
O que é LLM Mesh?
Nós, aqui da triggo.ai, somos pioneiros na abordagem de Modern Data Stack e isso nos permite acompanhar bem de perto os avanços tecnológicos e possibilitar que nossos clientes estejam sempre um passo à frente no mercado e prontos para atingirem resultados acima da curva. Entendemos que trabalhar numa velocidade de mudança de maneira segura e contínua é um fator decisivo para o sucesso das organizações no século 21.
À medida que mais e mais organizações experimentam a IA generativa e a implementam em produção, surge uma questão crucial: estas aplicações podem ser seguras e escaláveis num contexto empresarial? A resposta é sim, por meio do LLM Mesh, uma espinha dorsal comum para aplicativos de IA generativa que promete remodelar a forma como as equipes de análise e de TI acessam com segurança modelos e serviços de generative AI.
Nossa parceira de IA, a Dataiku, acaba de posicionar este novo approach baseado em LLM Mesh em seu evento Everyday AI New York, que está acontecendo nos Estados Unidos.
Este artigo resume os principais desafios que o LLM Mesh responde, ou seja, gerenciamento de segurança, desempenho e custo, os principais benefícios que as organizações podem gerar ao aproveitá-lo e como a Dataiku permite que as organizações criem e implantem aplicativos de IA generativa de nível empresarial por meio do LLM Mesh.
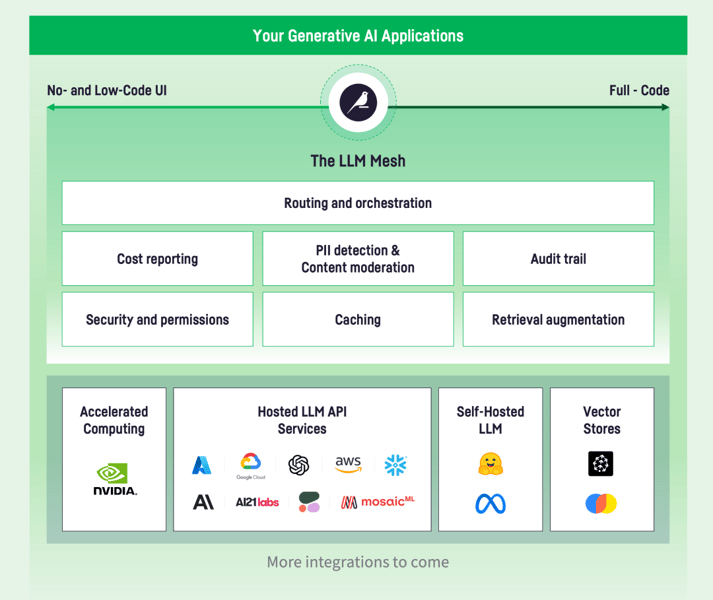
Para construir aplicações de IA generativa que gerem valor sustentado e de curto prazo, as equipes de análise e de TI precisam superar vários desafios importantes. O LLM Mesh foi projetado para abordar:
- Escolha e Dependência: os criadores de aplicativos têm à sua disposição uma escolha crescente de modelos de diferentes fornecedores e isso é bom: diferentes modelos e provedores permitem que as organizações escolham o modelo e o serviço que melhor se adaptam às necessidades de custo, desempenho e segurança de um determinado aplicativo. Dado ao cenário, sempre em rápida evolução, as equipes se beneficiarão se mantiverem suas escolhas abertas em vez de se tornarem vítimas do bloqueio. No entanto, se o aplicativo estiver “conectado” ao modelo ou serviço subjacente, isso dificultará o teste de diferentes modelos na fase de design e criará uma dependência que pode ser difícil e cara de quebrar depois que o aplicativo estiver implantado em produção.
- Custo: criar e executar LLMs é caro e os provedores, naturalmente, repassam esse custo por meio de taxas de API. Portanto, a falha no gerenciamento adequado de solicitações, especialmente em situações de solicitações repetidas, pode resultar em custos imprevistos consideráveis e em sérios problemas para as operações de TI. Embora as equipes de dados avaliem o desempenho dos LLMs com base na precisão, a área de TI precisa se concentrar na latência e nos SLAs.
- Privacidade, segurança e conformidade: os usuários de aplicativos LLM criam prompts que podem transmitir IP ou PII corporativos confidenciais. Esta fuga de dados pode resultar em perda de receitas, multas significativas (dos reguladores) ou num desastre de relações públicas em caso de exposição de tais informações no domínio público. Além disso, os novos regulamentos sobre IA, como a Lei de IA da UE, exigirão que as empresas que utilizam LLMs demonstrem onde estão aplicando a tecnologia e quem tem acesso a ela, provando que estão limitando o risco para os consumidores evitando assim multas significativas.
Finalmente, as respostas dos LLMs podem conter conteúdo impróprio ou mesmo ofensivo (conhecido como toxicidade); permitir que funcionários ou, pior ainda, clientes visualizem esse conteúdo pode impactar seriamente os negócios do ponto de vista de relacionamento com o cliente, jurídico e de relações públicas.
