enterprise Data Warehouse (EDW).
- 2000-2010 — Era pós-EDW: este período é definido pela análise de dados fragmentados, em que os Data Marts dependiam do Data Warehouse. E, dependendo de para quem você perguntasse, havia uma versão diferente da verdade, pois cada consolidação de Data Mart levava a um outro silo de dados, gerando análises fragmentadas e inconsistentes.
- 2010-2020 — Era de Big Data com Data Lakes e Data Warehouses: este período assistiu a uma análise mais unificada de dados através de uma tentativa de camada semântica comum, que permitiu o acesso a Data Warehouses, Data Marts e Data Lakes. Este seria um desejo e a melhor prática, porém seus desafios foram gigantescos.
- Futuro 2020 — Era dos Metadados Ativos com Data Mesh e Data Fabric: o futuro verá uma análise aumentada de dados usando todas as fontes relevantes, acessadas e habilitadas por análises avançadas, mecanismos de recomendação, orquestração de dados e IA, práticas adaptativas e análise de metadados.
Data Mesh: embora atraente, requer uma abordagem cuidadosa!
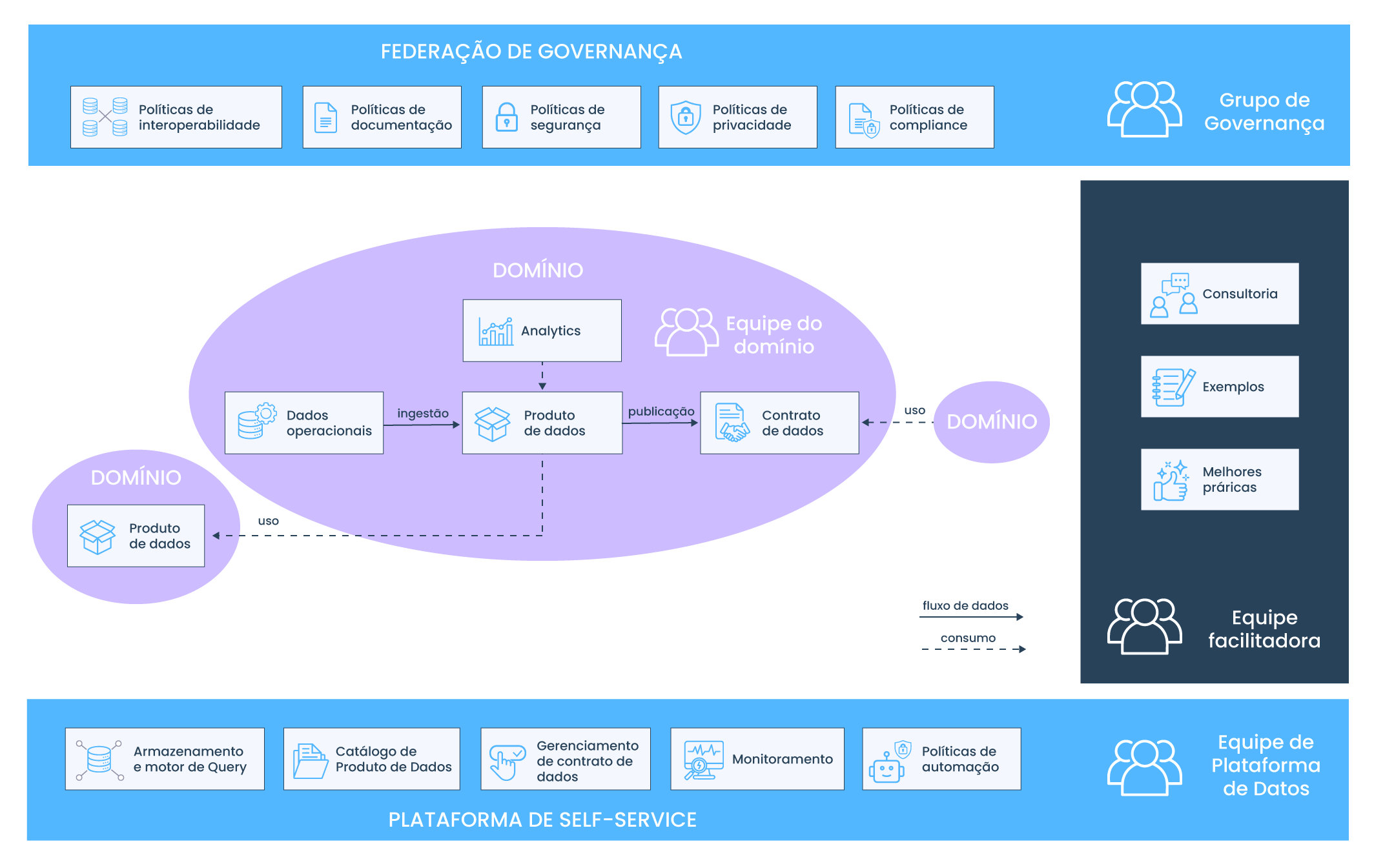
O antigo termo usado “Gerenciamento para metadados” implica em um processo manual, uma estratégia humana que é apoiada por ferramentas e tecnologia. Dada a quantidade de dados (e metadados) gerados diariamente, agora é necessário lançar mão de ferramentas e tecnologia que sejam dimensionadas de acordo com a quantidade de dados consumidos.
