
Vector Database e sua relação com a IA
Um Vector Database é um banco de dados projetado para armazenar, gerenciar e indexar com eficiência grandes quantidades de dados vetoriais de alta dimensão. Ou seja, qualquer banco de dados que permita armazenar, indexar e consultar incorporações vetoriais ou representações numéricas de dados não estruturados, como texto, imagens ou áudio.
O interesse pelos bancos de dados vetoriais está crescendo rapidamente em fução de criar valor adicional para casos de uso e aplicações de inteligência artificial (IA) generativa.
Estamos no meio da revolução da IA. O processamento eficiente de dados tornou-se mais crucial do que nunca para aplicações que envolvem LLM, IA generativa e pesquisa semântica.
Falamos muito sobre isso em nossos artigos sobre GenAI, abordando LLM, RAG e outros temas importantes que podem ser usados de forma complementar a este conteúdo para entendermos sobre Vector Database.
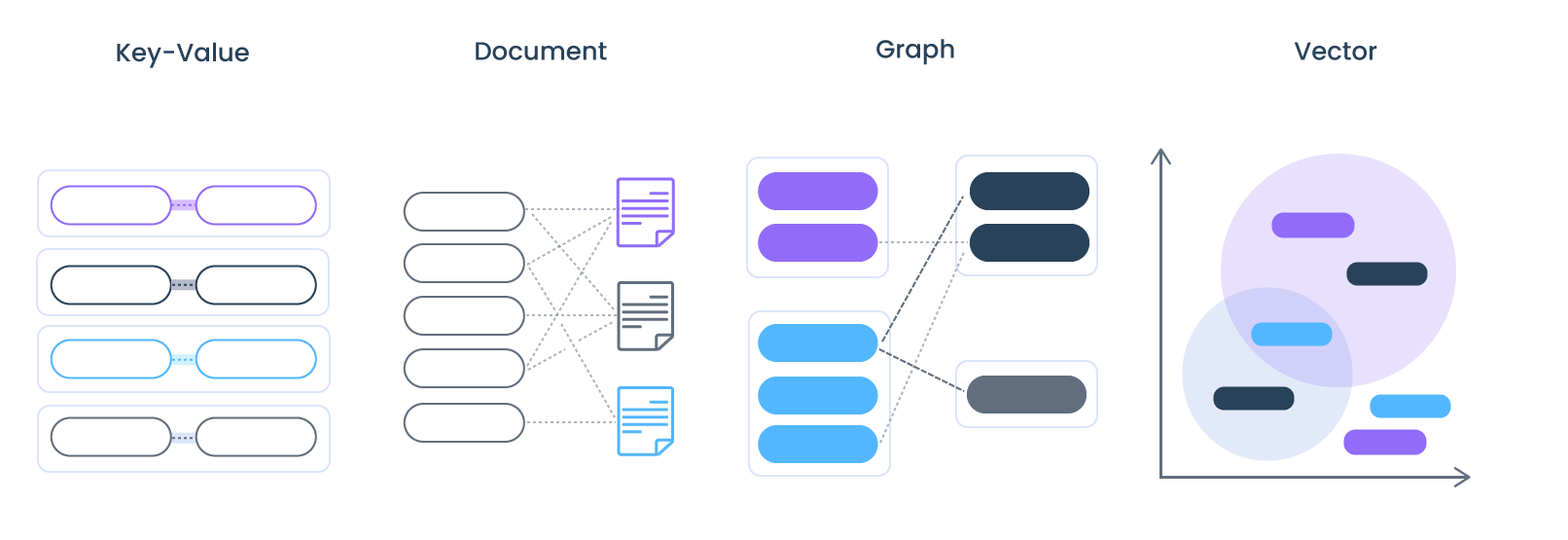
Todas essas novas aplicações dependem de incorporações vetoriais, um tipo de representação de dados vetoriais que carrega consigo informações semânticas que são críticas para que a IA obtenha compreensão e mantenha uma memória de longo prazo que possa utilizar ao executar tarefas complexas.
Um pouco da história sobre Vector Databases
Vector Databases têm suas raízes em técnicas mais antigas de processamento de linguagem natural e recuperação de informação, mas o conceito moderno realmente começou a ser desenvolvido e usado de forma mais difundida nos últimos anos, especialmente com o aumento do interesse em inteligência artificial e aprendizado de máquina.