Benefícios do LLM Mesh
Com o LLM Mesh situado entre os provedores de serviços LLM e os aplicativos de usuário final, as empresas têm a agilidade para escolher os modelos mais econômicos para suas necessidades, garantir a segurança de seus dados e respostas, além de criar componentes reutilizáveis para o desenvolvimento de aplicativos escalonáveis. Vamos nos aprofundar um pouco mais em algumas dessas vantagens principais:
Desacoplando aplicação da camada de serviço
Nem sempre fica imediatamente claro qual LLM fornecerá o melhor resultado para o aplicativo que uma equipe está tentando construir. É necessário equilibrar custo, segurança, desempenho e velocidade. Primeiro, na fase de design, o time precisa ser capazes de testar diferentes modelos de forma eficiente para determinar qual funcionará melhor. Então, é importante manter a capacidade de mudar depois que o aplicativo for implantado. Essa dissociação das camadas de aplicação e serviço de IA torna possível projetar os melhores aplicativos possíveis e, em seguida, mantê-los facilmente em produção.
Aplicando um gateway seguro
As práticas padrão de TI determinam que as organizações mantenham um registro completo das consultas executadas em sua infraestrutura. Isto serve tanto para gerenciar o desempenho (identificar o culpado por trás dessa associação ineficiente) quanto para garantir a segurança (saber quem está consultando quais dados e por quais motivos). As mesmas necessidades se traduzem em LLMs.
O LLM Mesh atua como um gateway de API seguro para quebrar dependências codificadas, gerenciando e roteando solicitações entre aplicativos e serviços subjacentes. Um registro totalmente auditável de quem está usando qual LLM, qual serviço e para qual finalidade permite o rastreamento de custos (e a distribuição dos custos internamente), bem como a rastreabilidade total de solicitações e respostas a esses modelos às vezes imprevisíveis.
Segurança, permissões e PII
Quando se trata de triagem de dados privados, o LLM Mesh avalia cada solicitação de informações como dados confidenciais ou proprietários, ou PII do cliente. O sistema então toma uma ação apropriada: redigir essas informações confidenciais antes de enviar a solicitação à API LLM, bloquear totalmente a solicitação e/ou alertar um administrador. Múltiplas formas de detecção de PII coexistem, usando modelos padrão de detecção de PII, aproveitando bancos de dados internos ou usando serviços de terceiros que fornecem recursos avançados ou conhecimento específico do setor.
Em seguida, para reduzir o risco de utilizadores empresariais fazerem pedidos não controlados a chatbots públicos, as empresas podem utilizar serviços LLM pagos com acesso seguro. Esses serviços, como OpenAI, Azure e Google, não capturam informações de solicitação para treinamento de modelo. O LLM Mesh fornece acesso central aos serviços de IA, incluindo a proteção de chaves de API, o que permite acesso controlado aos serviços LLM e agiliza o desenvolvimento e manutenção de aplicativos porque as chaves não são codificadas nos aplicativos.
Controle de custos e desempenho
O LLM Mesh monitora o custo por consulta aos LLMs e agrega custos por aplicativo e serviço. Isso permite que as equipes prevejam custos e tomem decisões informadas sobre o uso do serviço.
Para monitoramento de desempenho, o LLM Mesh monitora o desempenho de ida e volta para serviços e provedores LLM para que as equipes possam diagnosticar problemas e selecionar o serviço ideal com base nas necessidades do aplicativo e nos SLAs. Além disso, o cache de respostas a consultas comuns evita a necessidade de regenerar a resposta, oferecendo economia de custos e aumento de desempenho.
Geração aumentada de recuperação e bancos de dados de vetores
O LLM Mesh inclui componentes e recursos de desenvolvimento de aplicativos padrão para uso em vários aplicativos como, por exemplo, o Retrieval Augmented Generation (RAG) . O RAG está se tornando uma forma padrão de infundir o conhecimento interno da empresa nas respostas de um LLM.
O aplicativo funciona indexando seu conhecimento interno (como catálogo de produtos, base de conhecimento de suporte, etc.) em uma estrutura de dados especializada chamada Vector Store. No momento da consulta, o Vector Store busca os conteúdos mais adequados com base na consulta do usuário e os injeta no prompt enviado ao LLM, garantindo a geração de uma resposta que leve em consideração o seu conhecimento interno. O LLM Mesh fornece integração com Vector Stores e implementa todo o padrão RAG sem necessidade de código.
A Dataiku é pioneira em LLM Mesh e sua plataforma fornece as funcionalidades necessárias para construir e implantar aplicativos de IA generativa nos ambientes corporativos mais rigorosos. É importante ressaltar que esses novos recursos específicos do LLM não são complementos da plataforma, eles estão profundamente integrados aos principais recursos que a Dataiku construiu na última década: conexões e segurança de dados, preparação de dados e pipelines, ciência de dados e Machine Learning, operações e governança.
Vale lembrar que na plataforma Dataiku tudo está acessível em um ambiente colaborativo e de vários perfis, oferecendo interfaces de usuário com ou sem código, bem como uma experiência de código completo para desenvolvedores.
Conclusão
O LLM Mesh, conforme explicamos acima, é a solução holística para os desafios que impedem as organizações atuais de aproveitar a IA generativa com segurança e em escala. Assim como a Dataiku criou o padrão comum para análise e ML na empresa, a introdução do LLM Mesh se tornará o padrão para IA generativa na empresa. Como o cofundador e CEO da Dataiku, Florian Douetteau, disse há duas semanas: “Fomos construídos para este momento . Um brinde aos próximos dez anos.”
A triggo.ai é especialista em Inteligência Artificial, Machine Learning e Data Analytics. Somos pioneiros em MDS (Modern Data Stack) no Brasil e parceiros da Dataiku. Estamos prontos para ajudar a sua empresa a dar os próximos passos com as IAs generativas e com o uso de LLMs Mesh. Fale com um dos nossos especialistas!
Referência: Dataiku.com