Se continuarmos a pensar na gestão de metadados como uma tarefa fundamentalmente manual e apoiada pela tecnologia, limitaremos a nossa capacidade de realizá-la de forma eficaz. Embora seja uma analogia útil, a verdade é que comparar o gerenciamento de metadados corporativos a uma biblioteca, por exemplo, é falho. Mesmo muitos bibliotecários levariam muito tempo para organizar um milhão de livros (estamos na era exponencial).
Os metadados “ativos” tentam recalibrar essa ideia, tornando os metadados um problema computacional em vez de um problema gerencial. Ele muda o processo de gerenciamento de metadados de uma operação passiva e estática para uma operação ativa e contínua.
Os metadados ativos significam que tanto os metadados em si quanto o gerenciamento estão ativos. O que queremos dizer com isso?
- Esses metadados devem mudar à medida que os próprios dados mudam. À medida que os dados são utilizados, atualizados e modificados, os metadados devem ser continuamente gerados, recolhidos e indexados.
- A gestão tradicional de metadados deve ser automatizada através de APIs e IA em um futuro bem próximo, permitindo uma abordagem rápida e colaborativa para a gestão de metadata. além do fluxo mais orientado a produto de dados que abordamos frequentemente nos projeto da triggo.ai, por exemplo.
Por que deveríamos nos importar com Metadados?
Simplificando, o valor dos dados depende da capacidade de usá-los de maneira eficaz, e os metadados são o que torna os dados utilizáveis. As práticas tradicionais de metadados são insuficientes.
Percebendo a oportunidade proporcionada por um maior acesso aos dados, organizações com visão de futuro desenvolveram estratégias focadas em encontrar novas fontes de dados. Esses modelos de “aquisição” enfatizam excessivamente a importância dos metadados descritivos (ajude-me a encontrar o que procuro) e despriorizam os metadados administrativos e estruturais (aquilo que ajuda você a usar o que encontrou).
Muitas organizações pensam que já descobriram a parte do consumo: um Data Lake, um ETL e uma frota de cientistas de dados. Mas o consumo não consiste apenas em trazer dados para um ambiente; trata-se também de trazer à tona esses dados de forma que permitam o uso, a reutilização e a experimentação.
“As empresas não ganham criando melhores Data Lakehouses; elas ganham por serem melhores em usá-los.”
Os metadados ativos são mais do que um ajuste de nomenclatura do pessoal do Gartner; é uma reinterpretação crítica de como as empresas podem vencer em um ambiente rico em dados e criar Data Products confiáveis, com valor para resolver muitas questões de negócios.
Data Mesh é uma abordagem arquitetônica que permite o gerenciamento descentralizado de dados. O seu objetivo é apoiar os esforços para definir, fornecer, manter e governar produtos de dados de uma forma que os torne fáceis de encontrar e serem utilizados pelos consumidores de dados.
A arquitetura de Data Mesh é baseada no conceito de descentralização e distribuição da responsabilidade dos dados para as pessoas que estão mais próximas (dos dados) e no compartilhamento desses como um serviço.
Os impulsionadores mais comuns para Data Mesh são:
- Maior autonomia de dados para linhas de negócios;
- Menos dependência da TI central;
- Aproveitamento da descentralização de dados para quebrar silos (embora possa ser garantida alguma centralização de dados dentro de uma arquitetura de malha).
Apesar do seu apelo óbvio, esteja ciente dos seguintes pré-requisitos e desafios de trabalhar com Malha de Dados.
A arquitetura de Data Mesh ainda não é uma prática recomendada para todas as empresas
O termo está associado a abordagens variadas que diferem pelo modelo organizacional, gestão dos dados e implementação de tecnologia. Os motivadores organizacionais também variam. Eles incluem a remoção da TI como um gargalo e a racionalização de conjuntos de dados isolados, resultantes da criação de pipeline de dados liderado por negócios ou desencadeados por uma iniciativa de gerenciamento de dados de modernização da nuvem.
Os líderes de análise de dados não devem adotar a arquitetura de Data Mesh como uma solução aparentemente fácil para os seus desafios de gestão de dados. Embora formalize práticas comuns, abdica da responsabilidade dos dados perante especialistas de negócios, correndo o risco de proliferar utilizações isoladas de dados, formando os famosos silos.