Um marco importante foi o desenvolvimento e popularização das chamadas “embeddings” de palavras (como o Word2Vec, GloVe, etc.), que são técnicas que mapeiam palavras para vetores numéricos em espaços dimensionais. Isso permitiu representar o significado das palavras de uma forma mais eficaz e foi fundamental para o desenvolvimento de sistemas de processamento de linguagem natural baseados em aprendizado de máquina.
Além disso, com o aumento da quantidade de dados disponíveis e o desenvolvimento de algoritmos mais eficientes para cálculos vetoriais, como algoritmos de busca aproximada de vizinhos mais próximos (na sigla em inglês ANN – Approximate Nearest Neighbors), os bancos de dados vetoriais se tornaram uma opção mais viável para armazenar e consultar grandes volumes de dados.
Nos últimos anos, vimos um aumento significativo no uso de Vector Databases em uma variedade de aplicações, incluindo sistemas de recomendação, análise de sentimentos, pesquisa visual e muito mais. Empresas como Google, Facebook, Amazon e outras têm usado amplamente essas tecnologias para melhorar a experiência do usuário e oferecer serviços mais personalizados.
Como o Vector Database ajuda nos desafios de IA?
Os embeddings são gerados por modelos de IA (como LLMs) e possuem muitos atributos ou recursos, tornando sua representação difícil de gerenciar. No contexto da IA e do aprendizado de máquina, esses recursos representam diferentes dimensões dos dados que são essenciais para a compreensão de padrões, relacionamentos e estruturas subjacentes.
O desafio de trabalhar com dados vetoriais é que os bancos de dados tradicionais baseados em escalar não conseguem acompanhar a complexidade e a escala desses dados, dificultando a extração de insights e a realização de análises em tempo real. É aí que entra o Vector Database: ele é projetado intencionalmente para lidar com esses tipos de dados e oferece o desempenho, a escalabilidade e a flexibilidade que você precisa para aproveitar ao máximo seus dados.
Vector Databases e os bancos de dados NoSQL, especialmente os bancos de dados de busca (search databases), são conceitos um pouco diferentes, mas podem ser usados em conjunto para casos de uso específicos. Aqui estão as principais características de um Vector Database:
- Modelo de Dados
Armazenam dados em formatos vetoriais, o que significa que os dados são representados por vetores numéricos (ou seja, listas de números) que podem ser usados em cálculos matemáticos; - Consulta
As consultas geralmente envolvem cálculos matemáticos, como similaridade de vetores ou projeções de vetores; - Escalabilidade
A escalabilidade pode depender da capacidade de processamento disponível para cálculos vetoriais; - Casos de Uso
São frequentemente usados em aplicações que envolvem processamento de linguagem natural, análise de sentimentos, recomendação de conteúdo, entre outros, onde a representação vetorial é útil.