O sucesso do uso de Data Mesh depende do modelo organizacional e das habilidades de dados nas áreas de negócios
Se a alfabetização de dados (Data Literacy), a autonomia e as competências em dados variarem muito entre os departamentos, e se as organizações não tiverem capacidade para operacionalizar atividades de gestão desses dados, a TI central terá de fornecer mais apoio, pelo menos no início.
Os owners de negócios podem evoluir em direção a uma maior autonomia dentro de um ambiente de Data Mesh, criando novas funções, como owner de produtos de dados, para gerenciar a definição, criação e governança de Data Products. No entanto, as organizações que não estão comprometidas com o desenvolvimento de competências em dados distribuídos devem evitar a arquitetura de Data Mesh.
A arquitetura, o design e a implementação da tecnologia para Data Mesh variam muito
As implementações de arquitetura de Data Mesh são baseadas em nuvem e usam armazenamento e processamento compartilhados. No entanto, as ferramentas utilizadas com cada área de negócio para a entrega, manutenção e governança de dados variam muito com base nos casos de uso e no contrato entre o produtor e o consumidor. Esses contratos definem o escopo, os SLAs e o custo das operações dos produtos de dados, como disponibilidade, custos de computação, simultaneidade de acesso, políticas de governança e qualidade, contexto e semântica.
As organizações que prosseguem sem contratos claros em vigor enfrentam frequentemente restrições de partilha e reutilização, o que vai contra os objetivos de desenvolvimento de uma arquitetura de Malha de Dados.
As organizações precisam de um modelo de governança federada
Data Mesh transfere a responsabilidade pela governança de dados para designers e usuários de aplicações de domínio. Para que uma área de negócios construa e exponha produtos de dados de forma autônoma, ela deve definir a governança e o gerenciamento de dados locais que cumpram a orientação central do diretor de segurança da informação (CISO) e do diretor de dados (CDO) ou do conselho de governança central. Em empresas com maturidade em Data Mesh, a organização impõe as suas próprias políticas de governança com suporte central de TI, e não o contrário.
Data Mesh é uma opção viável para organizações com metadados incompletos. Desde que tenham arquitetos de dados com experiência no assunto, eles podem começar com a Malha de Dados e construir seus ativos de metadados em paralelo.
Data Fabric aproveita os ativos existentes da arquitetura moderna
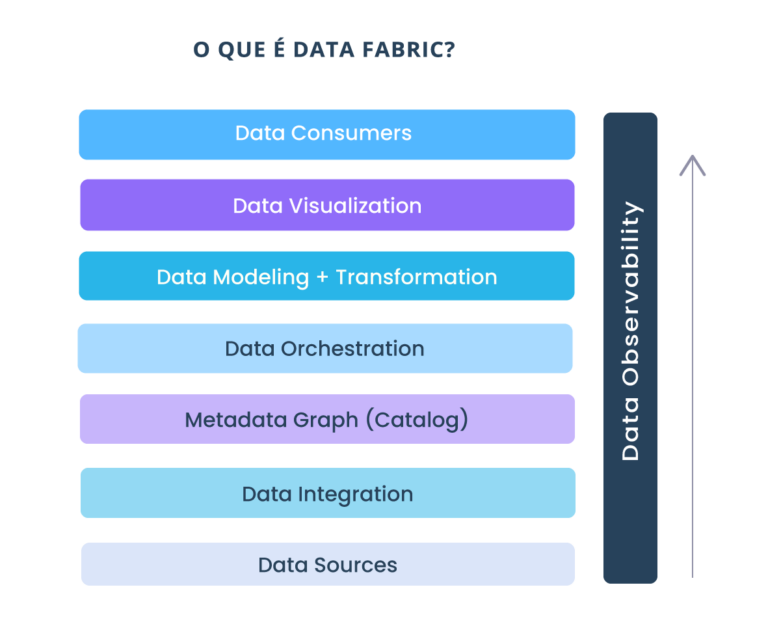
Data Fabric é um conceito emergente de gerenciamento de dados e design de integração de dados. Seu objetivo é obter integração de dados flexível, reutilizável e aumentada para dar suporte ao acesso a dados em toda a empresa.
Data Fabric é uma evolução natural para muitas organizações de seus modelos lógicos de dados porque aproveita a tecnologia e os metadados existentes em uma arquitetura de dados modernizada. Não há “exclusão e substituição” em um design de Data Fabric. Em vez disso, capitaliza os custos irrecuperáveis e, ao mesmo tempo, fornece orientação sobre priorização e controle de custos para novos gastos com gerenciamento de dados.