Com um Vector Database, podemos agregar conhecimento às nossas IAs, como recuperação semântica de informações, memória de longo prazo e muito mais. O diagrama abaixo nos dá uma melhor compreensão do papel de um Vector Database neste tipo de aplicação:
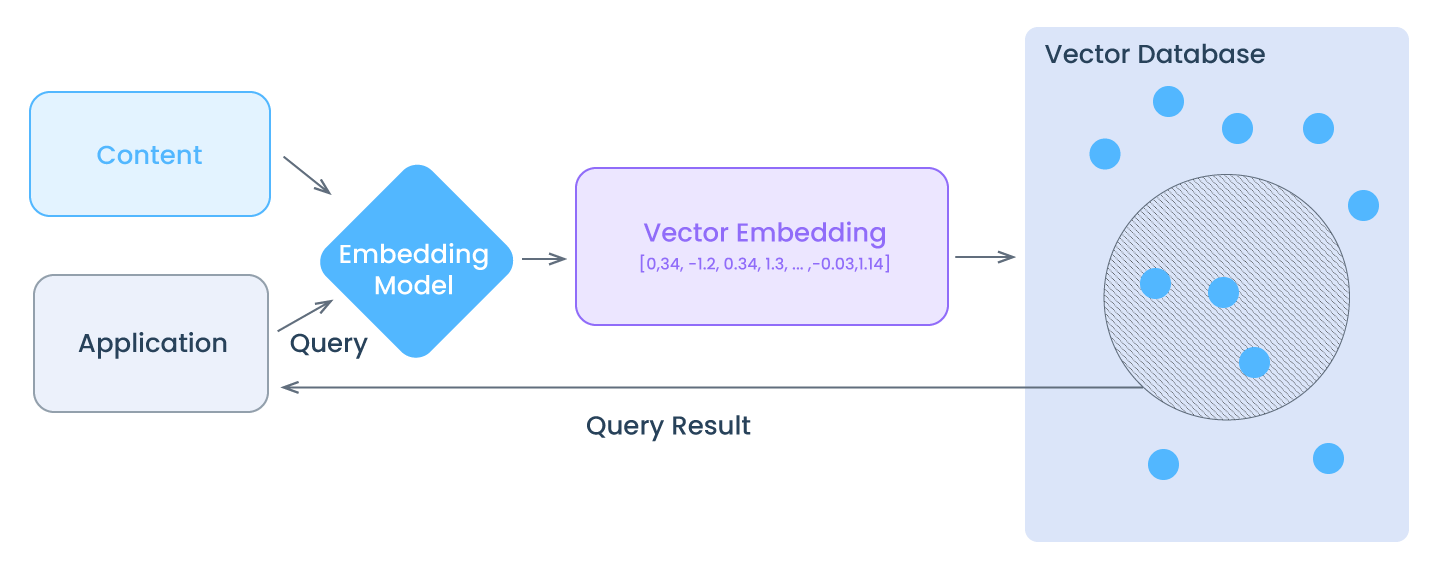
Imagine que você tem um conjunto de documentos de texto, como artigos de jornal, e deseja criar um banco de dados para armazená-los de uma forma que permita pesquisas rápidas e eficientes.
- Tokenização: primeiro, cada documento é dividido em palavras ou tokens. Por exemplo, a frase “O cachorro correu para o parque” seria dividida em [“O”, “cachorro”, “correu”, “para”, “o”, “parque”];
- Vetorização: em seguida, cada palavra é representada por um vetor numérico. Isso é feito usando técnicas como a incorporação de palavras (word embeddings), que mapeiam cada palavra para um vetor em um espaço dimensional. Por exemplo, a palavra “cachorro” pode ser representada por um vetor como [0.5, -0.3, 0.8, …];
- Representação do Documento: para representar um documento inteiro, como um artigo de jornal, todas as palavras do documento são combinadas para formar um vetor médio ou ponderado. Isso cria uma representação vetorial do documento, onde cada dimensão do vetor representa um aspecto diferente do significado do documento;
- Armazenamento: as representações vetoriais de todos os documentos são armazenadas em um banco de dados, geralmente organizadas de forma que seja fácil encontrar documentos semelhantes com base em cálculos de similaridade vetorial;
- Consulta: quando você faz uma consulta, por exemplo, procurando por documentos relacionados a “cachorro”, a palavra “cachorro” é vetorizada da mesma forma que os documentos, e o banco de dados é consultado para encontrar os documentos cujas representações vetoriais são mais semelhantes ao vetor da palavra “cachorro”.
Essa é uma simplificação do processo, que ajuda a entender como um Vector Database pode funcionar. Ele permite que você armazene e consulte grandes quantidades de dados de forma eficiente, especialmente em casos onde a similaridade semântica é importante, como em pesquisas de texto.
Todos nós sabemos como funcionam os bancos de dados tradicionais (em resumo): eles armazenam strings, números e outros tipos de dados escalares em linhas e colunas. Por outro lado, um Vector Database opera em vetores, portanto a forma como ele é otimizado e consultado é bem diferente.
Em bancos de dados tradicionais, geralmente consultamos linhas no banco de dados cujo valor geralmente corresponde exatamente à nossa consulta. Em Vector Databases, aplicamos uma métrica de similaridade para encontrar um vetor que seja mais semelhante à nossa consulta.
Um Vector Database usa uma combinação de diferentes algoritmos que participam da pesquisa por vizinho mais próximo aproximado (ANN). Esses algoritmos otimizam a pesquisa por meio de hashing, quantização ou pesquisa baseada em gráfico.
Esses algoritmos são montados em um pipeline que fornece recuperação rápida e precisa dos vizinhos de um vetor consultado. Como o Vector Database fornece resultados aproximados, as principais compensações que consideramos são entre precisão e velocidade. Quanto mais preciso for o resultado, mais lenta será a consulta. No entanto, um bom sistema pode fornecer pesquisa ultrarrápida com precisão quase perfeita.
Aqui está um pipeline comum para um Vector Database:

- Indexação: o Vector Database indexa vetores usando um algoritmo como PQ, LSH ou HNSW (mais sobre isso abaixo). Esta etapa mapeia os vetores para uma estrutura de dados que permitirá uma pesquisa mais rápida;
- Consulta: o Vector Database compara o vetor de consulta indexado com os vetores indexados no conjunto de dados para encontrar os vizinhos mais próximos (aplicando uma métrica de similaridade usada por esse índice);
- Pós-processamento: em alguns casos, o Vector Database recupera os vizinhos mais próximos do conjunto de dados e os pós-processa para retornar os resultados finais. Esta etapa pode incluir a reclassificação dos vizinhos mais próximos usando uma medida de similaridade diferente.
Para permitir consultas ANN para vetores com base na distância de algum outro vetor, um índice vetorial é estruturado de forma que clusters de vetores próximos sejam geralmente agrupados. Os tipos comuns de índices vetoriais podem ser estruturados como um conjunto de listas em que cada lista representa os vetores em um determinado cluster; um gráfico no qual cada vetor está conectado a vários de seus vizinhos mais próximos; árvores nas quais os ramos correspondem a subconjuntos do cluster do nó pai; entre outros. Cada tipo de índice oferece compensações entre velocidade de pesquisa, recuperação, consumo de memória, tempo de criação do índice e outros fatores.
Porém, a maioria das consultas ao banco de dados não se baseia apenas na similaridade semântica. Por exemplo, um usuário pode estar procurando um livro cuja descrição seja semelhante a “uma história comovente sobre uma criança e um cachorro”, mas também deseja limitá-lo a livros abaixo de R$ 40, disponíveis em formato impresso. Vector Database de propósito especial podem fornecer alguma capacidade de filtragem adicional limitada (às vezes chamada de “restrições”), enquanto bancos de dados de uso geral podem compor predicados ricos usando linguagens padrão como SQL, que podem ser combinadas com ordenação de similaridade vetorial para permitir consultas muito poderosas e expressivas.
Casos de uso em Vector Database
As aplicações de Vector Databases são vastas e crescentes. Alguns casos de uso importantes incluem:
Pesquisa semântica: pesquisas com base no significado ou contexto de uma consulta, possibilitando resultados mais precisos e relevantes. Utilizando não apenas palavras, mas também frases podem ser representadas como vetores, a funcionalidade de pesquisa vetorial semântica entende melhor a intenção do usuário do que palavras-chave gerais;
Pesquisa por similaridade: encontrar imagens, texto, dados de áudio ou vídeo semelhantes com facilidade, para recuperação de conteúdo, incluindo reconhecimento avançado de imagem e fala, processamento de linguagem natural e muito mais;
Mecanismos de recomendação: sites de comércio eletrônico, por exemplo, podem usar bancos de dados vetoriais e vetores para representar as preferências do cliente e atributos do produto. Isso permite sugerir itens semelhantes a compras anteriores com base na semelhança vetorial, melhorando a experiência do usuário e aumentando a retenção;
IA de conversação: melhoria nas interações dos agentes virtuais, aprimorando a capacidade de analisar bases de conhecimento relevantes com eficiência e precisão para fornecer respostas contextuais em tempo real às consultas dos usuários, juntamente com os documentos de origem e números de páginas para referência.
A triggo.ai vem atuando na fronteira deste desafio, implementando soluções robustas e inovadoras de IA Generativa e aplicando metodologias de Data & AI Products para elevar e acelerar a jornada Data Driven das organizações. Fale com um de nossos consultores especialistas!