Data Fabric oferece benefícios em diferentes perspectivas:
- Perspectiva de negócios: permite que usuários de negócios menos técnicos (incluindo analistas) encontrem, integrem, analisem e compartilhem dados rapidamente;
- Perspectiva da equipe de dados: oferece vantagens de produtividade decorrentes do acesso e integração automatizados de dados para engenheiros de dados e maior agilidade, resultando em mais fechamentos de demandas de dados por dia/semana/ano;
- Perspectiva geral da organização: aumenta a velocidade para obtenção de insights a partir de investimentos em dados e análises; melhora a utilização de dados organizacionais; apresenta custo reduzido analisando os metadados em todos os sistemas participantes e fornecendo insights sobre design, entrega e utilização eficazes de dados.
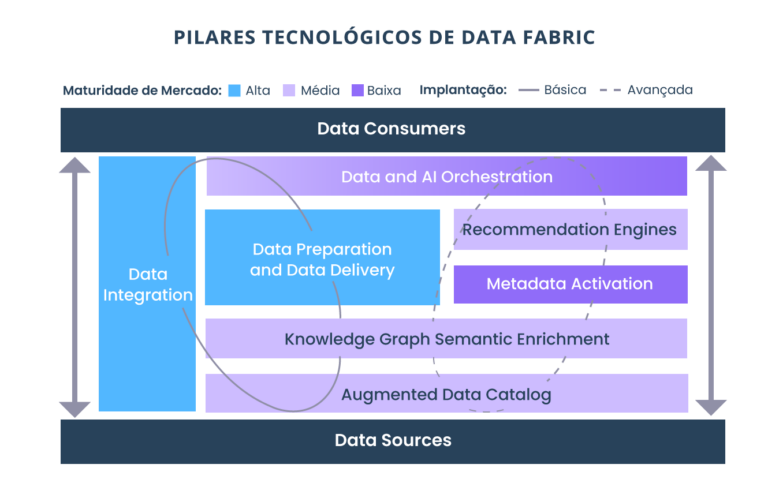
Os dois fatores que determinam se um design de Data Fabric é adequado para uma determinada organização são: integridade dos metadados e experiência no assunto da Data Fabric na organização.
Um ponto a avaliar é que as organizações com poucos metadados não verão os benefícios da Data Fabric. A falta de metadados também aumenta a dependência de especialistas no assunto que podem ajudar na descoberta, inferência e até mesmo na criação de metadatas, o que pode anular os requisitos relativamente baixos para um design de arquitetura de dados.
A democratização do acesso aos dados e da análise de autoatendimento está motivando a evolução atual da Era Big Data para a Era dos Metadados Ativos (Data) & AI, a partir de arquitetura com Lakehouse, Data Mesh, Fabric e GenAI.
Os diretores de dados e análises (CDAOs) também esperam expandir os casos de uso de dados além daqueles que os Lakehouses podem lidar. Isso inclui gerenciamento de dados mestres, compartilhamento de dados entre empresas, integração de dados B2B, compartilhamento de dados de parceiros, integração de dados entre aplicações e outros.
Mas o que são metadados e qual o papel que desempenham nesta evolução?
Os metadados descrevem diferentes facetas dos dados, como o contexto deles. Ele é produzido como um subproduto da movimentação de dados pelos sistemas corporativos.
Existem quatro tipos de metadados:
- Técnicos;
- Operacionais;
- Corporativos;
- Sociais.
Cada um desses tipos podem ser metadados “passivos”, que as organizações coletam, mas não analisam ativamente, ou metadados “ativos”, que identificam ações em dois ou mais sistemas que utilizam os mesmos dados.
Os metadados ativos podem permitir a automação, fornecer insights e otimizar o envolvimento do usuário, além de serem um facilitador essencial da análise de autoatendimento. A realização do seu potencial, no entanto, requer uma arquitetura de dados que equilibre os requisitos de repetibilidade, reutilização, governação, autoridade, proveniência e entrega otimizada.
Conclusão
Os líderes de análise de dados veem duas opções para evoluir sua arquitetura de dados da Era de Big Data, onde a maioria opera hoje, em direção à Era dos Metadados Ativos. Essas opções são Data Fabric ou Data Mesh. Esses conceitos separados compartilham o objetivo de fornecer acesso mais fácil aos dados para todos que os utilizam, incluindo cientistas, analistas e engenheiros de dados, bem como consumidores de dados.
Embora muitos líderes de dados falem sobre a Data Fabric e Data Mesh como abordagens concorrentes de arquitetura de dados, na verdade, como já falamos anteriormente: elas são vistas com mais precisão como complementares.
A triggo.ai é uma empresa especializada em Data & AI Product Management e poderá ajudá-lo a atingir os melhores resultados na implementação de arquiteturas de Data Mesh e Data Fabric, gerando produtos de dados e de inteligência artificial, de forma rápida e objetiva. Se você quiser entender melhor como podemos te apoiar nesta jornada, fale com um dos nossos especialistas!